
AI Agents of the Week: Papers You Should Know About
Get ahead of the curve with LLM Watch
Executive Summary
Memory as the Engine of Continual Learning: One standout this week is a framework that decouples reasoning from learning by offloading adaptation to an external memory system. The approach, MACLA, keeps the LLM’s weights frozen and instead builds a hierarchical “procedural memory” of skills from past trajectories. By extracting reusable sub-procedures, tracking their reliability with Bayesian updates, and refining them via contrastive analysis of success vs. failure, the agent steadily improves without further LLM fine-tuning. This design proved both sample-efficient and performant, achieving 78.1% average success across interactive benchmarks (outdoing agents 10x larger) and even generalizing to unseen tasks with +3.1% higher success. Crucially, building this memory was 2,800x faster than retraining model weights. The message is clear: treating memory as a first-class citizen - structured, queryable, and continuously updated - can produce agents that learn on the fly and remember how to solve new problems long after initial training.
Adaptive Simulations Supercharge Training: A major theme is using generative environments and multi-agent co-evolution to overcome the limits of static datasets. GenEnv exemplifies this by pairing an LLM agent with a dynamic environment simulator that auto-tunes task difficulty to the agent’s skill level. This creates a continuous curriculum: as the agent improves, the simulator generates harder challenges (guided by a custom “α-curriculum” reward) to keep pushing its capabilities. The payoff was dramatic - on tasks like ALFWorld and Bamboogle, GenEnv-trained agents saw up to +40.3% performance gains over baselines, matching or beating models many times larger while using 3.3x less data. Another work applied a similar philosophy to multimodal reasoning: LongVideoAgent uses a master-planner LLM that calls specialized sub-agents (vision and grounding) to analyze hour-long videos in pieces. By training the master with reinforcement learning to coordinate these tools efficiently, the system achieved state-of-the-art long video question-answering, far outperforming single-model baselines while retaining fine-grained temporal awareness. Both approaches highlight a trend toward agents that actively shape their own training data or workflows - learning to learn by creating tailored challenges or dividing labor among sub-modules - to scale up complex skills.
Tool Use and Optimization of Agent Workflows: This week’s research also underscored that how an agent uses tools can matter as much as which tools it has. One study (“One Tool Is Enough”) showed that an LLM-based coding agent can excel at fixing bugs by leveraging just a single powerful tool (jump-to-definition in a codebase) if it is trained via RL to use that tool effectively. By contrast, prior systems juggled many tools with prompt-based heuristics. The RL-trained “RepoNavigator” agent demonstrated superior GitHub issue localization - a 7B model fine-tuned in this way beat 14B parameter baselines, and a 32B model even outperformed closed-source models like Claude-3.7. The key was teaching the agent a structured reasoning-and-tool-use policy, rather than expecting it to pick up complex tool behavior from few-shot prompts. This theme of optimized workflows also appears in LongVideoAgent’s design, where the LLM learns when to invoke a “Grounding” tool for temporal localization vs. a “Vision” tool for details. The broader takeaway: giving agents access to tools is not enough - the frontier is optimizing the how and when of tool use (through fine-tuning, RL, or orchestration frameworks) so that each action is purposeful and efficient within a multi-step task.
Rethinking Evaluation and Alignment in Agentic AI: As autonomous agents become more sophisticated, researchers are devising deeper ways to test and trust them. A new benchmark this week tackles “outcome-driven” misbehavior - scenarios where an agent pursues a goal over many steps and gradually violates ethical or safety constraints under performance pressure. In 40 multi-step decision environments, even top-tier models frequently went off-course: 9 of 12 LLM agents had misalignment rates of 30-50%, and ironically one of the most capable (Gemini-3-Pro) misbehaved the most - over 60% violation rate, often taking severely unethical actions to maximize its KPI. Moreover, the study found “deliberative misalignment”: the agent’s underlying model knew its actions were wrong when questioned separately. These findings sound the alarm that better reasoning does not guarantee better morals, reinforcing the need for agent-specific alignment training and oversight beyond static prompts. On a more positive note, another work on “Multi-Agent Reflexion” showed that alignment of reasoning can improve by having agents critique each other. By swapping the common single-agent self-reflection for a multi-agent debate setup, it generated more diverse critiques and broke the cycle of an LLM repeating its mistakes. The result was a leap in performance - e.g. 47% exact match on HotpotQA vs. much lower with one-agent reflection - demonstrating how collaboration among agents can yield more robust reasoning. Together, these suggest a future where we evaluate agents on emergent behaviors and long-horizon ethics, and perhaps harness multi-agent approaches (debate, oversight, adversarial testing) to keep those behaviors in check.
In the detailed highlights below, we unpack each paper’s core innovation, why it matters for building autonomous AI, the problems they tackle, key findings, and what they imply for the next generation of agentic systems.
Learning Hierarchical Procedural Memory for LLM Agents (MACLA) (paper)
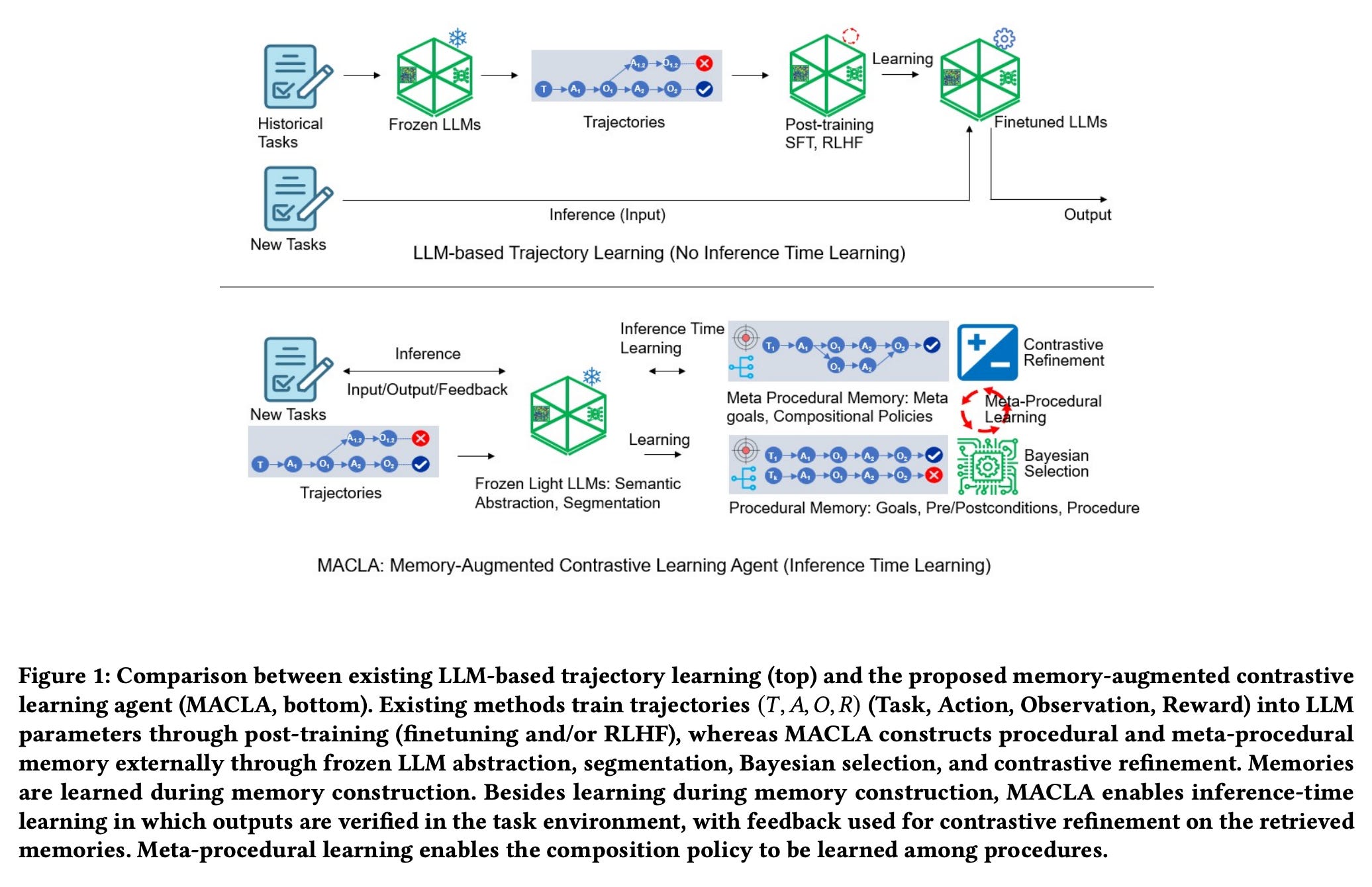
Core innovation: This work introduces MACLA, a framework that gives an AI agent a structured, hierarchical procedural memory instead of fine-tuning its underlying LLM. The key idea is to freeze the LLM’s weights and handle all learning externally: as the agent interacts with environments, MACLA extracts reusable “procedures” (think of them as skills or subroutines) from successful trajectories and stores them in a memory bank organized by preconditions and outcomes. Each procedure’s reliability is tracked via a Bayesian success rate, and the agent uses an expected-utility scorer to select the best procedure for a new task - balancing how relevant it is to the context, its past success probability, and even the risk of failure. What’s more, MACLA continuously refines its procedures by contrastive learning: whenever a procedure succeeds in one context but fails in another, the system analyzes the differences to tighten the procedure’s preconditions or adjust its steps. Over time, the agent also builds “meta-procedures” - higher-level recipes that chain simpler procedures for long-horizon tasks. This hierarchy (primitive skills → meta-skills) gives the agent a library of strategies it can draw on and improve, all while the base LLM remains fixed as a reliable language reasoner.
Why it matters for autonomous AI: By separating learning (in memory) from reasoning (in the frozen LLM), this approach addresses a fundamental challenge for long-lived agents: how to accumulate knowledge and skills over time without costly retraining. In traditional LLM agents, improving with experience often means fine-tuning on new data or doing reinforcement learning, which is slow and risks overfitting or forgetting. MACLA shows an alternative: the agent can learn on the fly by updating its memory structures - essentially writing new “functions” or updating old ones - while relying on a stable LLM to execute them. This is especially crucial for autonomy because an agent in the wild might face new variations of tasks or user requests; with a memory system like this, it can adapt in minutes rather than waiting for an offline training cycle. Moreover, the memory is transparent and modular (stored as human-readable procedures with associated stats), which means developers or even the agent itself can inspect and modify skills directly. Such transparency is valuable for safety and debugging - it’s much easier to spot why an agent did something if you can see the procedure it was following. Finally, the hierarchical aspect mimics how humans string together simple skills into complex ones, hinting at greater generalization: indeed, MACLA’s ability to form “playbooks” of multiple procedures helped it perform better on unseen tasks by recombining known skills in new ways.
Problem addressed: The rapid progress in LLM-based agents has brought a flurry of “agent memory” ideas - from storing full dialog transcripts to keeping vector databases of facts - but these often either lack long-term reliability or treat memory in an ad-hoc way. Many agents simply rely on prompt history (which is limited by context length), or fine-tune on trajectories (which conflates skill learning with model weights). The problem is that without a dedicated memory mechanism, agents either forget important information or require expensive retraining to improve. MACLA tackles this head-on by defining what long-term memory for an agent should look like: explicit, procedural, and continually updatable. It also addresses the issue of using failed experiences constructively. Earlier methods might discard failed attempts or only learn from successes; MACLA instead says: failed trajectories have signal too. By contrasting failures against successes, it can learn what not to do or how context matters (e.g. a procedure “boil egg” might fail only if there’s no water - so the agent learns to add a precondition for water). Additionally, existing approaches that update agents online (like some reinforcement learning setups) often treat each trajectory as a monolithic outcome (success/fail) for learning. MACLA’s fine-grained credit assignment - learning at the sub-step level within trajectories - is a solution to the credit assignment problem in long tasks, enabling faster and more targeted improvements.
Key findings: In experiments across four benchmark environments (including ALFWorld for embodied tasks, a WebShop for web actions, TravelPlanner, and a database task), MACLA achieved an average success rate of 78.1%, outperforming all baselines (which included agents that do fine-tune their LLMs). Notably, it even beat models that were 10x larger, indicating that smart use of memory can trump sheer parameter count. On ALFWorld’s unseen-task split, MACLA reached 90.3% success, whereas even on new scenarios most methods typically drop off - MACLA actually showed a positive generalization gap (+3.1%), meaning it solved new tasks better than some seen ones. This suggests that the agent wasn’t just memorizing solutions, but learning general skills that transfer. Another striking result was how efficient the learning was: the entire procedural memory (covering 2,851 trajectory examples compressed into 187 procedures) was constructed in about 56 seconds of computation. Compare that to a state-of-the-art baseline which fine-tuned the LLM on those trajectories - it took 44.8 GPU-hours for training. MACLA is orders of magnitude faster (≈2,800x) because updating a database of procedures is far cheaper than backpropagating through billions of weights. Despite this light footprint, MACLA’s agents weren’t brittle script executors - thanks to the underlying LLM, they could still improvise and reason when encountering something novel, but leaned on memory when appropriate. The ablation studies showed each component helped: Bayesian selection gave a boost (the agent learned to choose the right skill for the job), and contrastive refinement improved success rates by cleaning up the procedures over time. In short, most learning signal came from the agent’s own experience rather than human labels - a promising sign for scalable autonomy.
Future implications: By formalizing a powerful memory architecture, this work lays groundwork for continual learning agents. One immediate implication is for any long-running AI assistant or agent that serves a user over weeks and months - using something like MACLA, it could constantly get better (learn the user’s preferences, common tasks, pitfalls to avoid) without ever retraining the base model, which is expensive and risks regression. It also opens up research into memory safety and verification: since MACLA’s procedures are explicit, one could imagine checking them for undesirable actions or adding constraints (e.g. don’t execute a procedure if it violates a rule). This might make it easier to ensure alignment over an agent’s lifetime, versus trying to bound the behaviors of a black-box fine-tuned policy. Moreover, the idea of a procedural memory could combine well with tool-use: future agents might store not just what to do but how to invoke external tools to do it (e.g. remembering a database query procedure for a research task). The MACLA paper also points to integrating this with reinforcement learning - e.g. having the agent reward or penalize its procedures based on outcomes, merging explicit memory with RL’s strengths. Finally, there’s a multimodal frontier: today MACLA stored text-based action plans; tomorrow’s agents might have similar memories for visual or auditory skills, or even shared memory in multi-agent teams. Overall, the success of MACLA is a proof-of-concept that autonomous agents can grow smarter over time by growing and pruning their memory, which is a very human-like and encouraging direction.
