
9 Papers You Should Know About
Get ahead of the curve with LLM Watch
Welcome, Watchers! This week in LLM Watch, we delve into cutting-edge advances in large language models (LLMs) and their applications across AI, vision, science, and more. The highlights include:
An open-source evolutionary framework (ShinkaEvolve) that uses LLMs to generate new algorithms with unprecedented sample-efficiency.
A self-supervised RL paradigm (RLPT) letting LLMs learn reasoning from raw pre-training data, yielding up to 8-point gains on benchmarks.
Evidence that generative video models can solve 62 tasks zero-shot – from segmentation to physical reasoning – hinting at general-purpose vision models.
A “think-before-you-speak” training (RLMT) that forces LLMs to generate chain-of-thought, achieving state-of-the-art chat performance with just 7K training prompts.
A novel way to train continuous “soft” tokens for reasoning via RL, surpassing discrete chain-of-thought on math tasks while preserving base model skills.
And many more! Feel free to check out the glossary below or jump straight to the paper section.
.jpg")
Members of LLM Watch are invited to participate in the 6th MLOps World | GenAI Global Summit in Austin Texas. Feat. OpenAI, HuggingFace, and 60+ sessions.
Subscribers can join remotely, for free here.
Also if you'd like to join (in-person) for practical workshops, use cases, food, drink and parties across Austin - use this code for 150$ off!
Quick Glossary
Reinforcement Learning on Pre-Training data (RLPT): A training paradigm where an LLM treats its pre-training corpus as an environment to explore next-token “trajectories” and learn from them via RL, without any human-provided rewards. This approach bypasses the need for human annotation (unlike RLHF) by deriving rewards directly from predicting actual next segments. The result is that models can self-improve their reasoning skills using only raw text data.
Reinforcement Learning with Verifiable Rewards (RLVR): An RL approach that uses programmatic or rule-based rewards in domains like math or code where correctness can be checked automatically. It boosts reasoning in those verifiable domains, but on open-ended tasks (creative writing, planning, etc.) its benefits are limited.
RL with Model-rewarded Thinking (RLMT): A new RL pipeline requiring the model to generate a lengthy chain-of-thought before giving its final answer. A separate reward model (like those from RLHF) then scores these reasoning traces, and the base model is optimized to produce better thought-out answers. This “think then respond” strategy leads to stronger general chat abilities than standard RLHF, as shown by large gains on multiple benchmarks.
Thinking Augmented Pre-Training (TPT): A method to inject “thinking trajectories” (step-by-step reasoning chains) into text training data to enhance an LLM’s data efficiency. By augmenting text with auto-generated rationales, TPT effectively triples the value of each token, helping models learn complex concepts with far fewer examples (e.g. a 3B model saw >10% higher scores on reasoning tasks).
Continuous Chain-of-Thought (“Soft” tokens): Using continuous embeddings instead of discrete tokens for an LLM’s intermediate reasoning process. Unlike normal word tokens, these soft tokens can represent a superposition of many reasoning paths. Recent work shows that an LLM can be trained via RL to utilize hundreds of continuous CoT tokens without any discrete guide. The result is richer reasoning: models match discrete CoT accuracy in one try and exceed it when allowed multiple tries, thanks to more diverse solution paths.
ShinkaEvolve: Towards Open-Ended And Sample-Efficient Program Evolution
Watching: ShinkaEvolve (paper/code)
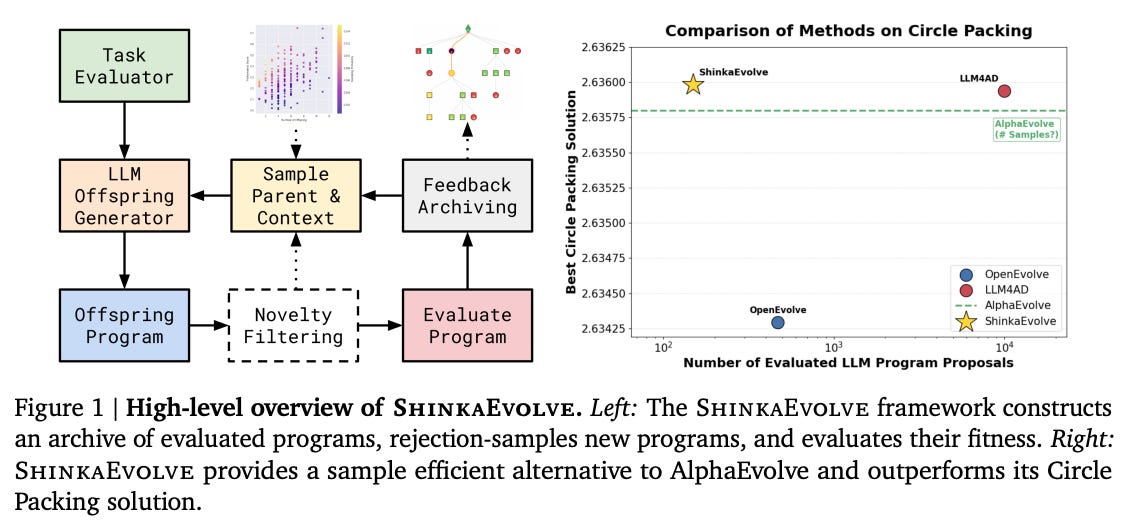
What problem does it solve? Modern approaches that use LLMs to evolve code (e.g. for solving optimization or programming tasks) are extremely sample-inefficient, often needing thousands of trials to find a good solution. They’re also usually closed-source, hindering broad use. This makes LLM-driven discovery too costly and inaccessible for most researchers.
How does it solve the problem? ShinkaEvolve is an open-source framework that treats an LLM as a “mutation operator” to iteratively improve programs. It introduces three key innovations to slash the number of trials needed: (1) a balanced parent selection strategy that smartly trades off exploring new ideas vs. exploiting known good solutions, (2) novelty-based rejection sampling to filter out redundant or uncreative mutations (using embedding similarity and an LLM judge of novelty), and (3) a bandit algorithm to pick the best LLM from an ensemble for each generation. Together these ensure ShinkaEvolve spends compute only on the most promising program variants, avoiding the “random search” inefficiencies of prior methods.
What are the key findings? By making program evolution dramatically more efficient, ShinkaEvolve achieves success on a wide range of problems that were previously impractical. It discovered a new state-of-the-art solution to a classic 26-circle packing problem using only 150 samples – a “massive leap in efficiency” over past approaches. It also evolved a high-performing multi-agent strategy for math contests (AIME benchmark) in just 75 generations, outperforming strong human-designed baselines. In competitive programming, ShinkaEvolve’s improvements to an AtCoder contest agent were so significant that, on one problem, the evolved solution would have placed 2nd in the competition. Moreover, ShinkaEvolve even discovered a better way to train large Mixture-of-Expert LLMs – finding a new load-balancing loss that beat the DeepMind “Global LBL” baseline with +1.73% higher task scores and 5.8% less wasted capacity. These results show that broad “open-ended” discovery is now feasible at modest cost, unlocking an AI-powered co-pilot for scientists and engineers to autonomously search for novel solutions.
What’s next? This work suggests that many hard problems in science and engineering (from designing algorithms to discovering new optimizations) can be tackled by an LLM-driven evolutionary search in an efficient way. By open-sourcing ShinkaEvolve and even providing a Web UI for visualizing the evolutionary runs, the authors aim to democratize this approach. Future research will likely build on this by applying the method to new domains (e.g. evolving circuits, scientific formulas, or hyperparameters) and by incorporating even more advanced LLMs as they appear. In the long run, techniques like ShinkaEvolve could serve as automated “research assistants”, rapidly iterating through ideas and improvements that humans might overlook, all while using far fewer trials than brute force methods.
Video Models are Zero-Shot Learners and Reasoners
Watching: Veo 3 Video Model (paper/project)
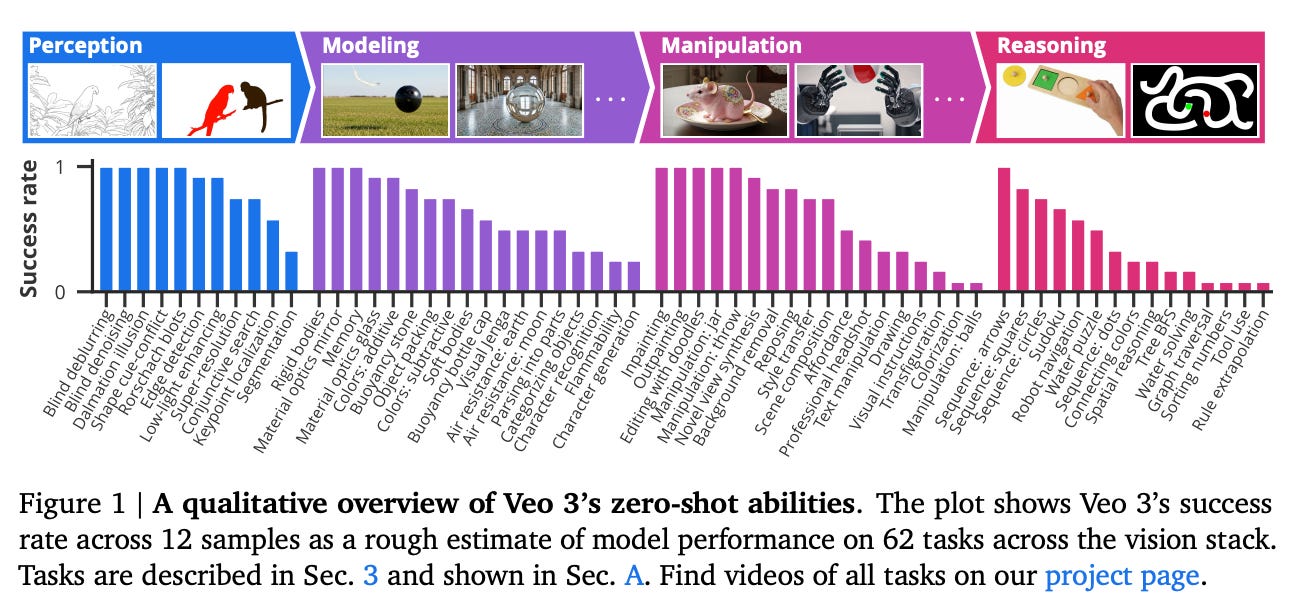
What problem does it solve? Large language models surprised the world by displaying emergent zero-shot abilities – solving tasks they were never explicitly trained on – thanks to scale and diverse training data. This paper asks: can video generative models analogously become general problem-solvers in the visual domain? Prior video models were usually evaluated on narrow tasks or short benchmarks, leaving it unclear if they possess broad, human-like visual reasoning capabilities.
How does it solve the problem? The authors take Veo 3, a state-of-the-art generative video model, and systematically test it on a broad battery of 62 tasks spanning classic vision, physical reasoning, and even tool use. Importantly, they use a minimalist prompt-based approach: they feed the model an initial video frame or image plus a textual instruction (like “show the edges” or “solve this maze”), then let it generate an 8-second video as the “answer”. No fine-tuning or task-specific training – this is true zero-shot evaluation. To isolate the video model’s own reasoning, they ensure that a standalone LLM (Google Gemini 2.5) given just the image can’t solve the task, so any success comes from the video generation process itself. Essentially, they’re prompting the video model to think visually step-by-step (through the frames it generates) and then checking if the result shows the correct solution.
What are the key findings? Remarkably, Veo 3 exhibits a wide range of emergent skills without any task-specific optimization. It can segment objects, detect edges, do image editing (e.g. remove an object), infer physical properties (like an object’s mass by how it moves), recognize object affordances (how an object can be used), and even simulate tool use – all zero-shot. These perceptual and manipulation abilities enable higher-level visual reasoning: for example, Veo 3 solves mazes and symmetry puzzles by internally “imagining” the solution path in the video it generates. Quantitatively, across 62 diverse tasks tested, the model achieved high success rates on both low-level vision tasks (e.g. 92% on edge detection, 100% on image de-noising) and more cognitive tasks like physical reasoning. Veo 3 also showed clear improvement over its predecessor (Veo 2) on these tasks, indicating these capabilities scaled up with model/version improvements. All this suggests that video models, given sufficient scale and training, are following a similar trajectory to LLMs – becoming general-purpose “vision foundation models” that can be prompted to tackle myriad tasks beyond their training.
What’s next? This work implies that future AI may rely on unified multimodal foundation models: just as one LLM can handle many language tasks, one video model could handle many vision tasks. A key next step is to refine prompting techniques and benchmarks for these video models – analogous to how prompt engineering and standardized evals drove progress in LLMs. Researchers will also explore whether introducing explicit reasoning steps (e.g. text-based planning combined with video generation) can further enhance performance on complex tasks. On the application side, a powerful zero-shot video reasoner could be transformative: imagine robot assistants that reason visually through consequences before acting, or scientific models that simulate physics experiments on the fly. Ultimately, the convergence of capabilities in language and video models hints at a broader trend of generalist AI systems, and understanding how and why these abilities emerge (e.g. what in the training data or architecture leads to tool-use simulation?) is an exciting question for fundamental research.
Reinforcement Learning on Pre-Training Data (RLPT)
Watching: RLPT (paper)
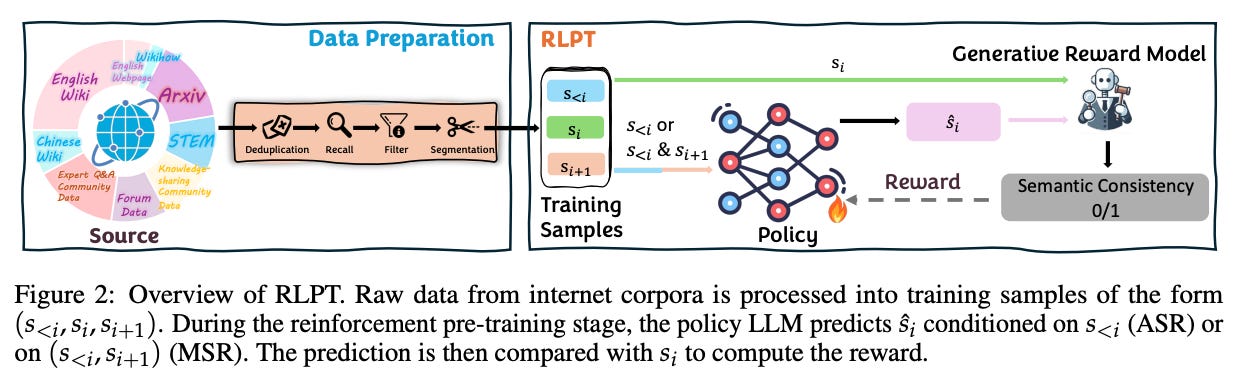
What problem does it solve? Scaling up LLMs by feeding them more text has hit a bottleneck: we can increase compute easily, but high-quality text data is finite. Moreover, simply predicting the next token (standard training) might not teach models to reason through complex dependencies, because the model isn’t encouraged to explore beyond the distribution of its data. Prior methods like RLHF add some signal but require costly human feedback. In short, we need a way for LLMs to learn more from the data they already have, especially to acquire reasoning skills, without an army of human annotators.
How does it solve the problem? RLPT turns an LLM’s original pre-training corpus into an interactive training playground for reinforcement learning. It does this by defining a next-segment prediction task as a sequential decision problem. Concretely, the model reads some text context and then generates the next chunk of text; a separate Generative Reward Model (or an implicit ground-truth signal) gives a reward based on how well that generation matches the actual continuation in the corpus. The LLM thus treats the authentic text as demonstrations of optimal behavior, exploring different continuations and getting feedback without any human labels. Importantly, these rewards come directly from the pre-training data (e.g. matching observed text), eliminating reliance on hand-crafted rewards or human preference models. In effect, RLPT allows the model to autonomously practice reasoning on unlabeled data: it might deviate from the immediate next token if it finds a longer-term path that yields higher reward (better overall coherence with the text). This training-time exploration is carefully scaled up to billions of tokens so the policy can discover richer reasoning strategies across a broad domain of text.
What are the key findings? When applied to a 4-billion parameter base LLM (Qwen3-4B), RLPT dramatically improved its performance on multiple challenging benchmarks. For instance, it boosted the model’s score on MMLU (a knowledge exam) by +3.0 points and on MMLU-Pro (an advanced version) by +5.1. Gains were even larger on math and logic-heavy tasks: +8.1 on a QA benchmark (GPQA-Diamond) and +6.6 on AIME24 (math competition problems). These are absolute improvements over an already strong base model, achieved without any human-labeled data or task-specific finetuning. Moreover, scaling studies indicate that as you give RLPT more compute (more training steps), the model keeps improving – hinting that even bigger gains are possible with larger budgets. The authors also note that RLPT-trained models exhibit stronger generalizable reasoning: they extend the model’s ability to handle complex prompts and improve performance of existing verification-based RL (RLVR) when used together. In summary, RLPT offers a promising path to break the data scarcity barrier by extracting much more signal from the text we already have, effectively turning passive pre-training data into an active learning experience.
What’s next? RLPT’s success with self-supervised rewards paves the way for more hybrid training regimes. Future LLMs might alternate between passive reading and active exploration of texts, games, or simulations, all without human intervention. One immediate follow-up is to apply RLPT to even larger models (e.g. 34B, 70B) and more domains – does it similarly boost reasoning for code, or multimodal data? There’s also room to refine the reward modeling: the current next-segment reward might be enhanced by incorporating logical consistency or factual accuracy metrics derived automatically from the text. If those can be folded into RLPT, models could self-police their coherence and truthfulness. In the big picture, RLPT is part of a broader trend of LMs learning to think ahead (plan tokens) rather than just mimic, so we can expect research that combines this with techniques like tree-of-thought or tool-use during training. All of this moves toward LLMs that not only absorb internet text, but actively practice and generalize from it – much like a student solving problems to better understand the material.
Soft Tokens, Hard Truths
Watching: Continuous CoT (paper)
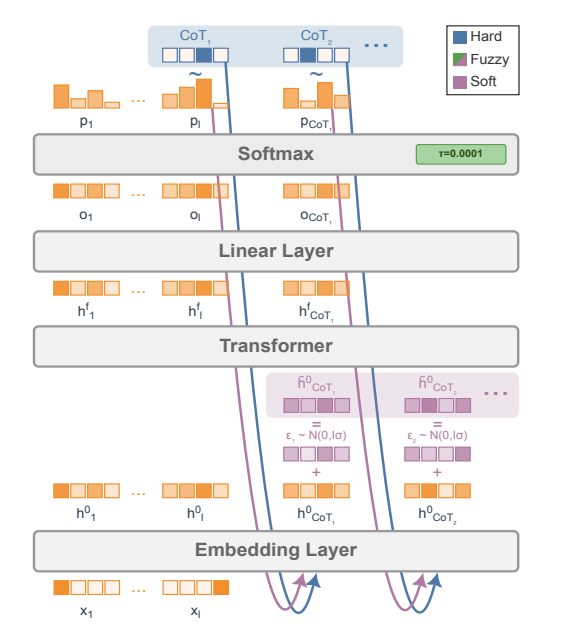
What problem does it solve? Chain-of-thought prompting (having an LLM generate step-by-step reasoning) improves performance, but it uses discrete natural language tokens, which might not be the most efficient internal representation for reasoning. Continuous tokens – essentially vectors that aren’t constrained to the discrete vocabulary – have theoretically much greater expressiveness and can encode multiple ideas at once. In theory, a model that “thinks” in a continuous space could explore many reasoning paths in parallel (a superposition) instead of one-by-one. The problem is that actually training an LLM to use continuous, non-language tokens in its reasoning process is very hard: past attempts either only injected continuous tokens at inference (without training on them), or required distilling from known human-written reasoning chains, which is cumbersome and limited to short chains. No one had shown a scalable way for a model to learn a useful continuous chain-of-thought (CoT) from scratch.
How does it solve the problem? This work presents the first successful method to train continuous CoTs via reinforcement learning, without relying on any ground-truth human rationales. The idea is to let the model generate “soft” tokens (continuous embeddings) between the prompt and the final answer, and use a reward signal to optimize their use. Specifically, they add a small amount of noise to the input embeddings as a form of exploration, and then use policy-gradient RL to reward the model if its final answer is correct. Essentially, the model is trying to invent its own internal language (the continuous tokens and what they represent) that leads to better problem-solving outcomes. By avoiding any supervised training on discrete chains, there’s no human bias limiting what these soft tokens can do. Notably, the approach adds minimal computational overhead, so they can afford to let the model use hundreds of continuous tokens in the reasoning phase during training – orders of magnitude more “thought capacity” than prior distillation methods allowed.
What are the key findings? On math reasoning benchmarks, LLMs trained with this continuous CoT technique achieved performance on par with or better than those using traditional discrete chain-of-thoughts. For example, on GSM8K math problems, a Llama-7B model with continuous CoT matched the accuracy of the same model with standard (discrete) CoT when considering the single best answer (pass@1). However, when allowed to sample multiple answers (pass@32), the continuous-CoT model outperformed the discrete CoT model, indicating it found a more diverse set of reasoning paths leading to correct answers. This demonstrates one big advantage of continuous tokens – they can capture a richer variety of solutions, which pays off when you can try multiple outputs. Interestingly, the authors found the best strategy was a hybrid: train with continuous tokens, but use discrete tokens at inference. In other words, let the model think in vectors during training to gain the benefits, but at deployment it can just output normal text rationale if needed – the training still improved its latent reasoning ability. Moreover, continuous CoT training caused less interference with the model’s other capabilities: the model retained its accuracy on unrelated tasks better than a model trained on discrete CoT, meaning this approach is a “softer” touch that avoids overfitting to the reasoning data. All told, this is a proof-of-concept that LLMs can develop their own non-human-readable thought vectors that yield real problem-solving gains.
What’s next? Training LLMs to think in vectors opens up many research directions. One immediate question is how to interpret or visualize these learned continuous tokens – do they correspond to human-like concepts, or something entirely alien yet effective? There’s also potential to extend continuous CoT to multimodal reasoning (imagine an LLM that internally represents an image with “soft visual tokens” while reasoning). The success with reinforcement learning here may inspire using other reward signals to shape continuous thoughts, such as logical consistency checks or factual verification as rewards to produce even more reliable reasoning. In practice, we might see hybrid systems where models do heavy-duty reasoning in continuous space and then distill the outcome into a concise explanation for humans. The fact that the “soft” model’s final answers can be executed in standard form means adoption is easy – e.g. a math tutor LLM could silently use continuous CoT to figure out a tough proof, then present the answer in neat natural language. Overall, this work lays groundwork for more efficient, diverse reasoning in LLMs, potentially overcoming some limits of discrete token thinking that chain-of-thought still had.
Thinking Augmented Pre-Training (TPT)
Watching: TPT (paper)
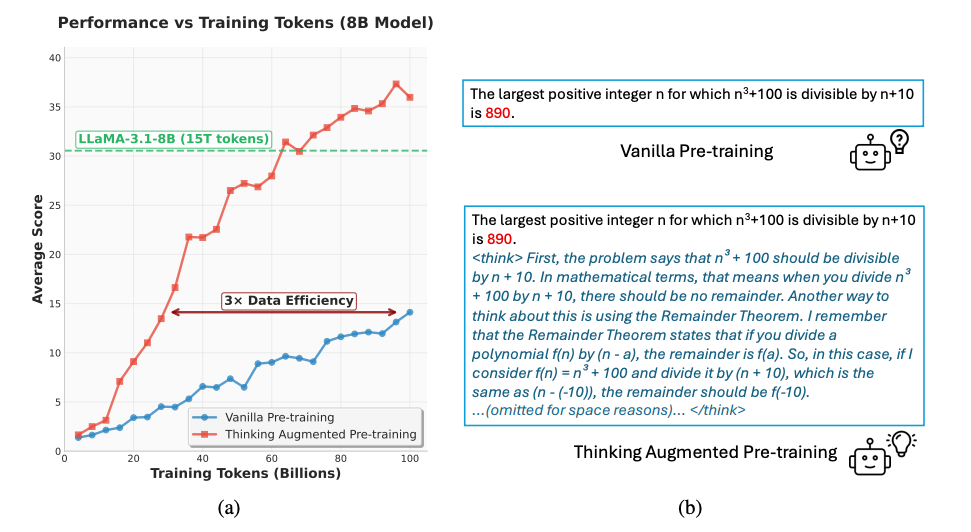
What problem does it solve? High-quality training data for LLMs is limited, and some complex patterns in language are hard for a model to learn just by next-word prediction. Often, the reason behind a statement or the chain of logic connecting sentences is not explicitly in the text – it’s implicit or assumed. This makes certain “high-quality tokens” (like a step in a math proof, or a hidden logical connection in code) effectively very difficult to learn. The result is data inefficiency: even with billions of words, the model might still struggle with multi-step reasoning or harder comprehension, because it never sees the intermediate thinking. The challenge addressed here is how to make better use of the data by making the hidden reasoning explicit.
How does it solve the problem? TPT tackles this by augmenting the pre-training corpus with “thinking trajectories” – essentially generating step-by-step reasoning or explanatory content and inserting it alongside the original text. For example, if the original text says “The student solved the problem and got the answer 42,” a thinking trajectory might include the steps the student took to solve it. These trajectories are created automatically (likely using prompting on a strong LLM or heuristics) for a wide range of tasks and domains, and then interwoven with the original data for training. By doing so, TPT increases the effective data volume (since we add new tokens) and, crucially, makes complex tokens easier to learn by breaking down their underlying rationale. The method is “universal” – they apply it in various settings: pre-training from scratch on limited data, augmenting an already large corpus, or even mid-training an open-source model to further improve it. In each case, the presence of explicit reasoning chains helps the model generalize better from the same amount of original text.
What are the key findings? Across model sizes and training setups, TPT delivered substantial performance boosts, indicating a huge win in data efficiency. Notably, the authors report that TPT improves the data efficiency of pre-training by a factor of 3. In practical terms, this means an LLM trained on 100B tokens with TPT augmentation could achieve comparable or better results than a model trained on 300B tokens of standard data. For a 3B-parameter model, they saw over +10% improvement on multiple challenging reasoning benchmarks just by incorporating thinking trajectories during training. Larger models and different families (they tested both decoder-only and others) all benefited, suggesting TPT is robust. Importantly, these gains aren’t limited to niche tasks – the paper notes improvements “across various model sizes and families” on general NLP benchmarks. This implies the method injects a broad understanding or skill, rather than overfitting to specific problems. By explicitly including reasoning, the model is better at tasks requiring step-by-step logic, math word problems, complex QA, etc., while also not hurting performance on standard language tasks. Essentially, TPT shows that more thinking per token is as good as (or better than) just more tokens – a significant result for efficient training.
What’s next? TPT’s approach aligns with a growing trend of making LLM training more intentional or structured. Future research might explore automating the generation of thinking trajectories even further – perhaps using one LLM to generate and another to verify or refine the reasoning before using it for training. There’s also the possibility of extending this to other modalities: for instance, augmenting image captions with chains of visual reasoning, or code with chains of program logic, to similarly boost learning. In terms of immediate practical impact, companies training models could adopt TPT to reach high performance with less data (or get better results with the same data), which is economically appealing. One could also combine TPT with RLPT (from paper #4 above): first augment data with reasoning (TPT), then let the model explore that data via RL – potentially a very powerful combo for self-improving AI. Finally, TPT prompts us to consider the quality of data over quantity; by focusing on the “hidden” information in text and making it explicit, we might uncover new levels of LLM capability without needing an order-of-magnitude more data.
SimpleFold: Folding Proteins is Simpler than You Think
Watching: SimpleFold (paper/code)
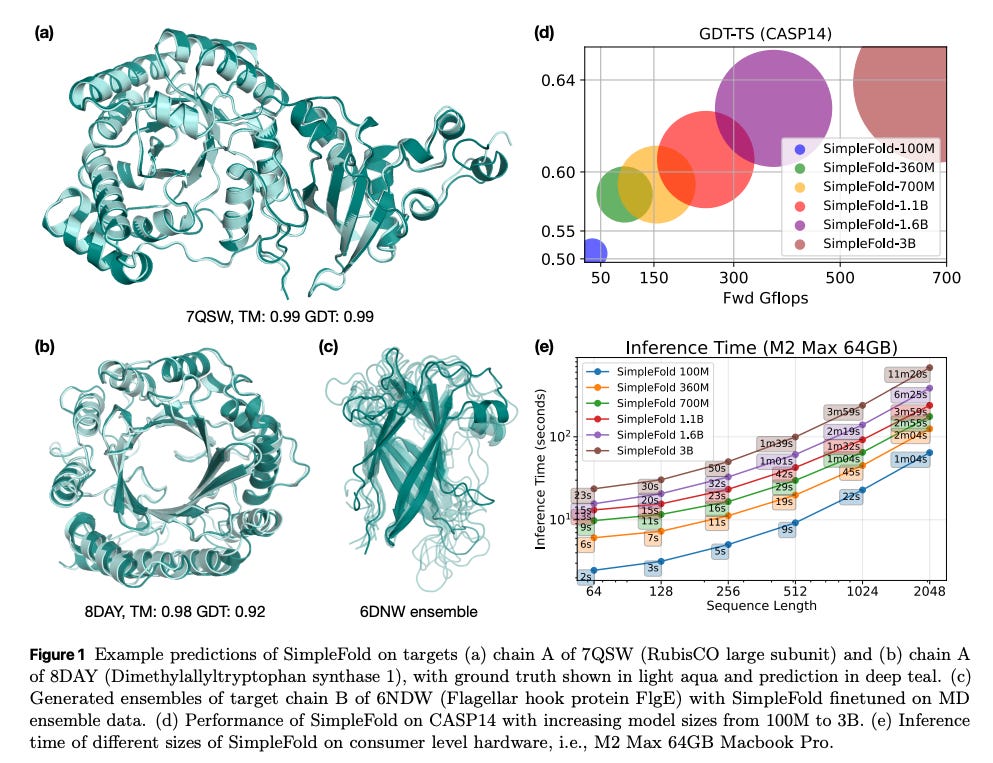
What problem does it solve? Recent breakthroughs in protein folding (like AlphaFold) rely on very complex model architectures tailored to capturing protein-specific geometry – e.g. triangle attention modules, pairwise distance matrices, multiple bespoke loss terms, etc. While extremely successful, these specialized designs are computationally heavy and depart significantly from the “standard” architectures used in NLP or vision. This raises an intriguing question: do we really need all that domain-specific complexity, or could a much simpler, more generic model fold proteins with similar accuracy? In other words, is protein folding fundamentally simpler than current models make it seem?
How does it solve the problem? SimpleFold is a bold attempt to strip protein folding models down to basics. It uses a general-purpose Transformer architecture with no special protein-specific blocks. Instead of the customary tricks (triangular updates, separate 2D pair representation of amino acids, etc.), it relies on standard self-attention layers (augmented by some adaptive gating layers) and trains them end-to-end on protein structure data. The key insight is to cast protein folding as a generative modeling problem: SimpleFold is trained with a flow-matching objective, which is related to diffusion models or normalizing flows, guiding it to incrementally refine a random structure into the correct folded structure. They include a minor additional loss term to encourage correct structural predictions (so it’s not purely generic, but almost). They then scale this model up to 3 billion parameters and train on ~9 million protein structures (including a large set of distilled/predicted ones plus experimentally solved ones). Essentially, SimpleFold treats protein coordinates like a data sequence and learns to “flow” them into the correct shape using a Transformer, without explicitly encoding protein biophysics knowledge.
What are the key findings? SimpleFold-3B’s performance rivals state-of-the-art specialized models on standard protein folding benchmarks. It achieves competitive accuracy in predicting 3D structures, showing that a vanilla Transformer can indeed learn the complex dependencies needed for folding. Moreover, SimpleFold exhibits strengths where deterministic models often struggle: because it’s generative, it can naturally produce an ensemble of different probable structures. The paper notes strong performance in ensemble prediction – it can sample multiple foldings and capture alternative conformations, which is typically hard for models like AlphaFold that give one answer. Another practical benefit is efficiency: with its simpler architecture, SimpleFold is easier to deploy and runs faster on standard hardware (no specialized ops needed). The success of SimpleFold effectively challenges the notion that we need highly domain-specific designs for protein folding. It opens the door to using more off-the-shelf AI components in scientific domains. In short, the paper demonstrates that much of protein folding can be learned by a generic sequence model, which is a surprising and encouraging finding.
What’s next? SimpleFold’s approach could spark a re-evaluation of how we design models for scientific problems. If a plain Transformer works for protein structures, perhaps other tasks (molecular property prediction, DNA folding, etc.) can also shift to simpler architectures with the right training approach. Future work might integrate SimpleFold with downstream tasks – for example, coupling it with drug binding prediction, where its generative ensemble ability could explore multiple protein conformations. The use of a flow-matching objective also hints at connections to diffusion models; one could imagine a diffusion-based folding model that further improves accuracy or captures dynamics by simulating folding as a time series. Additionally, because SimpleFold is closer to standard AI models, it could potentially benefit from transfer learning: e.g., initialize with a language model’s weights or vice versa, to inject some cross-domain knowledge (there’s early speculation that some language features help in protein sequences). The big takeaway is that simplicity can sometimes achieve the same ends as complexity – a valuable lesson that might lead researchers to try more “minimalist” baselines in domains dominated by hand-engineered networks. As this trend continues, we may see a convergence where the same core model type underpins progress in both science (protein folding, chemistry) and general AI, differing mostly in training data rather than architecture.
LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
Watching: LLMs4All Survey (paper)
What problem does it solve? The impact of LLMs is not confined to computer science – they are rapidly permeating every academic field from history to biology. However, knowledge of how to effectively use LLMs in these diverse disciplines is scattered. Researchers in, say, law or chemistry might not be up-to-date on the latest LLM techniques relevant to their field. This paper addresses the need for a comprehensive survey that brings together the state-of-the-art LLM applications, opportunities, and challenges across the full spectrum of academic research areas.
How does it solve the problem? LLMs4All serves as an extensive review and guide, spanning three broad domains of academia and detailing how LLMs are being applied in each. The authors categorize fields into: (1) Arts, Humanities, and Law (like history, philosophy, political science, architecture, legal studies), (2) Economics and Business (finance, marketing, management, etc.), and (3) Science and Engineering (mathematics, physics, biology, chemistry, earth sciences, computer science, etc.). For each area, the survey outlines current use cases of LLMs in research and practice – for instance, assisting historical text analysis, aiding legal document summarization, generating hypotheses in scientific research – with examples of state-of-the-art models or systems in that domain. It also discusses how LLM capabilities (like text generation, reasoning, coding, multilingual understanding) are tailored or fine-tuned to meet discipline-specific needs. Beyond applications, the review addresses key limitations and challenges in each field: data privacy in medicine, factual accuracy in history, ethical concerns in law (like bias or fairness), etc., as well as open research questions and future directions for integrating LLMs. In effect, LLMs4All acts as a bridge between the AI frontier and domain experts, summarizing “what LLM can do for X field” in one place.
What are the key findings? The survey’s primary contribution is qualitative synthesis, but it offers important insights and observations. One overarching finding is that virtually no discipline is untouched – from using GPT-4 to draft legal contracts to employing generative models for experimental design in chemistry, academia is experiencing a wave of LLM-driven innovation. However, the review notes that the maturity varies: some fields (like computer science and law) already have numerous LLM applications, while others (say, philosophy or the arts) are still exploring initial use cases. Common challenges emerge across disciplines, such as concerns over LLMs generating plausible-sounding but incorrect information (hallucinations) which could mislead non-expert users in fields like medicine or finance. The paper highlights that interdisciplinary collaboration is key – e.g. combining an LLM with domain-specific knowledge bases or models yields better results (as seen in tools for scientific discovery that use LLMs plus chemistry rules). A positive finding is that LLMs are acting as a democratizing force in research: they enable individuals without advanced technical training to leverage AI for their domain problems (for example, historians using GPT to translate and summarize ancient texts). The survey also compiles best practices and ethical guidelines that are emerging as communities grapple with responsible LLM use (such as disclosure policies in academic writing if AI was used). Altogether, LLMs4All provides a roadmap for researchers in each field to understand the current landscape and to identify how they might use LLMs in their own work.
Why does it matter? As generative AI becomes as fundamental as data analysis, having a clear view of its role in each discipline is crucial. This survey will help educators and policymakers as well – for instance, university departments can refer to it when updating curricula to include AI literacy relevant to their field. By documenting limitations and future directions, the paper also points AI researchers towards important unsolved problems (like improving factuality for scientific Q&A, or aligning LLMs with legal reasoning). One likely outcome is that the survey will spur cross-disciplinary collaborations: a biologist reading about LLM use in chemistry might team up with AI experts to apply similar techniques to biology. It also emphasizes that despite the hype, current LLMs have serious shortcomings in specialized domains – thus tempering expectations and encouraging more research on reliability, which is a recurring theme. In summary, LLMs4All matters because it catalogues the transformation happening at the intersection of AI and every other field, ensuring that knowledge is shared broadly rather than siloed, and helping to steer the next phase of research where AI truly becomes an every-discipline tool.
Language Models that Think, Chat Better

What problem does it solve? Reinforcement learning from human feedback (RLHF) has become a standard way to finetune chat LLMs to be more helpful and safe. However, RLHF optimizes only the final answer the model gives, not the reasoning process behind it – the model might produce some hidden chain-of-thought internally, but the reward model only judges the end response. This can lead to answers that sound good but aren’t deeply reasoned. There’s another approach, RL with verifiable rewards (RLVR), which forces the model to output checkable working (like a math proof or code test) and rewards correctness. RLVR yields better reasoning but only works in domains with objective checks. The open problem addressed here is: Can we get the generality of RLHF while also encouraging the model to actually think through problems?
How does it solve the problem? The solution is a new training paradigm called RLMT (Reinforcement Learning with Model-rewarded Thinking). In RLMT, during training the model is required to generate a long chain-of-thought (CoT) before its final answer. This CoT might be a detailed outline, step-by-step reasoning, or intermediate “thoughts.” A reward model (the same kind used in RLHF, pretrained on human preference data) then scores not just the final answer but the combination of the CoT and the answer. Essentially, the model is rewarded for producing helpful reasoning that leads to a good answer. They implement this by using diverse real-world prompts (open-ended tasks like writing an essay, planning a meal, answering a complex question) and apply policy gradient methods (PPO, DPO, etc.) to optimize the LLM’s policy to output better thought+answer pairs. They do this across 40 separate training runs on two base models (Llama-3.1 8B and Qwen-7B) under different settings to ensure the approach is robust. Importantly, they also explore training from scratch with RLMT (R1-Zero) – meaning they take a base model with no supervised fine-tuning and directly apply RLMT, to see if they can skip the usual instruction-tuning phase.
What are the key findings? RLMT-trained models consistently outperform standard RLHF-trained models on a wide array of evaluations. For instance, on three different open-ended chat benchmarks (AlpacaEval2, WildBench, Arena Hard), the RLMT models scored 3–7 points higher than equivalent RLHF models – a sizable jump in quality. They also saw general ability improvements, like +1–3 point gains on creative writing tasks and knowledge quizzes. Perhaps most impressively, their best RLMT-tuned 8B model actually surpassed the performance of GPT-4 (open variant) on those chat benchmarks and creative tasks, and even approached Claude 2’s level on one benchmark. This is a remarkable result given the model is an order of magnitude smaller than GPT-4. Another striking finding: an 8B Llama trained with only 7,000 RLMT prompts (no supervised fine-tune at all) outperformed the official Llama-3.1-8B that had been instruction-tuned on 25 million examples. In other words, a few thousand carefully chosen scenarios with think-before-answer optimization beat a massive conventional training – that speaks to how powerfully efficient RLMT is. Qualitatively, the authors observed the RLMT models produce more structured and thoughtful responses (e.g. making lists, reasoning out loud, considering alternatives) and fewer failure modes like going off-topic. The results strongly suggest that rewarding the thinking process leads to measurably better chat performance than rewarding final answers alone.
What’s next? This work may prompt a paradigm shift in how we train conversational agents. Rather than treating chain-of-thought as just an optional byproduct, it might become standard to explicitly train LLMs to articulate their reasoning. Future directions include combining RLMT with human-in-the-loop: e.g., having human feedback not only on answers but on intermediate thoughts to further refine the reward model for reasoning quality (beyond what the existing preference model can do). Also, applying RLMT to larger models (the paper did 8B; doing this at 34B or 70B could yield even more powerful models, potentially surpassing even larger closed models in some areas). Another consideration is real-world deployment: RLMT models, by explaining more, might be more interpretable, which is a boon for safety – but it also means they might divulge their “thoughts” even when not prompted to, which could be tuned as needed. Finally, this research calls for understanding why RLMT is so effective: does the reward model indirectly favor certain structures in CoT that align better with human preferences, or does the act of generating a longer context help the model avoid mistakes? Answering these questions could further improve training. All in all, Language Models that think truly do chat better, and we can expect the next generation of AI assistants to be much more explicit in their reasoning as a result of techniques like this.
SciReasoner: Laying the Scientific Reasoning Ground Across Disciplines
Watching: SciReasoner (paper/code)
What problem does it solve? Science-focused LLMs to date have mostly been specialists – models fine-tuned for a particular domain (like chemistry, or a math theorem solver). Real scientific research, however, often spans multiple disciplines and data formats (imagine linking a biology finding to a chemistry theory, with equations and text). There is a need for a foundation model for scientific reasoning that can understand natural language questions, but also handle formulas, sequences (DNA, protein sequences), tables of properties, and more in a unified way. In short, the goal is to create an AI scientist that isn’t siloed to one field, but has a broad, cross-disciplinary reasoning ability with the various representations science uses.
How does it solve the problem? SciReasoner is built through an extensive multi-stage training process to align language with diverse scientific representations. First, it is pre-trained on a 206 billion token corpus that includes not just scientific text from many fields, but also purely symbolic sequences and mixed sequence-text data. This means it sees things like amino acid sequences, chemical SMILES strings, math equations, alongside explanatory text. After this large pre-training, they perform supervised fine-tuning on 40 million science-related instructions, covering an enormous range of tasks (the model supports 103 different scientific tasks). These tasks fall into families: (i) translating between text and scientific formats (e.g., “describe this molecule structure in words” and vice versa), (ii) extracting knowledge from text or figures, (iii) predicting properties (given a compound, predict melting point, etc.), (iv) classifying properties (e.g. classify a star as red dwarf or not from data), and (v) generating or designing sequences (like proposing a DNA sequence with certain properties). After supervised tuning, they apply an “annealed cold-start” bootstrapping to specifically teach the model long-form chain-of-thought reasoning for scientific problems. This likely involves prompting the model to generate step-by-step solutions for complex questions and using those as additional training data (gradually increasing the complexity, hence “annealed”). Finally, they use reinforcement learning with custom reward shaping for scientific reasoning. This last step probably gives the model feedback on intermediate steps (like units consistency, equation correctness, logical coherence) to firmly instill deliberate, rigorous reasoning habits. All training artifacts (model weights, instruction data, evaluation code) are released openly, making SciReasoner a community resource.
What are the key findings? SciReasoner emerges as a single model capable of handling tasks that previously would require an ensemble of separate tools. Compared to specialist models or baselines, SciReasoner shows broader instruction coverage, better cross-domain generalization, and higher fidelity in its outputs. For example, it can take a chemistry problem described in text and output a step-by-step solution with equations, or translate a genomic sequence into a likely function description – tasks bridging language and formal data – with notable accuracy. The paper indicates that training on multiple disciplines together actually led to improved transfer learning: solving tasks in one domain improved its performance in others, because it learned general scientific reasoning strategies. This cross-pollination strengthened the model’s reliability; e.g., the rigor it learned from physics equations helped it avoid errors in, say, accounting calculations. In evaluations, SciReasoner performed on par with or better than domain-specific models on many benchmarks, despite not being an expert of any single field. And on challenges that require mixing knowledge (like a question involving both biology and chemistry), it had a clear advantage. Essentially, SciReasoner lays a groundwork: it demonstrates that one model can be a competent physicist, chemist, biologist, and more at the same time, and that this union actually makes each facet stronger. This is a step toward AI that can reason across the entirety of science. The open-sourcing of the model and its data is also a major outcome – it provides the community with a powerful base to finetune further or to benchmark for scientific QA, hypothesis generation, etc., accelerating research in scientific AI.
What’s next? SciReasoner opens up a host of new possibilities. In the near term, researchers might build on it to create specialized agents – for instance, a robot scientist that uses SciReasoner to generate experiments, then executes them in a lab simulation. The training techniques (like the massive multi-format pre-training and the careful staged alignment) could be applied to other domains requiring multi-representation reasoning, such as economics (mixing text with spreadsheets and formulas) or social sciences (mixing text and statistical data). Another likely direction is scaling: SciReasoner-8B is impressive, but imagine a 70B model trained similarly – it could potentially approach expert human level in many fields. There will also be work on evaluation: the model covers 103 tasks, but how do we thoroughly verify its reasoning quality and factual accuracy in each? New interdisciplinary benchmarks may arise from this. Finally, SciReasoner’s release fosters a culture of open scientific AI – as more researchers use and improve it, we could see a virtuous cycle leading to an “AI Scientific Assistant” that any researcher can use to boost their work, much like a powerful but wide-ranging colleague who’s read every textbook. The long-term vision is an AI that can cross-pollinate insights between disciplines (say, use a physics principle to solve a biology problem), and SciReasoner is a foundational step in that direction, illustrating the value of broad training for broad thinking in AI.