
AI Agents of the Week: Papers You Should Know About
Get ahead of the curve with LLM Watch
Executive Summary
This week’s research spans long-horizon planning, tool use and search, memory and self-reflection mechanisms, multi-agent collaboration, domain-specific agents, and new evaluation frameworks. Clear themes are emerging:
Hybrid approaches are combining large language models (LLMs) with structured systems (symbolic planners, simulators, cognitive architectures) to overcome the limits of stand-alone LLM agents. Researchers are tackling the challenge of agents that can plan over long horizons, dynamically manage context and memory, and learn or self-correct as they act.
There’s also a push toward domain specialization - recognizing that generalized LLMs sometimes falter in specialized or safety-critical environments - and toward more meaningful evaluations that capture an agent’s interactive and adaptive behavior, not just single-step task accuracy.
Agents that can autonomously reason in open worlds, collaborate with humans and other agents, adapt to new tasks, and safely operate in real-world domains.
Below, we dive into the week’s top papers, each illustrating a key piece of this evolving autonomous agent puzzle.
SPIRAL: Guided Self-Reflective Planning with LLMs and Search (paper)
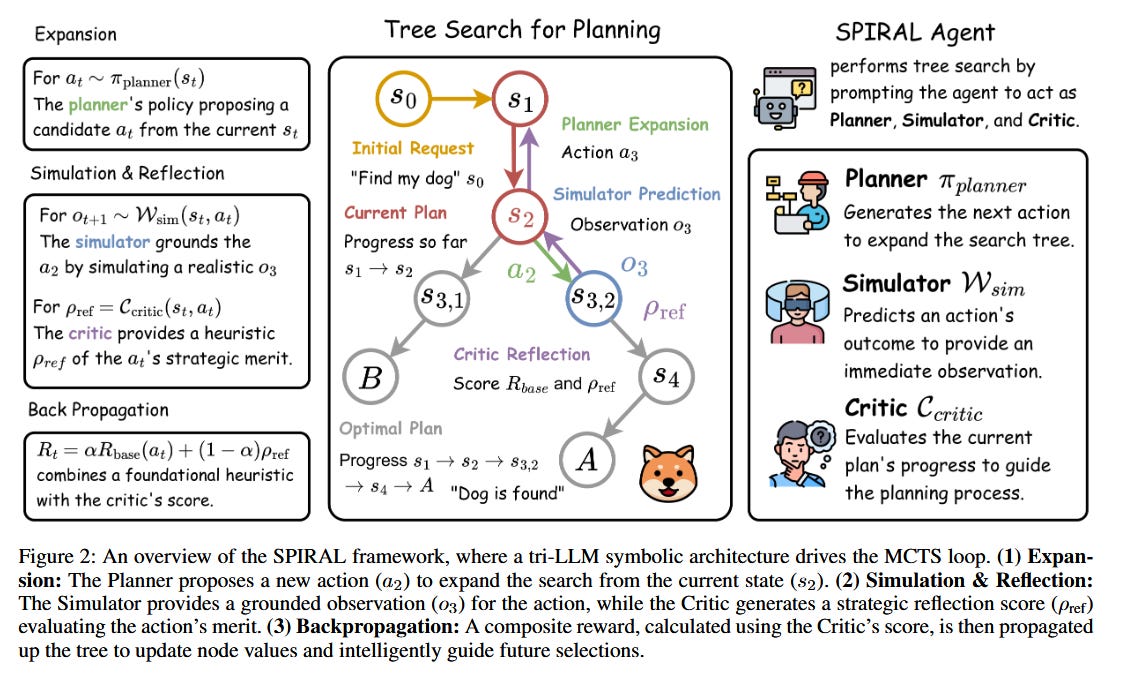
SPIRAL: Symbolic LLM Planning via Grounded and Reflective Search - Complex, long-horizon tasks often stump today’s LLM-based agents because a single chain-of-thought can get derailed by early mistakes. SPIRAL introduces a powerful solution by embedding an LLM into a Monte Carlo Tree Search (MCTS) loop, augmented with multiple agent personas. Instead of a single model doing all reasoning, SPIRAL defines three specialized roles: a Planner LLM that proposes possible next steps, a Simulator LLM that “grounds” these steps by predicting their outcomes, and a Critic LLM that reflects on the outcomes to provide dense feedback signals. This effectively turns search from brute-force trial-and-error into a guided, self-correcting reasoning process driven by the LLM’s semantic knowledge and reflective critiques. On planning benchmarks (like daily task APIs), SPIRAL dramatically outperforms standard chain-of-thought and even other search-based agents - e.g. achieving 83.6% success on the DailyLifeAPIs task, which is 16+ points higher than the best previous search method. Notably, it attains this with fewer tokens, indicating efficiency gains along with robustness. The innovation here is how self-reflection and simulation are folded into the agent’s decision loop: the Planner’s creativity is checked by the Simulator’s grounding in “what would actually happen,” and the Critic’s reflective rewards ensure the agent learns from near-misses. The result is an agent that can recover from errors, explore alternatives, and converge on correct solutions more reliably than a single-pass LLM. SPIRAL exemplifies the trend of multi-agent (or multi-module) architectures for a single agent’s mind, showing that structured cooperation between specialized LLMs can yield more trustworthy and effective autonomy. It’s a promising path toward agents that don’t just generate plans - they debug and improve their plans on the fly, much like a human brainstorming, simulating outcomes, and self-correcting to achieve a goal.
Web World Models: Persistent Sandbox Environments for LLM Agents (paper/code)
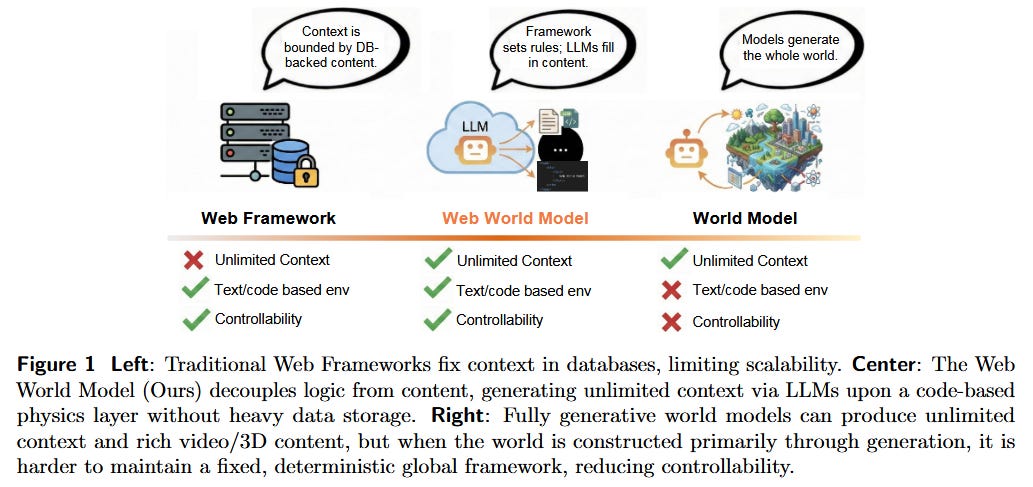
Web World Models (WWM) - One way to enable long-horizon autonomy is to give agents a persistent world to live and learn in. This paper introduces Web World Models, a framework that sits between rigid simulator environments and unconstrained imagination. In WWM, the environment’s state and “physics” are implemented with standard web technology (think of a web app maintaining an internal state), ensuring consistency and logical rules, while the LLM agent generates the narrative details and high-level decisions within that structured world. This hybrid approach means the agent can roam in an “unlimited” environment (the web content can be expansive or even procedurally generated) but with the grounding of real code-defined rules. The authors built a suite of example WWMs: from an infinite travel atlas grounded in real geography to fictional galaxies and game-like simulations. Across these, they distilled design principles: separating the world’s hard rules from the agent’s imagination, representing state as typed web data (so the agent can query and act through a defined interface), and using deterministic generation where appropriate to allow open-ended yet reproducible exploration. The big implication is that the existing web/browser stack could serve as a scalable substrate for agent environments, effectively turning the web into a sandbox where agents can act, remember, and learn continually. For autonomous agents research, WWM offers a practical path to create long-lived agents: rather than being limited by a fixed context window, an agent in a WWM can accumulate knowledge in its world (the state persists beyond a single prompt) and face consequences for its actions, enabling study of memory management, skill acquisition, and truly long-horizon tasks. It’s an exciting intersection of web engineering and AI - hinting at a future where any webpage or app could plug into an agent’s “brain” as its external world.
