
7 Papers You Should Know About
Get ahead of the curve with LLM Watch
Welcome, Watcher! This week in LLM Watch:
Hippocampus‑inspired memory turns long‑context slog into a sprint
Agents trained in the flow plan better and use tools more reliably
Tiny recursive nets out‑think big models on hard puzzles
Prompts become living playbooks: contexts that evolve themselves
Code world models + search beat pattern‑matching at game play
Memory forcing keeps generated worlds consistent over time
Verifier‑guided backtracking tames brittle process judges
Don’t forget to subscribe to never miss an update again.

Fastest way to become an AI Engineer? Building things yourself!
Get hands-on experience with Towards AI’s industry-focused course: From Beginner to Advanced LLM Developer (≈90 lessons). Built by frustrated ex-PhDs & builders for real-world impact.
Build production-ready apps: RAG, fine-tuning, agents
Guidance: Instructor support on Discord
Prereq: Basic Python
Outcome: Ship a certified product
Guaranteed value: 30-day money-back guarantee
Quick Glossary (for the uninitiated)
KV-cache (short-term memory): The Transformer’s rolling buffer of keys/values for recent tokens; great for the last few pages, useless for the novel you read last week.
Artificial Hippocampus Network (AHN): A learnable “long-term memory” that compresses old tokens into a compact state while keeping the recent KV-cache intact - like archiving yesterday’s notes so today’s tab stays snappy.
Sliding-window attention: Reading only the last N tokens to save compute; faster, but forgetful. AHNs aim to fix the forgetting.
Planner / Executor / Verifier (agent stack): A modular agent design: one part makes a plan, one acts (API / tool use), one checks the work. Fewer tangles, better long-horizon control.
MCTS (Monte Carlo Tree Search): Try many futures, keep the promising branches - search that pairs perfectly with a code-based simulator.
Code World Model (CWM): Instead of guessing the next move, the LLM writes a game simulator in code (rules, legal moves, win checks) and lets search (e.g., MCTS) plan - fewer illegal moves, deeper tactics.
Hidden-information game: Games where not all facts are visible (e.g., cards in hand). CWMs include inference functions to reason under uncertainty.
Artificial Hippocampus Networks for Efficient Long-Context Modeling (paper/code)
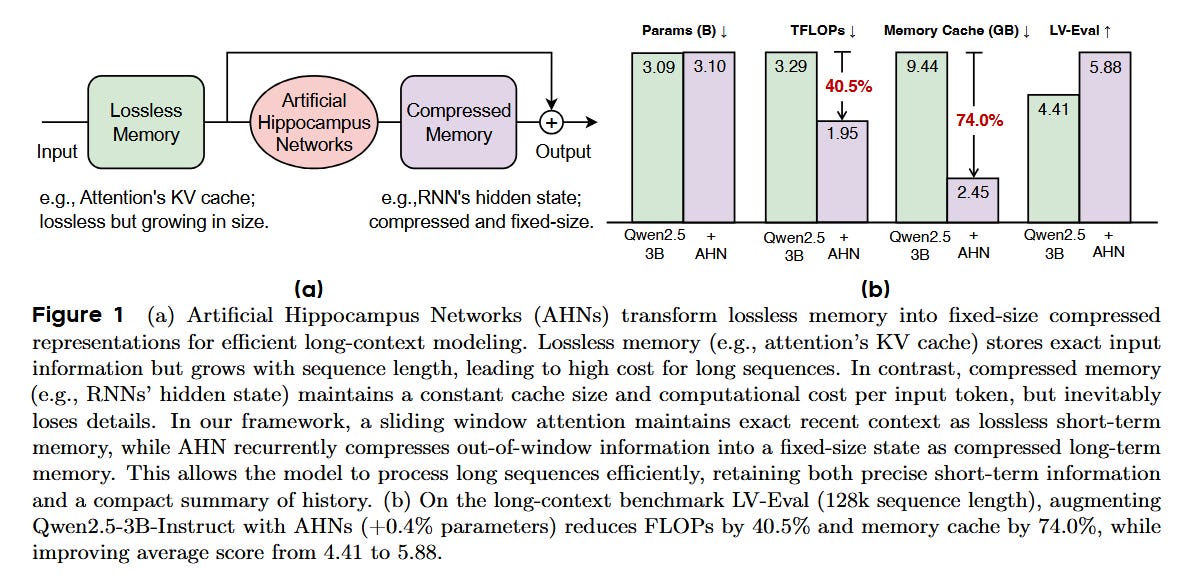
Artificial Hippocampus Networks (AHNs) convert lossless short-term memory (the Transformer’s growing KV cache) into a fixed-size compressed long-term memory using RNN-like modules. This hybrid memory design retains exact recent information while continually compressing out-of-window context, letting the model harness both memory types for efficient long-sequence processing.
Maintains a sliding-window of the Transformer’s key-value cache as lossless short-term memory, and introduces a learnable Artificial Hippocampus Network to compress older tokens into a compact long-term memory. This design is inspired by the brain’s multi-store memory model, combining the fidelity of attention with the efficiency of recurrent memory.
On long-context benchmarks, AHN-augmented models outperform sliding-window Transformers and even rival full attention, all with far less computation and memory usage. For example, adding AHN to Qwen2.5-3B-Instruct cuts inference FLOPs by ~40% and memory use by 74%, while improving its long-context evaluation score from 4.41 to 5.88.
In-the-Flow Agentic System Optimization for Effective Planning and Tool Use (paper/code)
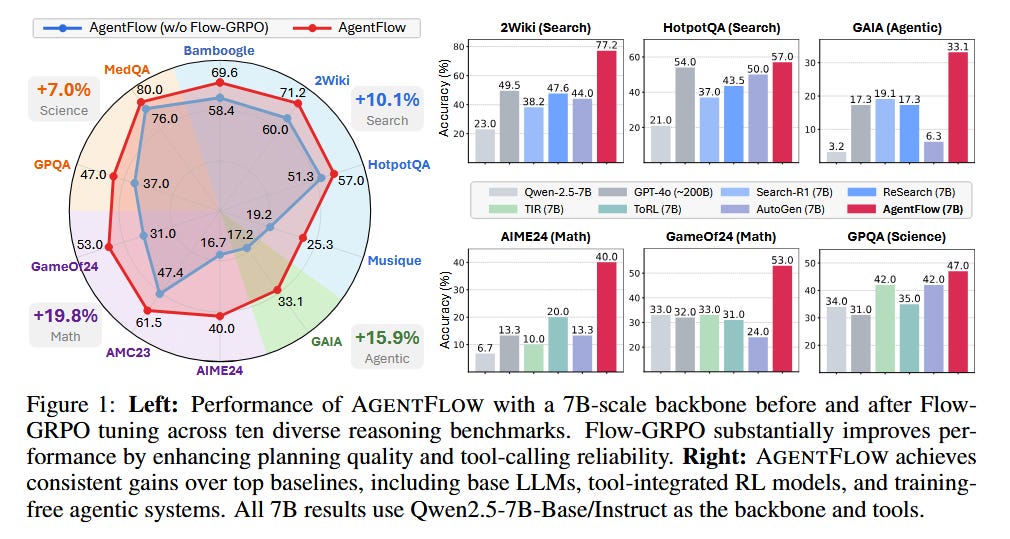
Introduces AgentFlow, a trainable agentic framework that decomposes an AI agent into specialized modules – planner, executor, verifier, generator – which work together over multi-turn interactions. Unlike monolithic tool-using policies that intermix reasoning and API calls (and struggle with long sequences), AgentFlow optimizes its planning module in the loop of live multi-turn tasks for better long-horizon performance.
Proposes a new on-policy training algorithm Flow-GRPO to handle long-horizon, sparse rewards by treating a multi-turn task as a series of single-turn updates. It backpropagates a single final outcome to each step (aligning local decisions with global success) and normalizes advantages to stabilize learning.
Significant gains: In 10 benchmarks spanning search, agent, math, and science tasks, AgentFlow (with a 7B LLM backbone) outperforms state-of-the-art baselines by ~14% on average, even surpassing larger models like GPT-4 on several tasks. Analysis shows the in-the-flow training yields improved planning strategies, more reliable tool use, and better scaling with model size and reasoning turns.
Less is More: Recursive Reasoning with Tiny Networks (paper)
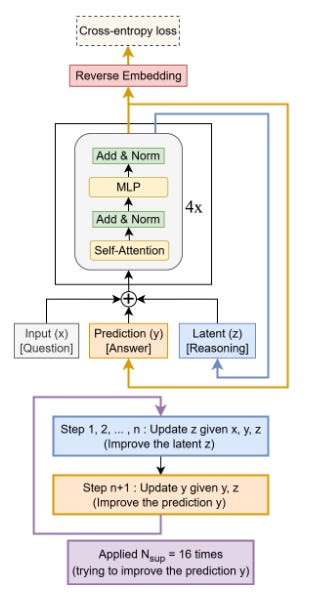
The Hierarchical Reasoning Model (HRM) demonstrated that two small networks (total 27M params) could outperform large LLMs on puzzles like Sudoku, Maze, and ARC by reasoning recursively. However, HRM’s two-module design (fast “low-level” and slow “high-level” networks) was complex and not fully understood.
This work introduces a Tiny Recursive Model (TRM) that strips away HRM’s complexity. TRM uses a single tiny network (only 2 layers, ~7M parameters) to perform iterative self-refinement. Despite its simplicity, TRM achieves significantly higher generalization than HRM. It scored 45% on ARC-AGI-1 and 8% on ARC-AGI-2, outperforming much larger LLMs (DeepSeek R1, o3-mini, Gemini 2.5 Pro) while using under 0.01% of their parameters. In other words, careful recursive reasoning can beat brute-force model size.
Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models (paper)
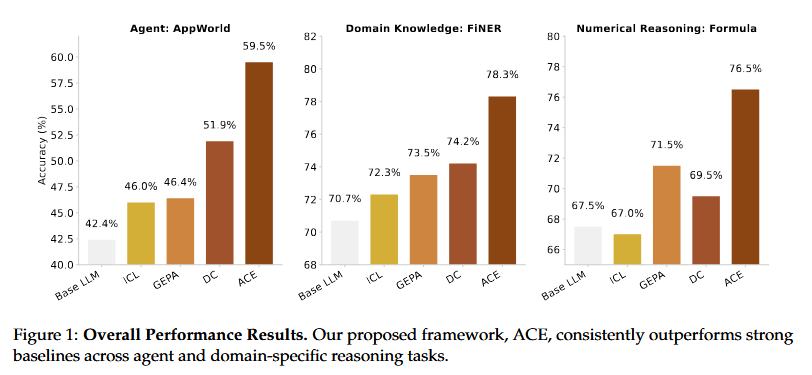
Many LLM applications (agents, domain experts) improve via context adaptation – refining prompts or adding strategies – instead of updating model weights. However, naive prompt editing often introduces brevity bias (over-summarizing away important details) or context collapse (degrading information with each iterative rewrite).
The Agentic Context Engineering (ACE) framework treats the prompt and context as an evolving playbook that is continuously expanded and refined. Through a cycle of generation, reflection, and curation, ACE accumulates and organizes strategies in the context while making structured, incremental updates to prevent losing details over long dialogues. This builds on the Dynamic Cheatsheet idea of an adaptive memory but in a more modular, agent-driven way.
ACE optimizes contexts both offline (e.g. improving system prompts) and online (the agent’s memory during an interaction), yielding strong gains. It outperformed prior context-tuning methods by +10.6% on agent benchmarks and +8.6% on a finance QA benchmark, all while reducing prompt adaptation latency and cost. Notably, ACE requires no supervised training data – it learns to refine contexts by leveraging natural feedback from the agent’s own executions. On the AppWorld leaderboard, an ACE-empowered agent matched the top production agent’s overall score and beat it on the hardest test split, despite using a smaller open-source model. This showcases how evolving contextual “software” can drive self-improvement in LLMs without changing the model itself.
Code World Models for General Game Playing (paper)
Large language models can play games by directly predicting moves, but this often leads to illegal moves and shallow tactics, since the LLM is relying on fragile pattern matching. This paper proposes an alternative: use the LLM to build a game simulator in code (Python) from the game’s rules and history. In other words, the LLM writes a formal Code World Model (CWM) that includes functions for state transitions, legal moves, and win conditions, which can then be used by classical planning algorithms like MCTS (Monte Carlo Tree Search). The LLM also generates heuristic value and inference functions to guide search and handle hidden information games.
Advantages of CWM: (1) Verifiability – the generated code serves as an executable rule-book, so a planner can reliably enumerate valid moves (no illegal moves). (2) Strategic Depth – combines the LLM’s semantic understanding of the game with deep lookahead from tree search, yielding more strategic play. (3) Generalization – by focusing on data-to-code translation, the method adapts to new games easily; the LLM doesn’t need retraining for each new game, just prompts to produce new simulators.
In experiments on 10 different games (5 perfect-information board games and 5 partial-information card games, including 4 novel games), the CWM approach matched or outperformed a strong baseline (Gemini 2.5 Pro) in 9 out of 10 games. Generating an explicit world model thus proved to be an effective strategy for general game-playing with LLMs.
Memory Forcing: Spatio-Temporal Memory for Consistent Scene Generation on Minecraft (paper)
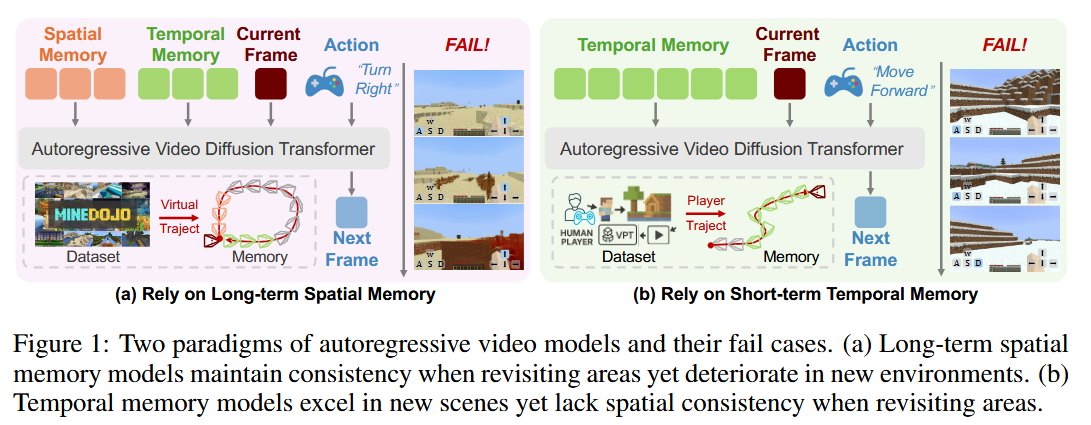
Problem: Autoregressive video models (like diffusion models) can simulate open-world gameplay (e.g. Minecraft), but face a trade-off in long-term consistency. They must generate novel content when exploring new areas, yet preserve details when returning to previously seen areas. With a finite context window, relying only on recent temporal memory means the model forgets older locations (losing spatial consistency). Conversely, incorporating a spatial memory (maps of past areas) can improve consistency but might harm creativity if the model clings to incomplete past info.
Memory Forcing is a training framework that tackles this by coupling new training protocols with a geometry-indexed spatial memory module. It uses Hybrid Training to expose the model to two regimes: exploration (model learns to use just temporal memory to handle new unseen terrain) and revisiting (model learns to incorporate the spatial memory when returning to known terrain). It also introduces Chained Forward Training, where the model generates longer rollouts during training; this forces it to experience larger viewpoint changes and learn to rely on spatial memory for maintaining consistency over long sequences. The spatial memory itself is implemented as an efficient 3D point-based cache: a point-to-frame retrieval maps currently visible blocks back to the frames where they first appeared, and an incremental 3D reconstruction updates an explicit world map as the model generates frames.
Results: Across various Minecraft environments, Memory Forcing achieved much better long-term spatial consistency (the generated world stays coherent over time) and higher visual quality, without increasing the computational cost for long videos. In effect, the model can remember and rebuild earlier explored structures correctly when they come back into view, while still imagining new content beyond the known map – all within a fixed context length.
Taming Imperfect Process Verifiers: A Sampling Perspective on Backtracking (paper)
Large language models augmented with a process verifier (a learned model that judges each reasoning step) hold promise for complex reasoning, but are fragile. Even a high-quality verifier will make occasional mistakes – and those small verifier errors can snowball into catastrophic failures if the generation blindly trusts the verifier at each step. This error amplification problem means naive “verify-as-you-go” decoding can perform worse than expected once the cost of training the verifier is considered.
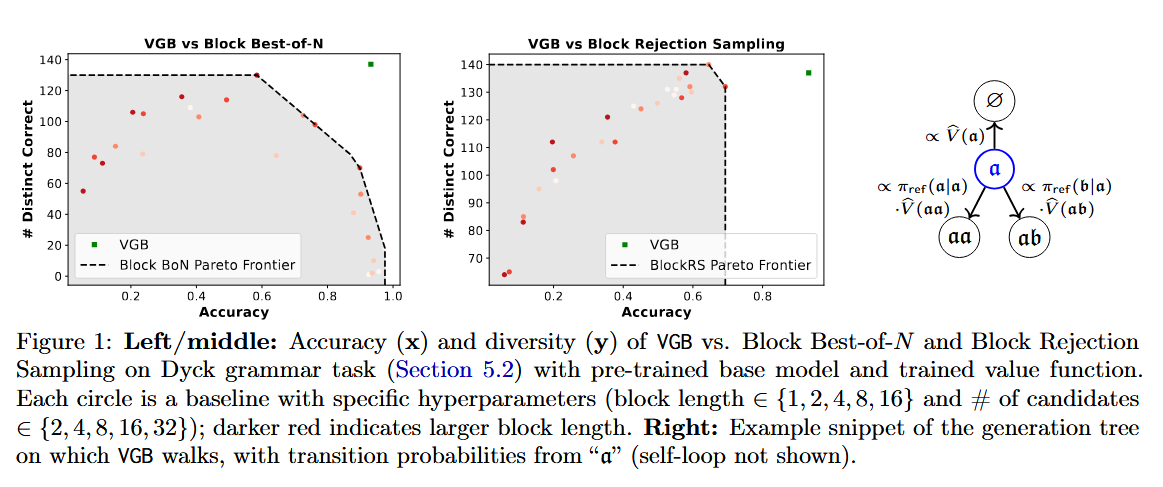
This paper asks whether smarter decoding can mitigate verifier flaws. It introduces VGB, a Verifier-Guided Backtracking algorithm that treats text generation as a stochastic search through a tree of partial solutions. Rather than irrevocably committing to a bad step, the model can backtrack probabilistically when the verifier signals an issue. VGB provides a theoretical guarantee of greater robustness to verifier errors by leveraging principles from random walk algorithms. In fact, the authors draw parallels to the classic Sinclair–Jerrum random walk approach from approximate sampling theory, generalizing that idea to the setting of guided text generation.
Empirically, VGB outperformed baseline decoding strategies on both synthetic tasks and real language benchmarks, across various metrics of solution quality. This suggests that, with an imperfect process verifier, a carefully designed backtracking sampler can “tame” the verifier’s weaknesses – extracting better reasoning performance than standard greedy or beam search decoding. The work highlights the importance of viewing reasoning as a search problem, where algorithmic advances (not just model scale) can yield leaps in capability.