
AI Agents of the Week: Papers You Should Know About
Get ahead of the curve with LLM Watch
Executive Summary
This week, researchers are tackling long-horizon and open-ended tasks with new frameworks that enable agents to plan further ahead and adapt on the fly.
Several papers focus on tool use and evolution, allowing agents to integrate new tools or even invent their own programs when needed, rather than being limited to static capabilities. We also see advances in multi-agent collaboration and coordination, with language-model-based agents learning to communicate and negotiate under real-world constraints.
A recurring theme is memory and self-reflection – from agents that maintain and refine long-term memory, to ones that decide when to trust their own outputs versus external feedback. Additionally, there’s growing attention on efficient, safe reasoning: one formal framework explicitly bounds an agent’s resource use, and another demonstrates lifelong self-improvement without human intervention.
In summary, the field is rapidly addressing practical challenges (like tool integration, evaluation, and resource limits) while pushing toward more adaptive, resilient agent architectures that can learn from experience and handle dynamic environments.
DR-Arena: Automated Evaluation for “Deep Research” Agents (paper)
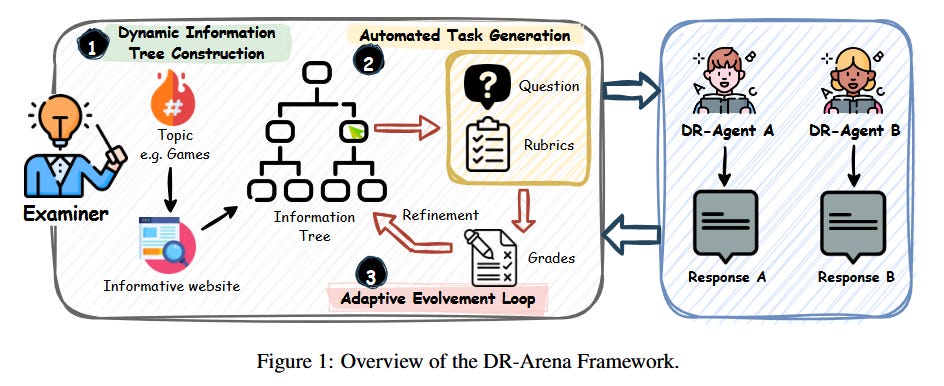
Evaluating autonomous “research assistant” agents remains challenging. This paper introduces DR-Arena, an automated framework to rigorously benchmark large language model (LLM) agents on complex research tasks. The key idea is to generate dynamic Information Trees from up-to-date web content, ensuring test questions reflect the current world state instead of static datasets. An automated Examiner module poses increasingly difficult, structured tasks that probe two orthogonal capabilities: deep reasoning (in-depth analysis) and wide coverage (breadth of information). The evaluation is adaptive – a state-machine controller escalates task complexity (demanding deeper deduction or broader synthesis) until the agent’s performance breaks, revealing its capability limits. In experiments with six advanced LLM-based agents, DR-Arena’s scores achieved a Spearman correlation of 0.94 with human preference rankings on a known benchmark. This is a striking result: the automated framework aligns nearly perfectly with human judgment, without manual intervention. Why it matters: Reliable, up-to-date evaluation is a bottleneck for autonomous agents that continuously learn or use live information. DR-Arena provides a way to stress-test research agents in real time and push them to failure, yielding more robust assessments of their reasoning abilities. Ultimately, this could accelerate agent development by replacing costly human evaluations with a high-fidelity automated arena, ensuring that as agents become more capable, our benchmarks evolve alongside them.
