
📐 A New Neural Architecture (Again)
And how prompting might fundamentally change retrieval

In this issue:
The return of a controversial neural network architecture
NVIDIA releasing open frontier models
Prompting a revolution in retrieval

Want to learn from some of the best practitioners in the world?
MLOps/GenAI World is all about solving real-world problems and sharing genuine experiences with production-grade AI systems.
Join leaders and engineers from Microsoft, Huggingface, BlackRock and many more with your personal 15% discount.
1. Kolmogorov-Arnold Transformer
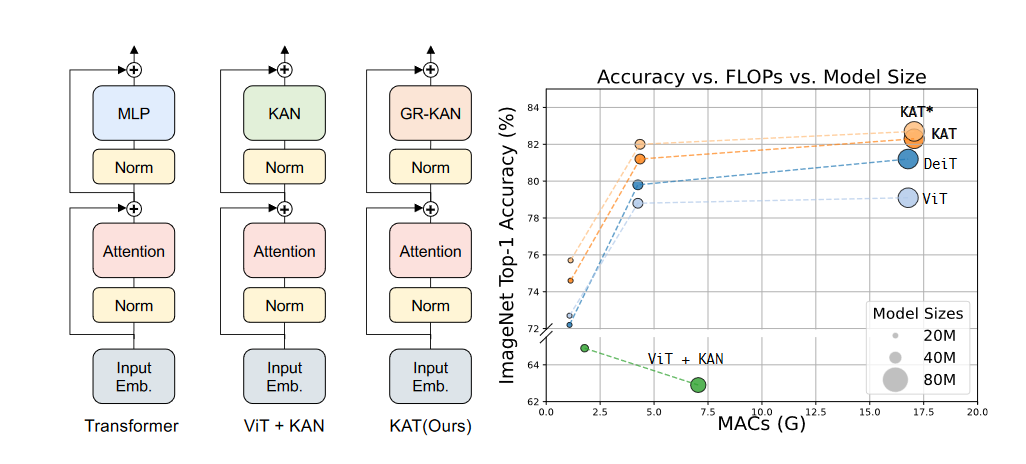
What problem does it solve? The Transformer architecture has been the backbone of most state-of-the-art language models. However, the multi-layer perceptron (MLP) layers used in Transformers for mixing information between channels have limitations in terms of expressiveness and performance. The Kolmogorov-Arnold Transformer (KAT) aims to address these limitations by replacing the MLP layers with Kolmogorov-Arnold Network (KAN) layers, which have the potential to enhance the model's capabilities.
How does it solve the problem? To effectively integrate KANs into Transformers, the authors propose three key solutions. Firstly, they replace the B-spline functions used in KANs with rational functions, which are more compatible with modern GPUs and lead to faster computations when implemented in CUDA. Secondly, they introduce the concept of Group KAN, where activation weights are shared among a group of neurons to reduce computational load without compromising performance. Lastly, they employ a variance-preserving initialization technique for the activation weights to ensure that the activation variance remains consistent across layers, which is crucial for achieving convergence in deep neural networks.
What's next? The Kolmogorov-Arnold Transformer (KAT) presents a promising direction for improving the expressiveness and performance of Transformer-based models. By addressing the challenges associated with integrating KANs into Transformers, such as optimizing base functions for parallel computing, reducing parameter and computation inefficiency, and carefully initializing weights, KAT has the potential to outperform traditional MLP-based Transformers. Further research could explore the application of KAT to various natural language processing tasks and investigate its scalability to larger model sizes.
2. NVLM: Open Frontier-Class Multimodal LLMs
Watching: NVLM (paper/project)

What problem does it solve? Multimodal AI has been a hot topic in recent months with the release of models like GPT-4 from OpenAI, PaLM 2 from Google and Kosmos-1 from Anthropic. While these models are pushing the boundaries of what's possible in terms of reasoning across different modalities like text, images and even video, they are not open source. NVLM 1.0 is trying to change that by releasing a family of open source multimodal models that are competitive with these proprietary ones.
How does it solve the problem? NVLM 1.0 is building on top of previous open source work like LLaVA and Flamingo. The authors are proposing a novel architecture that tries to combine the strengths of decoder-only models like LLaVA and cross-attention-based models like Flamingo. They are also introducing a new 1-D tile-tagging design for dynamic high-resolution images which helps with multimodal reasoning and OCR-related tasks. But maybe most importantly, they are meticulously curating their training data, focusing on quality and diversity over quantity.
What's next? It's great to see more and more open source initiatives in the multimodal AI space. NVLM 1.0 is not only providing competitive models but also detailed information on their training data and methodology which is crucial for reproducibility and further research. It will be interesting to see how these models perform in real-world applications and if they can keep up with the rapid progress of proprietary models. The fact that NVLM 1.0 is showing improved text-only performance after multimodal training is also a promising sign for the potential of multimodal pretraining to enhance general language understanding.
3. Promptriever: Instruction-Trained Retrievers Can Be Prompted Like Language Models
Watching: Promptriever (paper)

What problem does it solve? Retrieval models are a key component in many applications, such as search engines and question-answering systems. However, traditional retrieval models lack the ability to understand and follow imperative commands or instructions. This limitation hinders their usability and adaptability in scenarios where users need to provide specific instructions or preferences for the retrieval process.
How does it solve the problem? Promptriever addresses this issue by introducing an instruction-tuned retrieval model. By curating a large-scale instance-level instruction training set from MS MARCO, Promptriever learns to understand and follow imperative commands. This enables users to interact with the retrieval model using natural language instructions, providing a more intuitive and flexible interface. Promptriever demonstrates strong performance on standard retrieval tasks while also exhibiting the ability to adapt its behavior based on the provided instructions.
What's next? By aligning prompting techniques with retrieval models, researchers can explore more advanced and user-centric retrieval systems. This could lead to the development of retrieval models that can handle more complex queries, better understand user preferences, and provide more personalized results. Additionally, the release of the instruction training set from MS MARCO can facilitate further research and benchmarking in this area.
Papers of the Week:
Agents in Software Engineering: Survey, Landscape, and Vision
SGFormer: Single-Layer Graph Transformers with Approximation-Free Linear Complexity
Exploring Graph Structure Comprehension Ability of Multimodal Large Language Models: Case Studies
RetrievalAttention: Accelerating Long-Context LLM Inference via Vector Retrieval
Trustworthiness in Retrieval-Augmented Generation Systems: A Survey
Reasoning Graph Enhanced Exemplars Retrieval for In-Context Learning / code
To CoT or not to CoT? Chain-of-thought helps mainly on math and symbolic reasoning
MMSearch: Benchmarking the Potential of Large Models as Multi-modal Search Engines