
9 Papers You Should Know About
Get ahead of the curve with LLM Watch
Welcome, Watcher!
This week's highlights:
NVIDIA’s new hybrid architecture that combes Mamba and Transformers for 6x throughput gains
Synthetic data that breaks through the "data wall" and trains models 7x faster
Developer tools that reduce complex agent development from weeks to days
Reasoning systems that learn to “think” more efficiently, not just longer
Memory modules that inject domain-expertise into LLMs without retraining
Don't forget to subscribe to never miss an update again.
Quick Glossary (for the uninitiated)
Mamba-2 layer: A type of neural network layer with linear computational complexity (vs quadratic for attention), making them much faster for long sequences - like having a highway instead of city streets for data flow.
Native-resolution ViT (NaViT): A vision transformer that processes images at their original resolution rather than chopping them into fixed-size pieces - imagine reading a map without cutting it into squares first.
Pass@k: A metric measuring how often a model succeeds within k attempts - like giving a student multiple tries at a problem and checking if any are correct.
MoE (Mixture of Experts): An architecture where different "expert" sub-networks handle different inputs - like having specialist departments in a company rather than everyone doing everything.
Catastrophic forgetting: When fine-tuning a model on new data makes it forget previously learned information - like studying for a chemistry exam so hard you forget everything about history.
Policy entropy: A measure of how diverse a model's outputs are - high entropy means varied responses, low entropy means repetitive, predictable outputs.
1. NVIDIA's Nemotron Nano 2: The Mamba-Transformer hybrid that changes everything
Watching: NVIDIA Nemotron Nano 2 (paper)
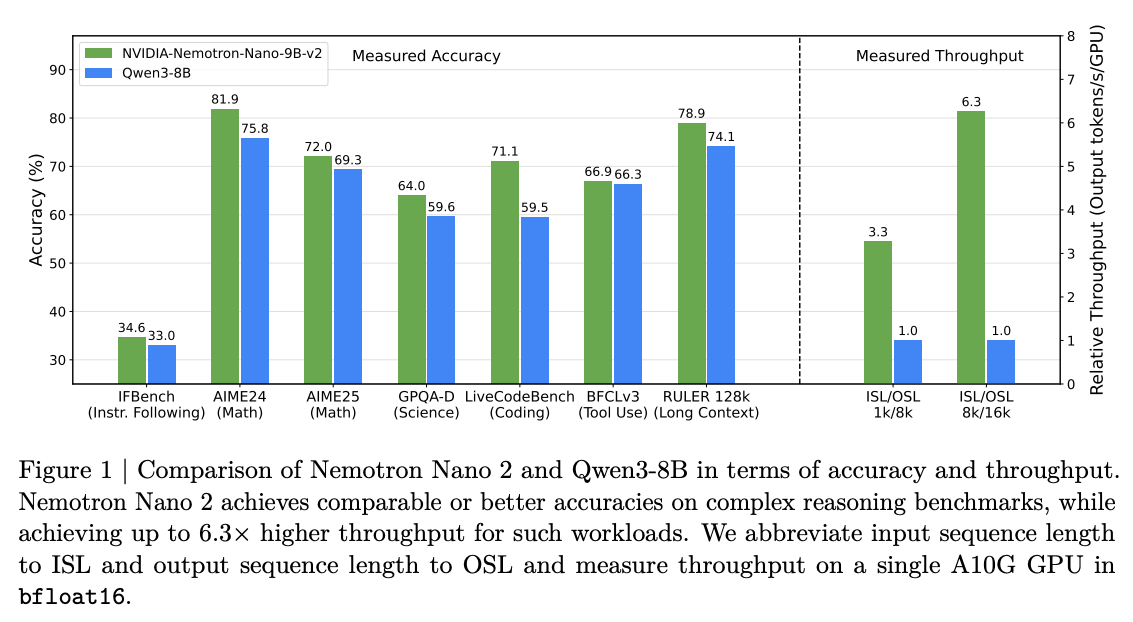
What problem does it solve? Traditional Transformers hit a computational wall with long sequences - their quadratic complexity makes them painfully slow for reasoning tasks that generate thousands of tokens. You know that frustrating wait when GPT-4 is "thinking"? That's the quadratic complexity tax you're paying.
How does it solve the problem? NVIDIA's engineers pulled off something clever: they replaced most self-attention layers with Mamba-2 layers, creating a hybrid that keeps the best of both worlds. The architecture uses just 6 attention layers alongside 28 Mamba-2 layers and 28 FFN layers. It's like replacing most of your expensive consultants with efficient specialists who work just as well for 90% of tasks.
What are the key findings? Up to 6x higher throughput than comparable models for generation-heavy tasks. A 9B parameter model that runs 128K context on a single A10G GPU (just 22GB memory). The model was trained on 20 trillion tokens, then compressed from 12B to 9B parameters while maintaining performance.
Why does it matter? With this, high-quality reasoning models can run on single GPUs instead of clusters. For anyone building AI applications, this means real-time inference for complex reasoning is now more economically viable than ever. The era of waiting 30 seconds for an AI response might be ending.
2. Ovis2.5: Native resolution vision that actually sees
Watching: Ovis2.5 (paper)
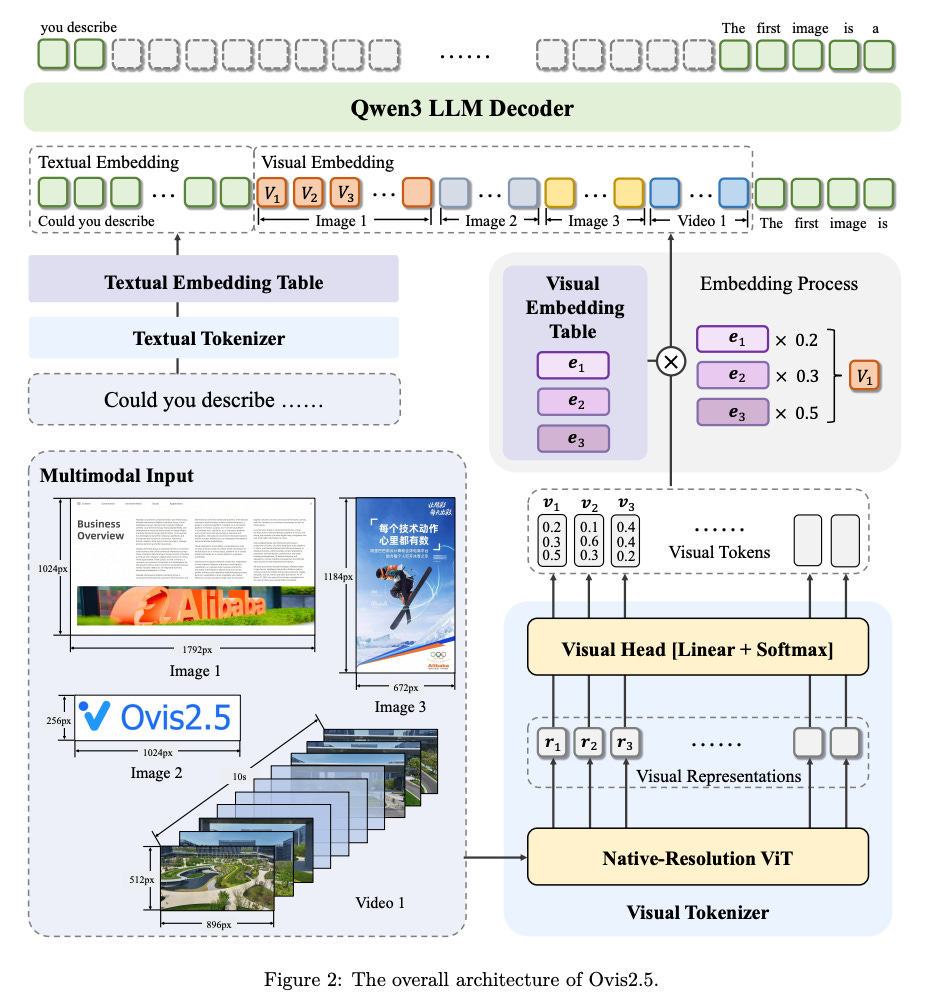
What problem does it solve? Current vision models have a dirty secret: they chop up your images into tiles, destroying global context. Try showing GPT-4V a complex chart - it might miss relationships because it literally tore the image apart to process it. Plus, most multimodal models can't really "think" about what they see - they just describe linearly.
How does it solve the problem? Ovis2.5 ditches the fixed-resolution approach entirely, using Native-resolution ViT (NaViT) that processes images at their actual resolution (448² to 1792² pixels). But here's the kicker: it adds a "thinking mode" with <think>...</think> tags where the model can reflect, self-correct, and reason about visual content before answering.
What are the key findings? The 9B version achieves 78.3 on OpenCompass, which is state-of-the-art for open-source models under 40B parameters. On OCRBench, it scores 87.9, beating GPT-4o at reading text in images. The 2B version hits 73.9, making it the best tiny multimodal model by a wide margin. Chart analysis performance is particularly impressive, finally matching human-level understanding of complex visualizations.
Why does it matter? We're entering an era where LLMs can truly "see" and reason about visual information, not just describe it. For businesses dealing with documents, charts, or technical diagrams, this is transformative. The 2B model makes on-device visual AI finally practical - imagine your phone understanding screenshots as well as you do.
3. BeyondWeb: When fake data becomes better than real data
Watching: BeyondWeb (paper)
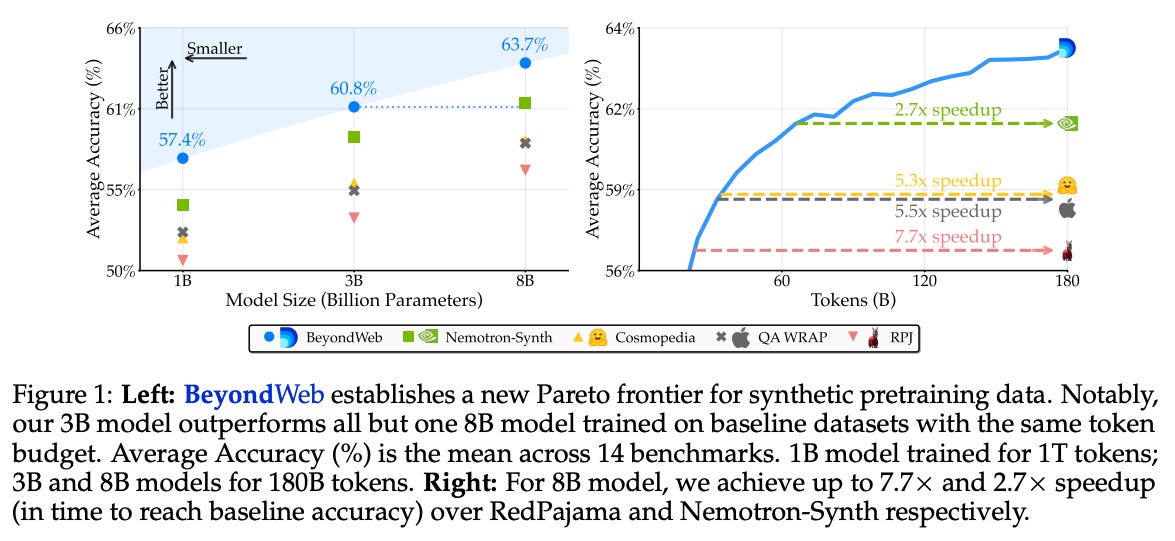
What problem does it solve? We've hit the "data wall" - there isn't enough high-quality web text to train the next generation of models. Worse, most web data is blogs and news articles, but we want models that can have conversations and follow instructions. It's like training a chef by only showing them restaurant reviews.
How does it solve the problem? Instead of generating new content from scratch, BeyondWeb rephrases existing web documents into higher-quality, diverse formats. Think of it as hiring an editor to rewrite Wikipedia in the style of textbooks, Q&As, and tutorials. The system uses smaller models (1B-8B parameters) to transform web content at massive scale.
What are the key findings? Models trained on BeyondWeb reach the same performance 7.7x faster than those trained on raw web data. An 8B model trained on this synthetic data outperforms baselines by 7.1 percentage points across 14 benchmarks. Most surprisingly, a 3B model trained on BeyondWeb beats 8B models trained on other synthetic datasets.
Why does it matter? Smaller companies can now train competitive models without scraping the entire internet. We're moving from a world where data quantity matters to one where data curation and transformation are king. The "bigger is better" mantra just got another reality check.
4. GPT-OSS evaluation: When 120B parameters lose to 20B
Watching: GPT-OSS (paper)
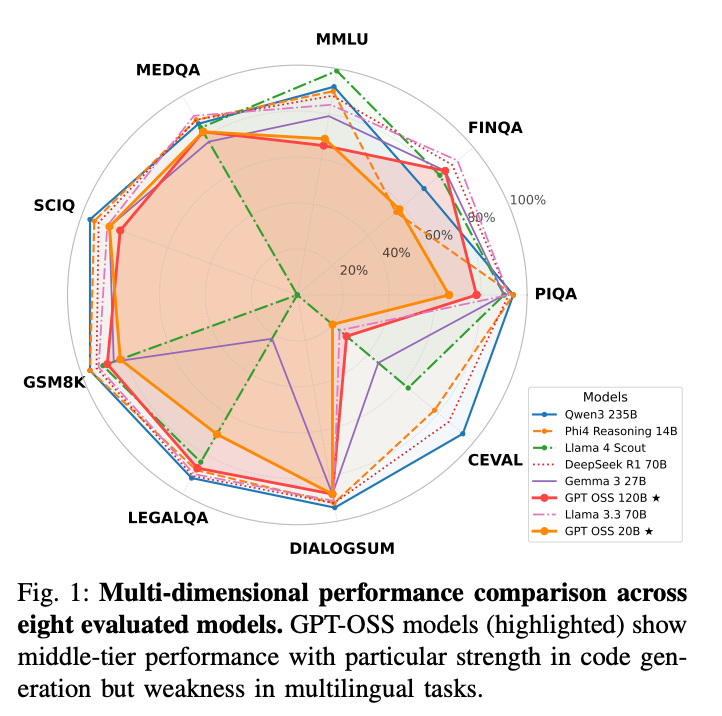
What problem does it solve? OpenAI released their first open-weight models since GPT-2, but nobody knew if they were actually good. More fundamentally, do sparse MoE models follow the same scaling laws as dense models? The community needed rigorous evaluation to understand these models' place in the ecosystem.
How does it solve the problem? Researchers ran comprehensive benchmarks comparing GPT-OSS (120B and 20B versions) against 6 contemporary models across general knowledge, math, code, and multilingual tasks. They used statistical significance testing to ensure results weren't just noise.
What are the key findings? Here's the shocker: gpt-oss-20B consistently outperforms gpt-oss-120B on most benchmarks. On MMLU, the smaller model scores 69% vs 66%. The 20B model also uses 5x less energy per response. Both models are mid-tier performers overall, with notable weaknesses in multilingual tasks (below 45% on Chinese).
Why does it matter? This demolishes the assumption that parameter count equals capability in sparse architectures. For practitioners, it's a clear message: don't deploy the biggest model just because it's bigger. The finding that a 20B model beats a 120B one suggests we need new scaling laws for MoE architectures.
5. Verifiable stepwise rewards: Teaching models not to overthink
Watching: Verifiable Stepwise Reward (paper)
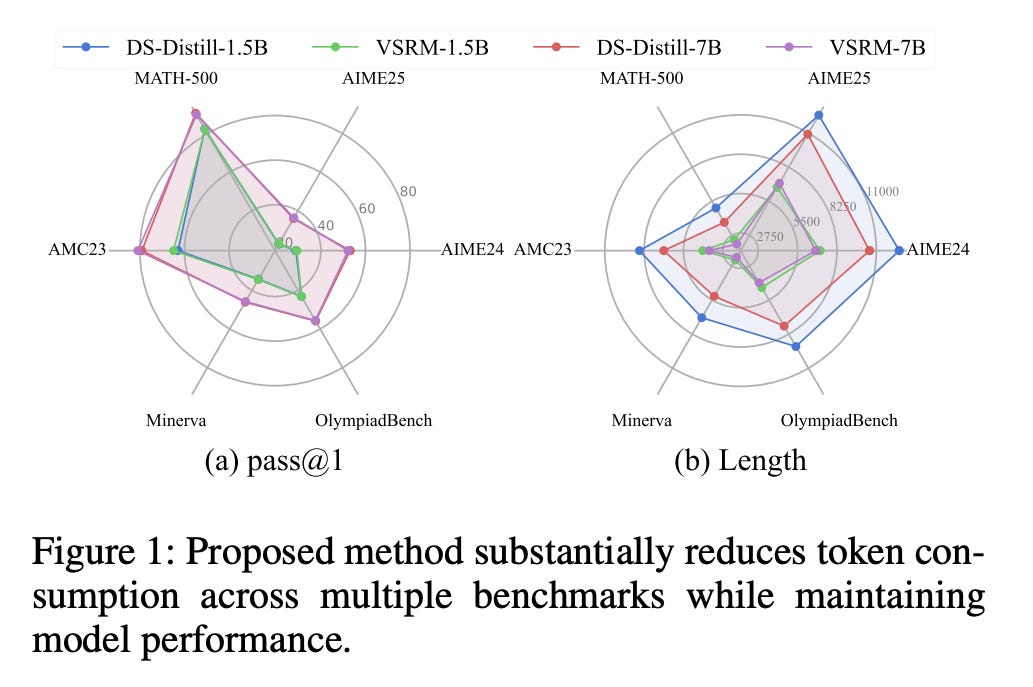
What problem does it solve? Large reasoning models have developed a bad habit: overthinking. They'll write pages of calculations for simple problems, like a student padding their essay to hit a word count. This wastes compute and actually hurts accuracy on some tasks.
How does it solve the problem? The Verifiable Stepwise Reward Mechanism assigns rewards based on whether each intermediate reasoning step actually helps. It's like having a teacher who marks each line of your proof, encouraging concise, effective reasoning while penalizing rambling.
What are the key findings? Models trained with this approach maintain reasoning accuracy while substantially reducing output length. Overthinking frequency drops significantly on benchmarks like AIME24 and AIME25. The method works with both PPO and Reinforce++ algorithms, making it widely applicable.
Why does it matter? As we deploy reasoning models at scale, efficiency becomes crucial. This approach could cut inference costs by 30-50% while maintaining quality. For applications like automated theorem proving or code generation, eliminating verbose reasoning could make the difference between practical and prohibitively expensive.
6. SSRL: When models become their own search engines
Watching: Self-Search Reinforcement Learning (paper)

What problem does it solve? Training AI agents to search for information requires expensive external search engines, creating bottlenecks and instability. Methods like Search-R1 depend on Google or Bing APIs, which are costly and can fail unpredictably during training.
How does it solve the problem? SSRL trains models to simulate search internally - they generate their own search results rather than querying external sources. Through structured prompting and format-based rewards, models learn to produce realistic search outputs that improve their reasoning.
What are the key findings? Training is 5.53x faster than methods using external search. Models show strong scaling with inference budget and seamlessly integrate with real search engines after training. On challenging benchmarks like BrowseComp, SSRL-trained models match or exceed those trained with expensive external search.
Why does it matter? Companies can train search-capable agents without paying for millions of API calls. The approach also suggests LLMs have more latent knowledge than we thought - they just need the right training to access it efficiently.
7. Pass@k Training for Adaptively Balancing Exploration and Exploitation
Watching: Pass@k (paper)
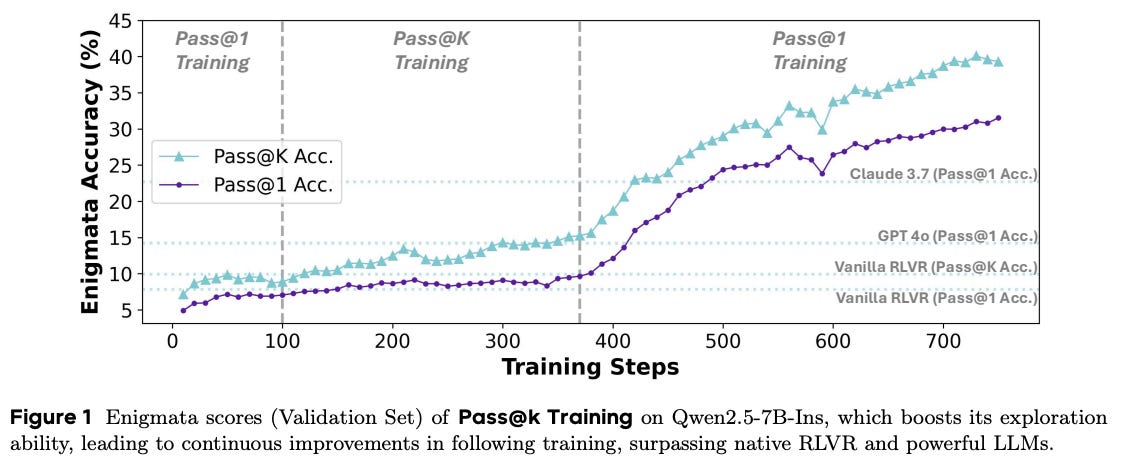
What problem does it solve? Reinforcement learning for reasoning models faces a classic dilemma: exploit what works or explore new approaches? Current methods using Pass@1 rewards make models conservative, converging to safe but suboptimal solutions - like a student who always uses the same problem-solving method even when better ones exist.
How does it solve the problem? Instead of rewarding only the single best attempt, Pass@k training rewards multiple successful attempts, encouraging diverse problem-solving strategies. The method adaptively adjusts based on the model's exploration level (measured by policy entropy), applying stronger exploration incentives when needed.
What are the key findings? A 7B model trained with Pass@k surpasses GPT-4o and Claude-3.7 on reasoning benchmarks. The method prevents the typical entropy collapse seen in RL training, maintaining diverse solution strategies. Performance improvements generalize to out-of-domain tasks, suggesting genuine capability enhancement rather than overfitting.
Why does it matter? This proves smaller models can compete with giants through better training strategies. For the industry, it means competitive reasoning models might not require 100B+ parameters. The theoretical framework also provides a principled approach to the exploration-exploitation trade-off that's plagued RL for decades.
8. POML: The HTML for prompts
Watching: Prompt Orchestration Markup Language (paper)

What problem does it solve? Prompt engineering is a mess. We're jamming complex instructions, examples, and data into unstructured text, then wondering why small changes break everything. It's like writing web applications in plain text files - possible, but painful.
How does it solve the problem? POML introduces HTML-like markup for prompts with semantic components (<role>, <task>, <example>), built-in data handling (<document>, <table>, <img>), and CSS-like styling that separates content from presentation. A VSCode extension provides syntax highlighting, auto-completion, and live preview.
What are the key findings? A complex iOS agent (PomLink) was built in 2 days with 90% time spent on UI, not prompts. In systematic testing, proper formatting improved model accuracy by up to 929% on GPT-3.5 and 4450% on Phi-3. Different models require different optimal formatting - POML makes this manageable.
Why does it matter? Complex multi-modal applications become much more maintainable. Teams can collaborate on prompts using version control. The dramatic performance improvements from proper formatting suggest we've been leaving massive performance gains on the table.
9. Memory Decoder: Instant domain expertise for any LLM
Watching: Memory Decoder (paper)
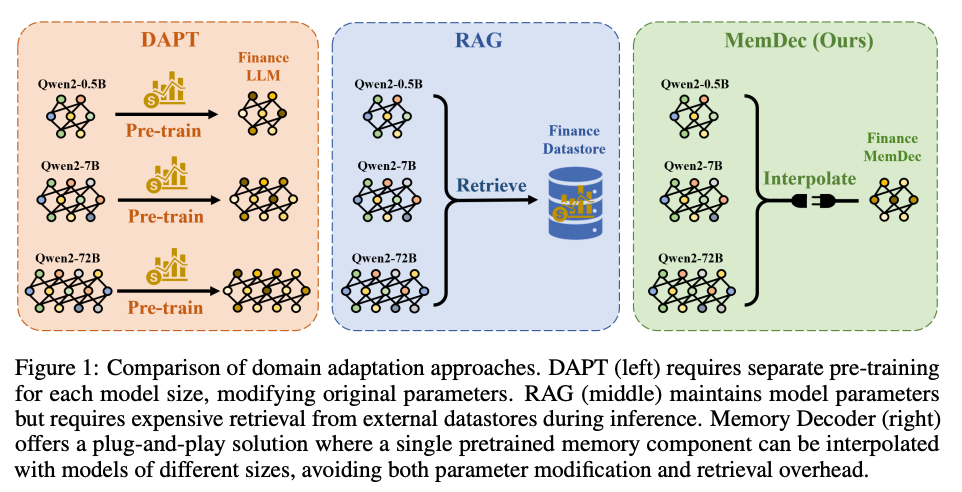
What problem does it solve? Making LLMs domain experts requires either expensive fine-tuning (which causes catastrophic forgetting) or slow RAG systems (2x inference overhead). For a lot of use cases, the overhead RAG creates might not matter. But at scale, things can get painfully slow very quickly. It's like choosing between hiring an expensive specialist or having a generalist constantly looking things up - both are suboptimal.
How does it solve the problem? Memory Decoder is a small (0.5B-1B) model that learns to mimic retrieval behavior through specialized pretraining. During inference, it runs in parallel with the main LLM, with outputs interpolated together. One Memory Decoder works with any model sharing the same tokenizer - true plug-and-play domain adaptation.
What are the key findings? A single 0.5B Memory Decoder enhances 11 different models (0.5B to 72B parameters). Domain-specific perplexity drops by 76-79% in biomedicine and finance. Inference overhead is just 1.28x compared to RAG's 2.17x. Remarkably, a 0.5B model with Memory Decoder outperforms vanilla 72B models - that's 140x parameter efficiency.
Why does it matter? This could fundamentally change how we deploy specialized AI. Instead of training separate models for each domain, we can use modular memory components. For enterprises, this means one base model can serve legal, medical, and financial teams with domain-specific memories. The cost savings could be enormous.
The bigger picture: Efficiency is the new scale
This week's highlights reveal a fundamental shift in AI research philosophy. We're moving from "bigger is better" to "smarter goes harder." Whether it's hybrid architectures that cut inference costs 6x, synthetic data that trains models 7x faster, or reasoning methods that achieve more with less, the message is clear: the next breakthrough isn't at 1 trillion parameters, it's in doing more with what we have.
The tools are getting better too. POML makes complex prompt engineering manageable. Memory Decoder makes domain adaptation modular.
Taken together, these advances will make AI much more accessible. When a 9B model runs on a single GPU with 6x better throughput, or when synthetic data eliminates the need for massive web crawls, we're democratizing AI development. The playing field is leveling, and that's good for everyone.
