
🍓 Actually Open AI: A Free o1 Alternative
And the one resource every AI Engineeer should know

In this issue:
An open o1-like model
The LLM Engineer Handbook
NVIDIA mixing attention with state spaces

1. Marco-o1: Towards Open Reasoning Models for Open-Ended Solutions
Watching: Marco-o1 (paper/code)

What problem does it solve? While large language models (LLMs) have shown impressive performance in various domains, their ability to generalize to open-ended problem-solving tasks remains a challenge. OpenAI's o1 model has sparked interest in large reasoning models (LRMs) that can handle disciplines with standard answers, such as mathematics, physics, and coding. However, the question remains whether these models can effectively tackle broader domains where clear standards are absent and rewards are difficult to quantify.
How does it solve the problem? Marco-o1 addresses the limitations of current LRMs by integrating several key components. Firstly, it employs Chain-of-Thought (CoT) fine-tuning to enhance the model's reasoning capabilities. Secondly, Monte Carlo Tree Search (MCTS) is used to expand the solution space and explore different action granularities, allowing for finer search resolutions and improved accuracy. Additionally, Marco-o1 incorporates reflection mechanisms and innovative reasoning strategies specifically designed for complex real-world problem-solving tasks. These components work together to enable Marco-o1 to handle open-ended resolutions and translate complex slang expressions effectively.
What's next? To further improve Marco-o1's performance, the researchers plan to refine the reward signal for MCTS using Outcome Reward Modeling (ORM) and Process Reward Modeling (PRM). These techniques aim to reduce randomness and enhance the model's decision-making processes. Moreover, reinforcement learning techniques are being explored to fine-tune Marco-o1's decision-making capabilities, ultimately enabling it to tackle even more complex real-world tasks. As research in this area progresses, we can expect to see LRMs like Marco-o1 becoming increasingly adept at handling open-ended problem-solving scenarios across a wide range of domains.
2. LLM Engineer Handbook
Watching: LLM Learning Resources (repo)
What problem does it solve? The field of Large Language Models (LLMs) is rapidly evolving and it can be challenging for developers and researchers to keep up with the latest advancements. While it's now easier than ever to build an LLM demo, there's still a significant gap between a proof-of-concept and a production-grade application. This repository aims to bridge that gap by providing a curated list of resources covering the entire LLM lifecycle, from model training and fine-tuning to deployment and maintenance.
How does it solve the problem? The repository organizes resources into several key categories. First, it tracks all the latest libraries, frameworks, and tools in the LLM ecosystem. Second, it provides learning resources covering the entire LLM lifecycle, from model selection and prompt engineering to serving and LLMOps. Third, it offers insights and explanations to help developers better understand how LLMs work under the hood. Fourth, it highlights key social accounts and communities where developers can connect with other practitioners and stay up-to-date on the latest trends. Finally, it provides guidance on how developers can contribute to the repository and help make it even more valuable for the community.
What's next? As the field of LLMs continues to evolve, it will be important to keep this repository up-to-date with the latest advancements and best practices. This may involve adding new categories of resources as new challenges and opportunities emerge, as well as continually curating the existing content to ensure it remains relevant and accurate. Ultimately, the goal should be to create a comprehensive and authoritative resource that empowers developers to build cutting-edge LLM applications with confidence.
3. Hymba: A Hybrid-head Architecture for Small Language Models
Watching: Hymba (paper/models)
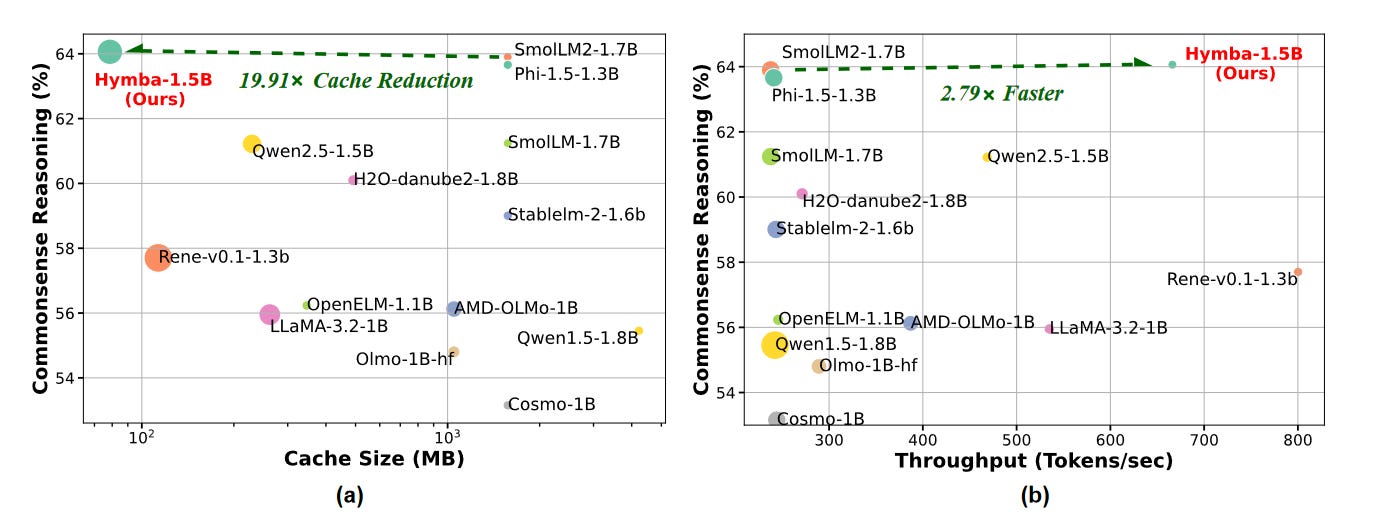
What problem does it solve? While Large Language Models (LLMs) have achieved remarkable performance across various natural language tasks, their computational complexity and memory requirements pose significant challenges for efficient deployment and real-time inference. This is particularly problematic for applications that require low-latency responses or have limited computational resources. Hymba aims to address these limitations by proposing a novel architecture that combines the strengths of transformer attention mechanisms and state space models (SSMs) to create more efficient and compact language models.
How does it solve the problem? Hymba introduces a hybrid-head parallel architecture that leverages both transformer attention heads and SSM heads. The attention heads provide high-resolution recall, enabling the model to capture fine-grained details and dependencies within the input sequence. On the other hand, the SSM heads efficiently summarize the context, allowing the model to capture long-range dependencies without the need for expensive full attention computation. Additionally, Hymba incorporates learnable meta tokens that are prepended to the prompts, serving as a condensed representation of critical information. This alleviates the "forced-to-attend" burden associated with attention mechanisms, as the model can directly access relevant information stored in the meta tokens. Furthermore, Hymba employs cross-layer key-value (KV) sharing and partial sliding window attention to optimize the model's efficiency and reduce the cache size.
What's next? The hybrid-head parallel architecture, combining attention and SSM heads, provides a promising direction for future research in model design. It would be interesting to explore the scalability of this approach to larger model sizes and investigate its applicability to a wider range of natural language tasks. Additionally, the learnable meta tokens introduced in Hymba could be further studied to understand their potential for capturing and storing critical information in a more compact and accessible manner.
Papers of the Week:
The Dawn of GUI Agent: A Preliminary Case Study with Claude 3.5 Computer Use
SageAttention2 Technical Report: Accurate 4 Bit Attention for Plug-and-play Inference Acceleration
Do I Know This Entity? Knowledge Awareness and Hallucinations in Language Models
MindForge: Empowering Embodied Agents with Theory of Mind for Lifelong Collaborative Learning