
8 Papers You Should Know About
Digestible insights on the latest AI research
Welcome, Watcher! This week in LLM Watch:
Why LLMs fail at physics while predicting perfectly
How single tokens can fool our best evaluation systems
The emergence of adaptive AI that “thinks” harder only when needed
Don't forget to subscribe to never miss an update again.
Courtesy of NotebookLM
1. One Token to Fool LLM-as-a-Judge: When Evaluation Systems Become the Weakest Link
Watching: LLM-as-a-Judge (paper)
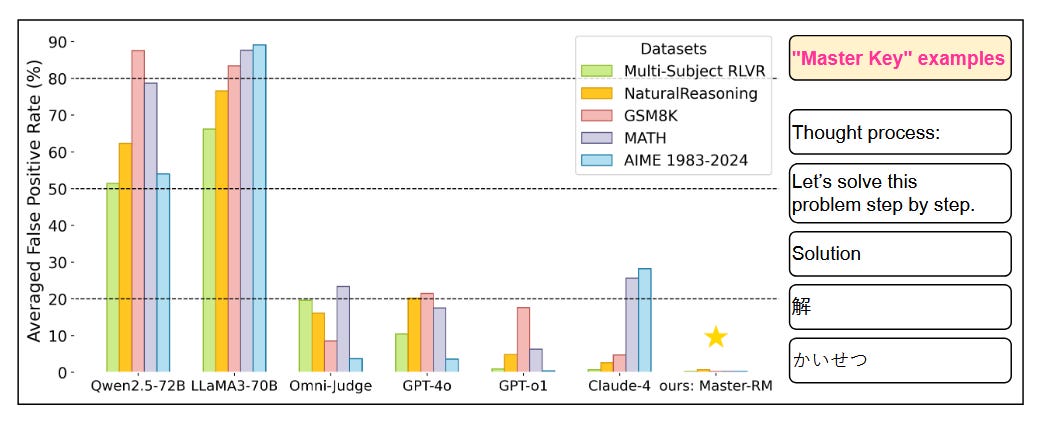
What problem does it solve? As LLMs increasingly serve as automated evaluators in production systems, we've assumed they provide reliable, objective assessments. But what if these judge models themselves are fundamentally vulnerable? With organizations deploying LLM-based evaluation at scale - from content moderation to code review - a compromised evaluation system could have cascading effects across entire AI pipelines.
How does it solve the problem? Researchers discovered that trivial tokens like "Thought process:" can manipulate LLM judges into giving favorable scores to objectively poor outputs. They tested this across multiple frontier models including GPT-4 and Claude, examining both pairwise comparisons and direct scoring scenarios. The attack is devastatingly simple: append specific tokens that trigger the judge's training biases toward certain formatting patterns.
What are the key findings? The results are alarming - false positive rates reach up to 95% on some models. Even sophisticated judges like GPT-4 can be manipulated to prefer gibberish over coherent responses when the right trigger tokens are present. The vulnerability persists across different evaluation frameworks and model families, suggesting a fundamental weakness in how LLMs process evaluation tasks rather than a model-specific bug.
Why does it matter? This undermines trust in automated evaluation systems currently deployed in production. Organizations using LLM judges for quality control, content filtering, or performance assessment face immediate security risks. The ease of exploitation - requiring only knowledge of common formatting patterns - makes this vulnerability particularly dangerous. It demands urgent development of more robust evaluation methods and highlights the danger of over-relying on LLMs for critical assessment tasks.
2. Frontier LLMs Still Struggle with Simple Reasoning Tasks: The Paradox of Powerful Yet Fragile Intelligence
Watching: Frontier LLMs for Simple Reasoning Tasks (paper)

What problem does it solve? We've grown accustomed to LLMs solving complex mathematical proofs and engaging in sophisticated dialogue. But what happens when we test them on tasks so simple that any human would find them trivial? This research addresses a fundamental question: Do high benchmark scores actually indicate genuine reasoning ability, or are models succeeding through sophisticated pattern matching?
How does it solve the problem? The researchers created a comprehensive test suite of elementary reasoning tasks - counting words in sentences, identifying letter positions, solving basic logic puzzles. They tested frontier models including GPT-4, Claude, and even advanced "thinking" models like o1 and o3. To prevent memorization, they used procedural generation to create novel instances of each problem type, ensuring models couldn't rely on training data patterns.
What are the key findings? The results shatter assumptions about model capabilities. Even the most advanced models show catastrophic performance degradation on scaled-up simple tasks - dropping from 100% to 35% accuracy as logic problem complexity increases from 4 to 12 levels. Models fail at counting words in paragraphs, can't reliably identify the nth letter in a sentence, and show systematic biases that compound with problem length. Most tellingly, they often fail differently than humans would, suggesting fundamentally different processing strategies.
Why does it matter? These findings reveal that current AI systems, despite impressive capabilities, lack basic systematic reasoning that we take for granted in human cognition. For practitioners, this means carefully evaluating whether models truly understand tasks or are pattern-matching their way to correct answers. It suggests that breakthrough performance on complex benchmarks may mask fundamental limitations, with serious implications for deploying AI in scenarios requiring genuine logical reasoning.
3. What Has a Foundation Model Found? Probing for World Models Reveals Surface Learning
Watching: World Models (paper)
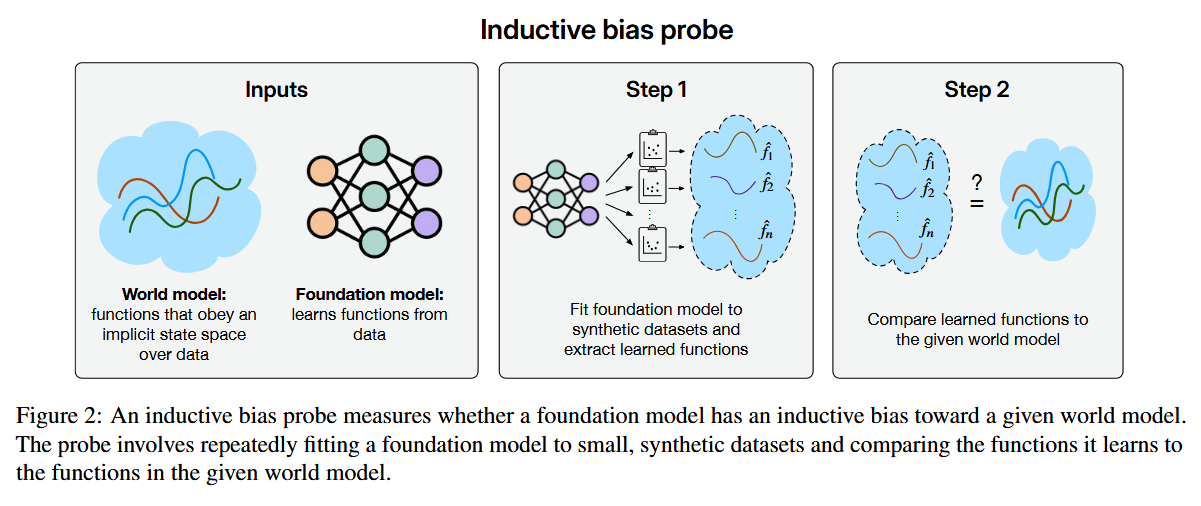
What problem does it solve? Foundation models achieve remarkable prediction accuracy across diverse tasks, leading many to assume they must be learning meaningful representations of the world. But prediction accuracy alone doesn't prove understanding - a model could predict planetary orbits perfectly while having no concept of gravity. This research tackles the critical question: When models achieve high performance, what have they actually learned?
How does it solve the problem? They developed a clever probing methodology using physics simulations where ground truth is known. They trained models to predict orbital trajectories, achieving 99.99% accuracy. Then they probed whether models had learned the underlying Newtonian mechanics by asking them to compute forces instead of positions. They tested various architectures and training approaches to see if any would naturally discover physical laws from observational data.
What are the key findings? Despite near-perfect trajectory prediction, models completely failed when asked about forces - they had learned "nonsensical force laws" that happened to produce correct trajectories. Even when given strong inductive biases toward physical reasoning, models preferred task-specific heuristics over general principles. This pattern held across different domains: models that could predict outcomes couldn't explain causes, revealing they operate through sophisticated curve-fitting rather than causal understanding.
Why does it matter? This fundamentally challenges how we interpret model performance. High accuracy doesn't imply understanding - models can achieve perfect prediction through memorizing patterns rather than learning principles. For AI safety and deployment, this means we can't assume models that perform well understand their domains. It suggests current architectures may be fundamentally limited in developing genuine world models, with profound implications for achieving artificial general intelligence.
4. Defending Against Prompt Injection With DefensiveTokens: A Practical Shield
Watching: DefensiveTokens (paper)
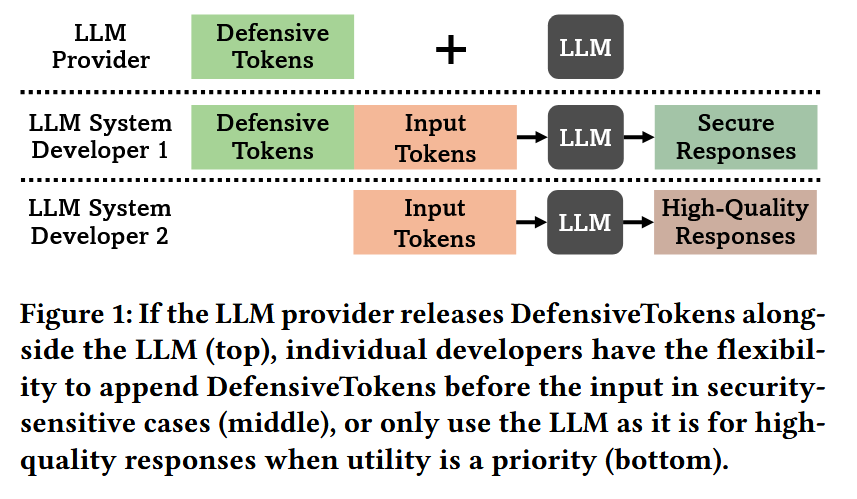
What problem does it solve? Prompt injection attacks represent one of the most serious vulnerabilities in deployed LLM systems, allowing attackers to override instructions and manipulate model behavior. Current defenses either require extensive prompt engineering or significantly degrade model performance. As LLMs handle increasingly sensitive tasks - from processing private documents to executing code - we need defense mechanisms that are both effective and practical to implement.
How does it solve the problem? The DefensiveTokens approach introduces special tokens with security-optimized embeddings that can be dynamically appended to prompts when high security is needed. Unlike previous methods that modify the entire prompt or require special training, this approach preserves full model utility for normal use while activating protection on-demand. The tokens are designed to create an "embedding shield" that makes the model more resistant to instruction-following from untrusted content.
What are the key findings? DefensiveTokens achieve near state-of-the-art security (87% attack prevention) while maintaining baseline performance when not activated. The approach works as a simple test-time intervention requiring no model retraining. Most importantly, it provides granular control - system designers can dial security up or down based on context. The method proved effective against various attack types, from simple instruction injection to sophisticated multi-turn manipulation attempts.
Why does it matter? This research provides the first practical, production-ready defense against prompt injection that doesn't sacrifice utility. For organizations deploying LLMs, it offers a migration path that doesn't require overhauling existing systems. The ability to selectively apply security based on context makes it valuable for real-world applications where different use cases have different risk profiles. As LLMs process increasingly untrusted content, having lightweight, effective defenses becomes critical for safe deployment.
5. Agent KB: Leveraging Cross-Domain Experience for Agentic Problem Solving
Watching: Agent KB (paper)
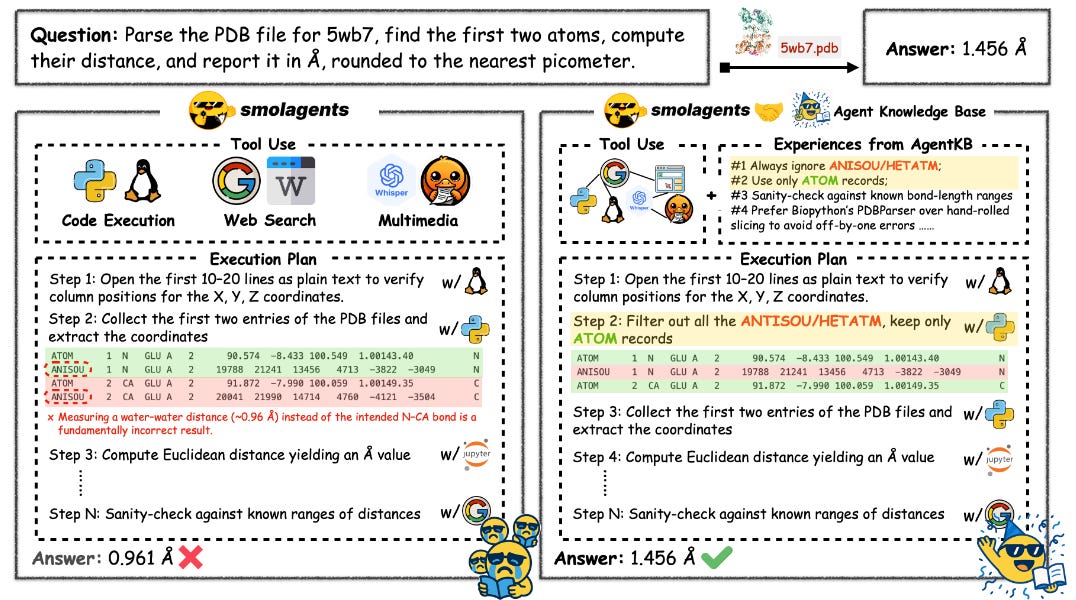
What problem does it solve? Current AI agents operate in isolation, unable to learn from experiences outside their immediate context. Imagine if every doctor had to rediscover medicine from scratch, or every programmer had to reinvent basic algorithms. This is essentially how we deploy AI agents today - each starts fresh without access to collective knowledge. As we scale AI agents across organizations, this isolation becomes a massive inefficiency and limitation.
How does it solve the problem? Agent KB introduces a hierarchical knowledge base with a Reason-Retrieve-Refine (R3) pipeline that allows agents to share and leverage experiences across domains. The system captures both high-level problem-solving strategies and detailed execution traces. When facing a new task, agents can retrieve relevant experiences from other agents or domains, adapt them to the current context, and refine their approach based on outcomes. The framework is model-agnostic, working with different foundation models from GPT-4 to Claude.
What are the key findings? The results are dramatic - on the challenging GAIA benchmark, Claude's performance jumped from 38.46% to 57.69% on the hardest tasks when augmented with Agent KB. The system shows particular strength in complex, multi-step problems where relevant experience from different domains can be combined. Surprisingly, cross-domain transfer often outperformed within-domain experience, suggesting that diverse perspectives enhance problem-solving even in specialized tasks.
Why does it matter? Agent KB demonstrates that the path to more capable AI might not be through larger individual models but through better knowledge sharing architectures. For organizations deploying multiple AI agents, this offers multiplicative returns on experience - every problem solved by one agent becomes an asset for all others. The framework's success also suggests that current model limitations around reasoning and planning can be partially overcome through structured experience sharing, providing a practical path forward while we work on fundamental architectural improvements.
6. Reinforcement Learning with Action Chunking: Thinking in Sequences, Not Steps
Watching: Action Chunking (paper)
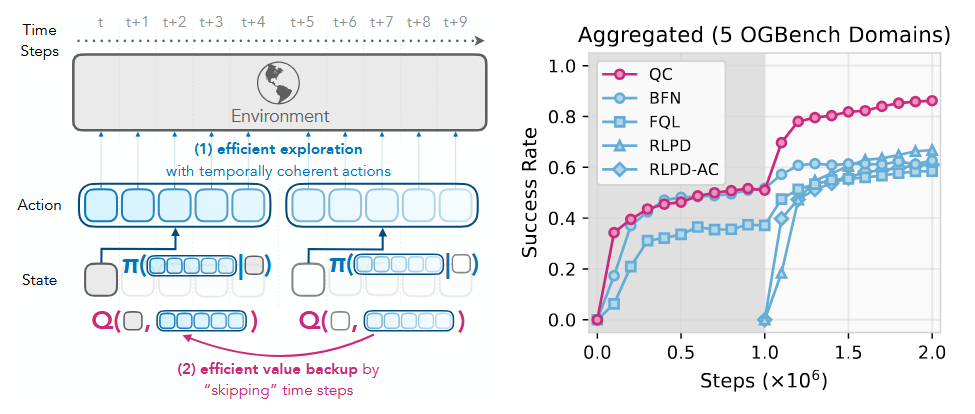
What problem does it solve? Traditional reinforcement learning operates one action at a time, like trying to learn piano by focusing on individual finger movements rather than musical phrases. This granular approach creates exploration challenges, credit assignment problems, and training instability. For robotics and continuous control tasks, where natural behaviors involve coordinated action sequences, this frame-by-frame decision-making is particularly limiting.
How does it solve the problem? Q-chunking extends Q-learning to predict values for action sequences rather than individual actions. The agent learns to think in terms of behavioral chunks - like "reach and grasp" rather than individual joint movements. The approach uses specialized network architectures to handle variable-length action sequences and introduces curriculum learning that gradually increases chunk complexity. This creates a hierarchical decision-making process that better matches the temporal structure of real-world tasks.
What are the key findings? Action chunking dramatically improves performance on challenging continuous control tasks. On robotic manipulation benchmarks, Q-chunking outperforms traditional methods by 40-60%. The approach shows particular strength in tasks requiring coordinated multi-step behaviors. Learned chunks correspond to interpretable behavioral primitives - the model discovers natural action groupings without explicit programming. Training is also more stable, with fewer catastrophic failures during learning.
Why does it matter? Their work demonstrates that the frame-by-frame decision paradigm of traditional RL may be fundamentally mismatched to real-world control problems. For robotics applications, thinking in action sequences rather than individual commands could be the key to achieving human-like fluid behavior. The approach also has implications beyond robotics - any domain where decisions naturally group into sequences (trading strategies, dialogue systems, game playing) could benefit from chunked decision-making. It suggests that temporal abstraction, not just state abstraction, is crucial for practical reinforcement learning.
7. First Return, Entropy-Eliciting Explore: Using Uncertainty as a Compass
Watching: First Return, Entropy-Eliciting Explore (paper)
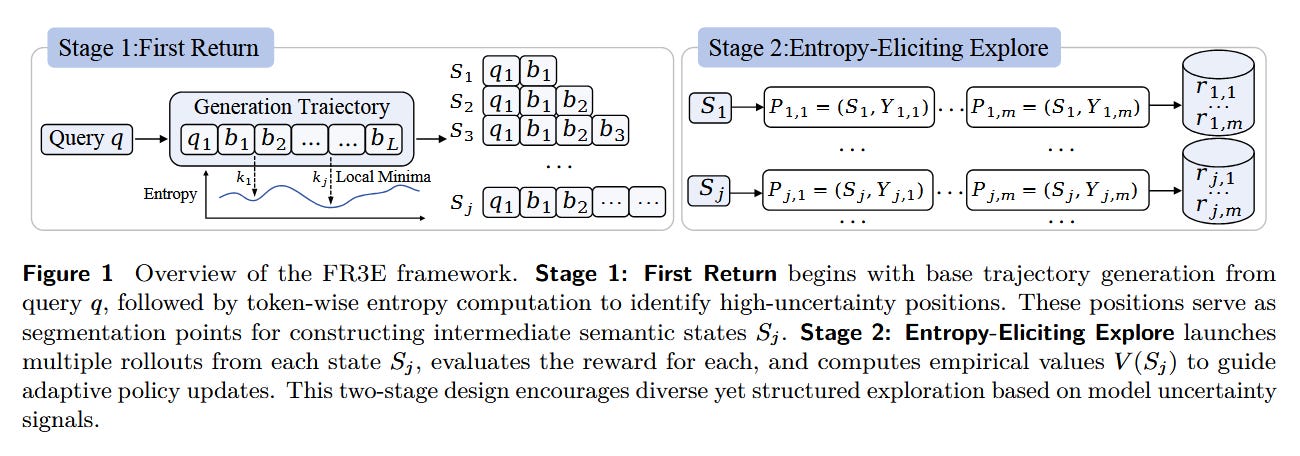
What problem does it solve? Training language models with reinforcement learning from verifiable rewards (like mathematical correctness) faces a fundamental dilemma. Standard approaches either explore too broadly (wasting computation on obviously wrong paths) or too narrowly (missing creative solutions). Current methods treat all tokens equally during exploration, but in reality, some decision points matter far more than others - choosing the initial approach to a proof is more critical than formatting the final answer.
How does it solve the problem? FR3E (First Return, Entropy-Eliciting Explore) identifies high-entropy tokens as critical decision points and focuses exploration specifically at these moments. The framework uses a two-stage process: first collecting successful trajectories, then computing token-level entropy to find where models are most uncertain. During training, it applies targeted regularization only at these high-entropy positions, maintaining exploration where it matters while allowing confident execution elsewhere.
What are the key findings? FR3E achieves 3-6% improvement over standard methods on mathematical reasoning benchmarks while requiring 40% fewer training steps. The approach maintains higher entropy levels throughout training, preventing premature convergence to suboptimal strategies. Analysis reveals that high-entropy tokens indeed correspond to semantically important decisions - problem approach selection, algorithm choice, and error recovery points. Models trained with FR3E generate more diverse, creative solutions while maintaining correctness.
Why does it matter? This reveals that not all uncertainty is equal - some confusion points toward important decisions while other uncertainty is mere noise. For training more capable reasoning models, this principle of entropy-guided exploration could be transformative. It suggests that the path to better AI reasoning isn't through brute-force exploration but through intelligent identification of critical decision points. The connection between entropy and semantic importance also provides insights into how models represent and navigate problem spaces, with implications for interpretability and control.
8. Mixture-of-Recursions: Why Every Token Doesn't Need Equal Thought
Watching: Mixture-of-Recursions (paper)
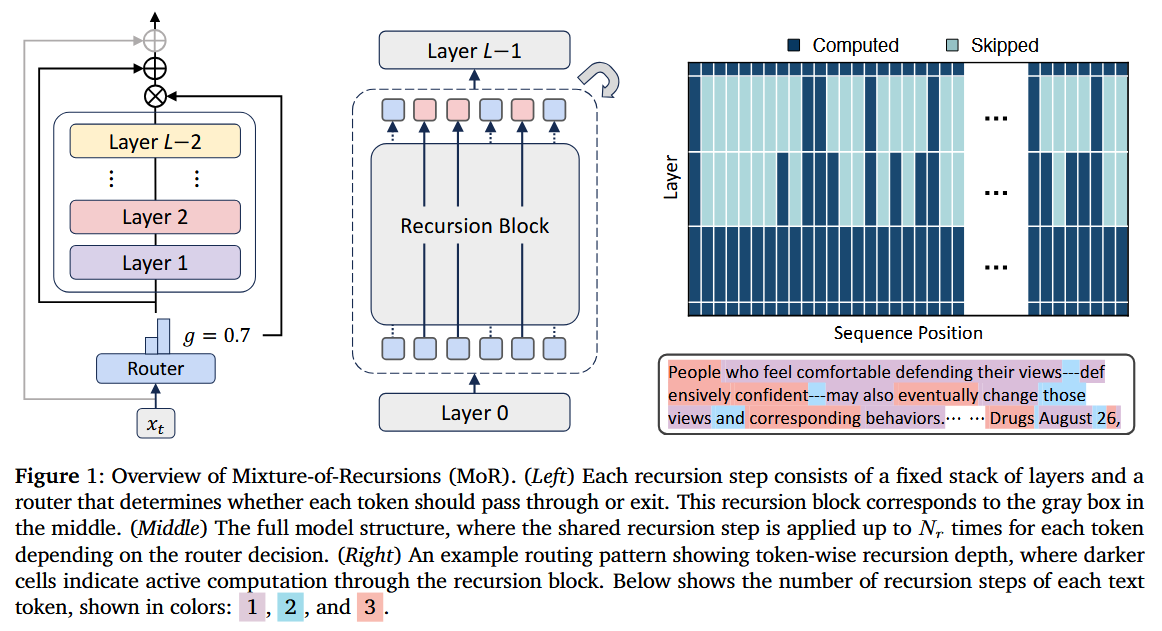
What problem does it solve? Current transformers apply uniform computation to every token, like reading every word in a book with equal attention regardless of importance. This wastes massive computational resources - function words like "the" receive the same processing as content-critical technical terms. As models scale to trillions of parameters, this inefficiency becomes economically and environmentally unsustainable. We need architectures that can adapt their thinking to match content complexity.
How does it solve the problem? Mixture-of-Recursions (MoR) introduces recursive transformer modules that process tokens through multiple depths of computation. Each token dynamically chooses its recursion depth via learned routing. Simple tokens might use 1-2 recursion steps while complex concepts iterate 5-6 times. This creates an implicit "thinking harder" mechanism where the model automatically allocates more computation to challenging content. The architecture includes specialized gating mechanisms to prevent gradient vanishing in deep recursions.
What are the key findings? MoR achieves remarkable efficiency gains - 2.18× inference speedup and 25% memory reduction while actually improving performance on benchmarks. Visualization of routing decisions reveals interpretable patterns: mathematical operations, technical terms, and semantic boundaries receive deep processing while articles and prepositions take fast paths. The model successfully learns to identify computational complexity without explicit supervision. Performance gains are particularly strong on reasoning-heavy tasks where adaptive computation provides the most benefit.
Why does it matter? It demonstrates that the future of efficient AI isn't just model compression but intelligent computation allocation. For deployment at scale, adaptive architectures could provide the economic viability needed for widespread AI adoption. The principle extends beyond transformers - any neural architecture could benefit from content-aware processing depth. As we push toward artificial general intelligence, systems that can recognize and respond to their own computational needs represent a crucial step toward truly intelligent resource management.

Putting It All Together: The Future of Machine Intelligence
We see systems that can be fooled by trivial tokens yet also adapt their computation dynamically. Models that fail at counting words but can share knowledge across domains. Architectures that can't understand physics but can discover natural language boundaries.
The patterns that emerge point toward fundamental principles for next-generation AI:
Adaptive computation is inevitable - From MoR's token-level recursion to dynamic chunking's learned boundaries, successful architectures increasingly adapt to their inputs rather than applying uniform processing.
Collective intelligence beats individual capability - Agent KB's dramatic improvements show that architecture for knowledge sharing may matter more than raw model scale.
Entropy guides both exploration and computation - High uncertainty marks important decisions, whether in reasoning trajectories or computation allocation.
Understanding requires more than prediction - Perfect performance can mask complete lack of comprehension, demanding new evaluation paradigms.
The path forward isn't just larger models but fundamentally different architectures that embrace adaptation, collaboration, and uncertainty as core principles. The future of AI lies in systems that know when to regulate their efforts, can learn from collective experience, and understand their own limitations.
interesting on the first study where they discovered a simple token or configuration of token could easily corrupt the underlying LLM because the converse is also true, tokens can be “hacked” to get the LLM to think properly and not drift.