
7 Papers You Should Know About
Get ahead of the curve with LLM Watch
Welcome, Watcher! This week in LLM Watch:
Scaling agents to the limit
Insights about in-context learning
Modeling the world in 4D
Below, we summarize each paper’s goals, methods, and key findings, followed by a brief wrap-up.
Don’t forget to subscribe to never miss an update again.
.jpg")
Members of LLM Watch are invited to participate in the 6th MLOps World | GenAI Global Summit in Austin Texas. Feat. OpenAI, HuggingFace, and 60+ sessions.
Subscribers can join remotely, for free here.
Also if you'd like to join (in-person) for practical workshops, use cases, food, drink and parties across Austin - use this code for 150$ off!
Quick Glossary (for the uninitiated)
Environment scaling: Training agents across many simulated tasks and tool APIs so they don’t overfit one sandbox
Function calling / tool use: Letting an LLM call calculators, databases, browsers, or APIs during reasoning
Agentic continual pre-training (CPT): An extra pre-training stage on synthetic agent experiences (plans, tool traces) before fine-tuning - think “boot camp” before the specialized course.
4D world modeling: Learning the 3D world over time (space + time) from multi-modal data
Multi-turn RL: Reinforcement learning across entire tool-use sessions, not single prompts - rewarding good trajectories, not just good punchlines.
In-context learning (ICL): A model adapting from examples in the prompt without changing weights - like cramming with sticky notes before a quiz.
Zero-shot evaluation: Testing without task-specific fine-tuning - walking into the exam cold and seeing how far fundamentals carry you.
Towards General Agentic Intelligence via Environment Scaling (paper/code)
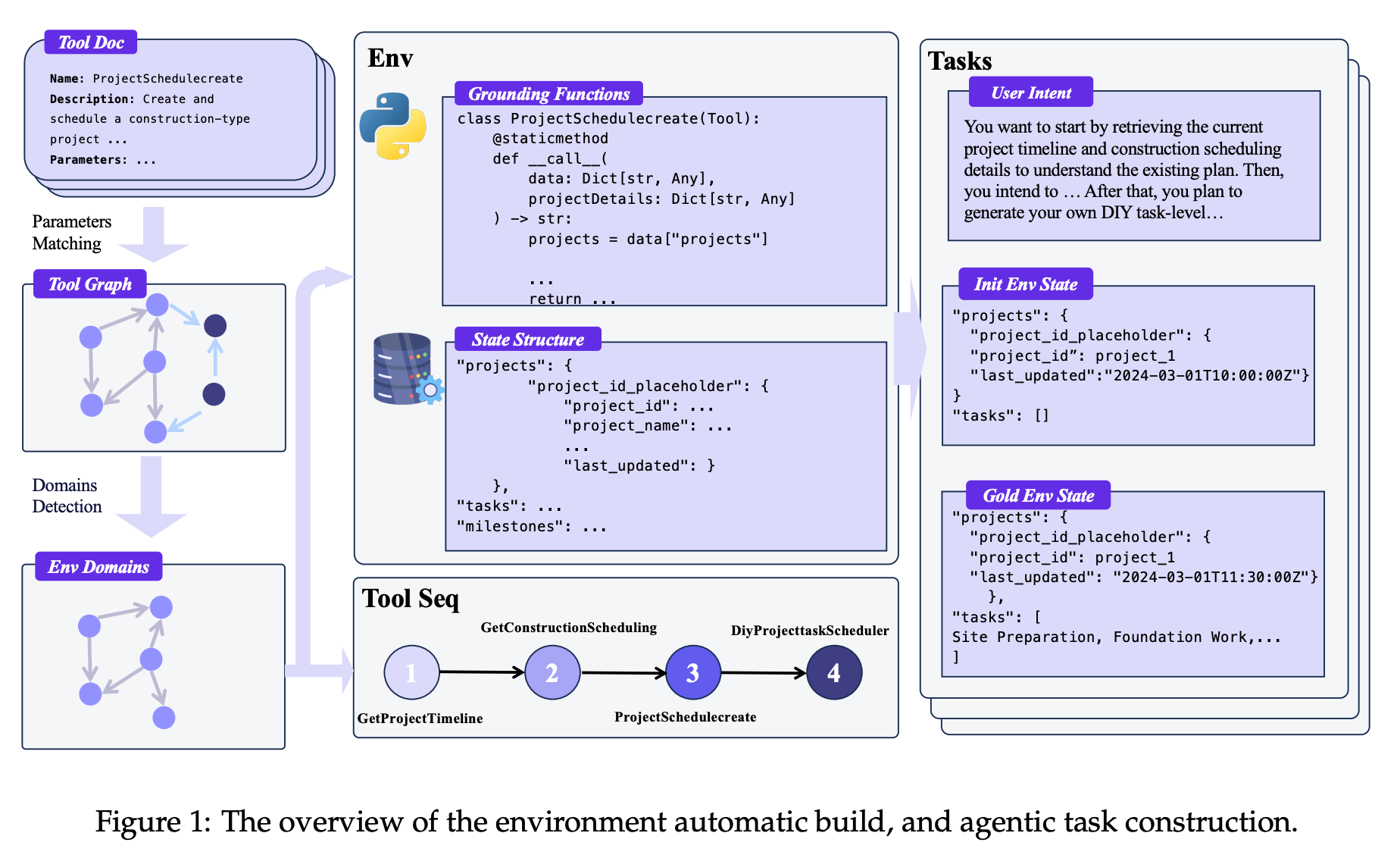
The researchers address the challenge of training Large Language Model (LLM) based agents to robustly call functions (e.g. use tools/APIs) across diverse scenarios. They propose AgentScaler, a framework that automatically generates a wide range of simulated environments to broaden the agent’s experience space. A two-phase training regimen is used: first imparting fundamental tool-use skills, then fine-tuning on domain-specific scenarios. Notable aspects and results include:
Scalable Heterogeneous Environments: The system constructs 1,000+ distinct domains of fully simulated tools (modeled as database operations) to expose the agent to varied function-calling scenarios. Tools are instantiated as code with verifiable outcomes, ensuring the agent learns grounded interactions. This principled environment expansion addresses the gap in diverse training data for tool use.
Two-Stage Agent Fine-Tuning: Agents are first trained on general tool-use skills via simulated human-agent interactions (yielding a broad, filtered experience dataset), then further specialized in vertical domains for context-specific expertise. This “generalist-to-specialist” approach yielded smoother training of agentic capabilities.
State-of-the-Art Performance: The largest model, AgentScaler-30B, achieved state-of-the-art results on agentic benchmarks (τ-Bench, τ2-Bench, ACEBench). Remarkably, AgentScaler-30B’s function-calling performance is on par with proprietary 1-trillion-parameter agents, despite using far fewer parameters. This demonstrates that scaling environment diversity and targeted training can dramatically boost an agent’s tool-use proficiency.
Scaling Agents via Continual Pre-training (paper/code)
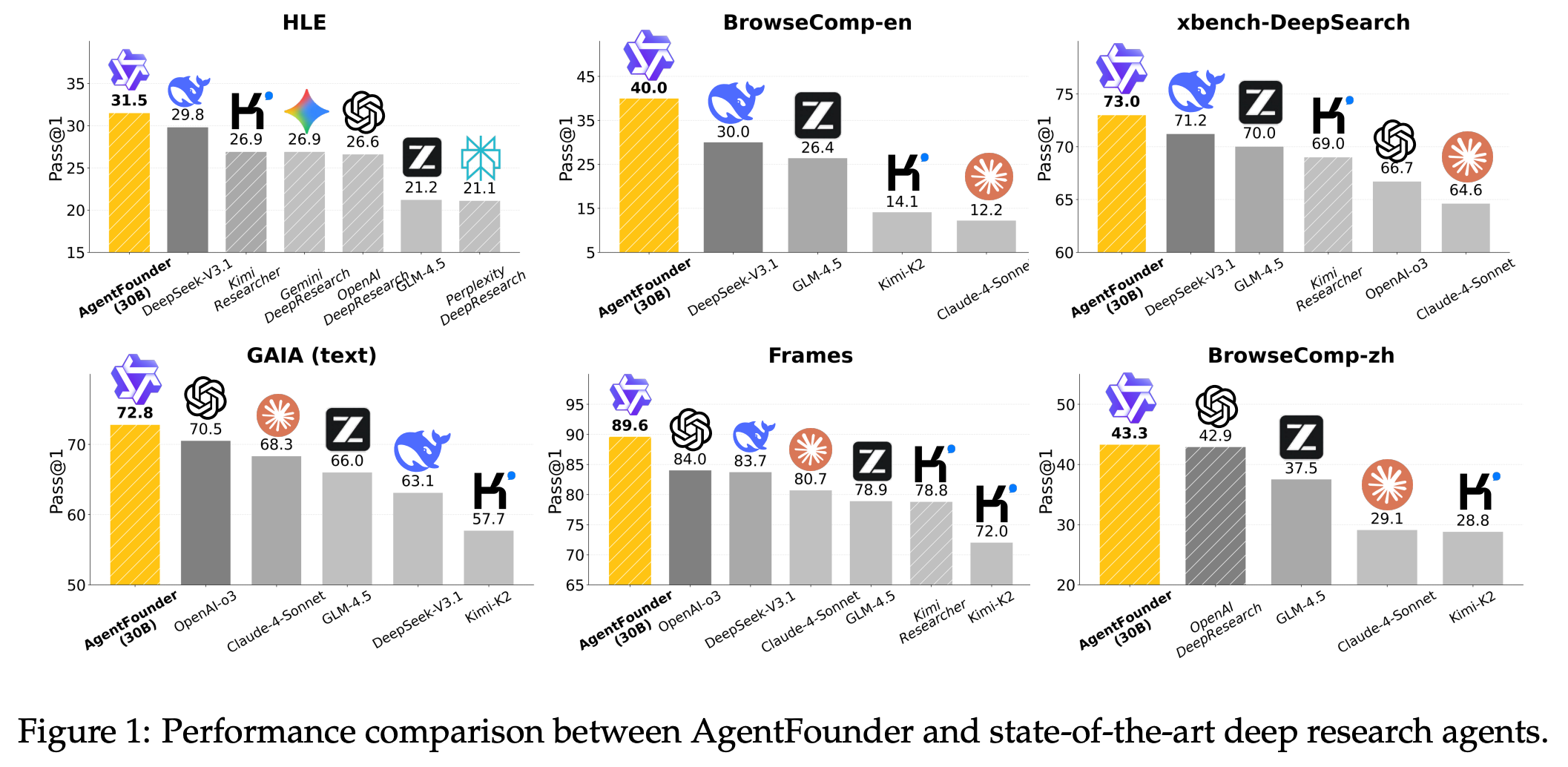
There’s a bottleneck in current open-source AI agents: they rely on general LLMs that weren’t explicitly trained for multi-step tool use, causing optimization conflicts during fine-tuning on agent tasks. To fix this, the authors introduce Agentic Continual Pre-Training (CPT) as an additional stage to produce a strong agent-focused foundation model before supervised or RL finetuning. They develop AgentFounder, a 30B-parameter LLM pre-trained on synthetic agent experiences, and report impressive results:
Agentic CPT Pipeline: By continually pre-training on large-scale synthetic agent data (generated via a data flywheel of tool-use records, knowledge, and Q&A pairs), the model acquires a broad capacity for reasoning and tool interaction prior to fine-tuning. This mitigates the “tug-of-war” where models previously had to learn tool use and align to demonstrations simultaneously.
AgentFounder Model: The resulting AgentFounder-30B is a powerful agentic foundation model. It retains strong tool-usage skills and, after light task-specific tuning, achieves state-of-the-art on 10 different agent benchmarks. For example, it scores 39.9% on the BrowseComp-English web search benchmark, 43.3% on BrowseComp-Chinese, and 31.5% Pass@1 on the challenging “Humanity’s Last Exam” (HLE) reasoning test.
Significance: This work demonstrates that adding a focused pre-training stage for agent behavior yields substantial gains. Open-source agent models can now rival or surpass proprietary agents on complex tool-using tasks, highlighting the importance of specialized continual pre-training for autonomous AI agents.
OmniWorld: A Multi-Domain and Multi-Modal Dataset for 4D World Modeling (paper/code)
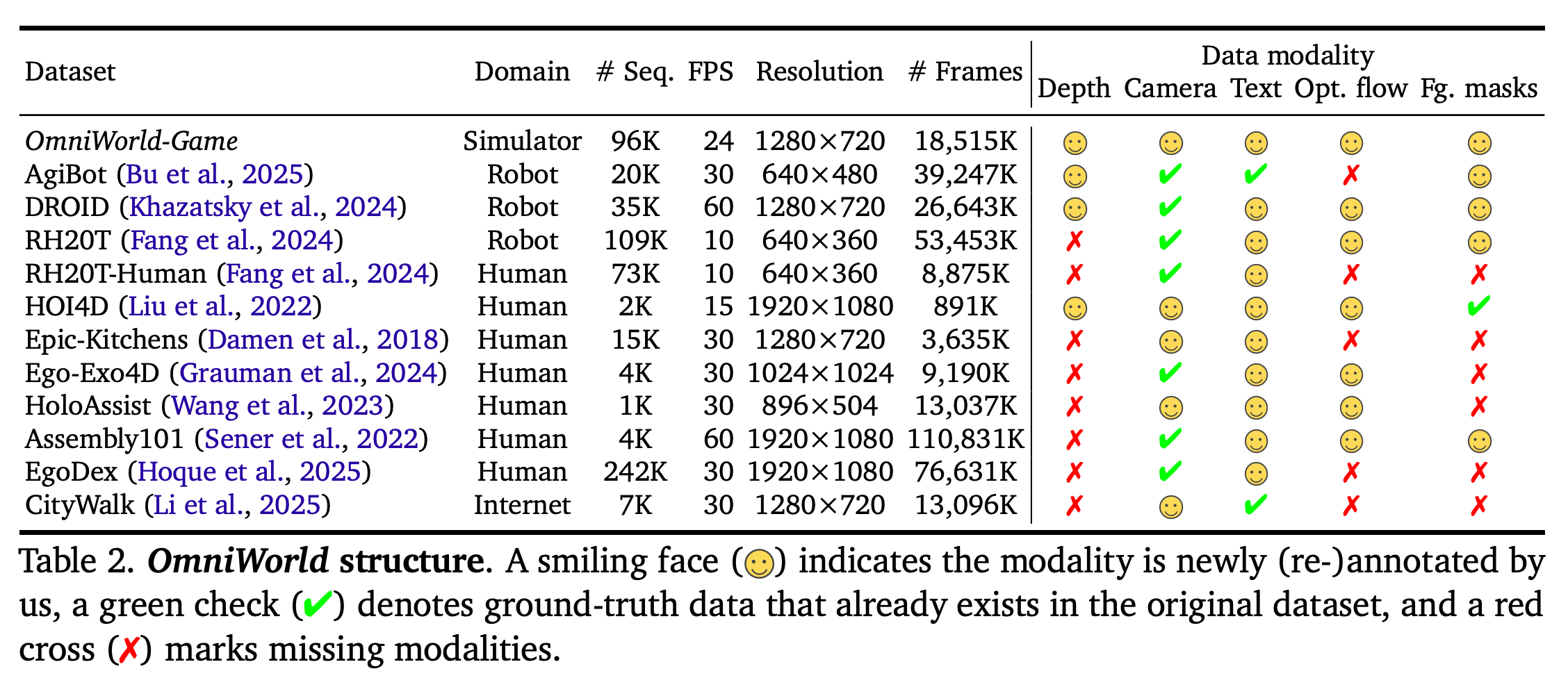
The researchers tackle a data scarcity problem in 4D world modeling – learning representations that capture 3D space and temporal dynamics together (think of tasks like reconstructing scenes over time or predicting future video frames). They introduce OmniWorld, a large-scale dataset spanning multiple domains and modalities to support training and evaluating 4D world models. Key features and findings:
Comprehensive 4D Dataset: OmniWorld consists of a newly created OmniWorld-Game simulation dataset plus several curated public datasets, together covering diverse domains (indoor scenes, outdoor environments, etc.). OmniWorld-Game is notably rich in modalities (e.g. RGB video, depth, events) and features realistic, dynamic interactions, exceeding prior synthetic datasets in scale and complexity.
Benchmarking 4D Modeling: Using OmniWorld, the authors define challenging benchmarks for tasks like 4D geometric reconstruction, future prediction, and camera-control video generation. These benchmarks reveal that many current state-of-the-art models struggle with the dataset’s complex, dynamic scenarios – highlighting gaps in generalization when confronted with OmniWorld’s multi-domain, time-evolving content.
Performance Gains with OmniWorld: Fine-tuning existing SOTA models on OmniWorld led to significant improvements on 4D tasks (better reconstruction accuracy, more coherent video generation). This validates OmniWorld as a valuable training resource: exposure to its varied and rich data helps models better grasp physical world dynamics. The authors envision OmniWorld will accelerate progress toward general-purpose 4D world models that understand our dynamic physical world in all its complexity.
QuantAgent: Price-Driven Multi-Agent LLMs for High-Frequency Trading (paper/code)
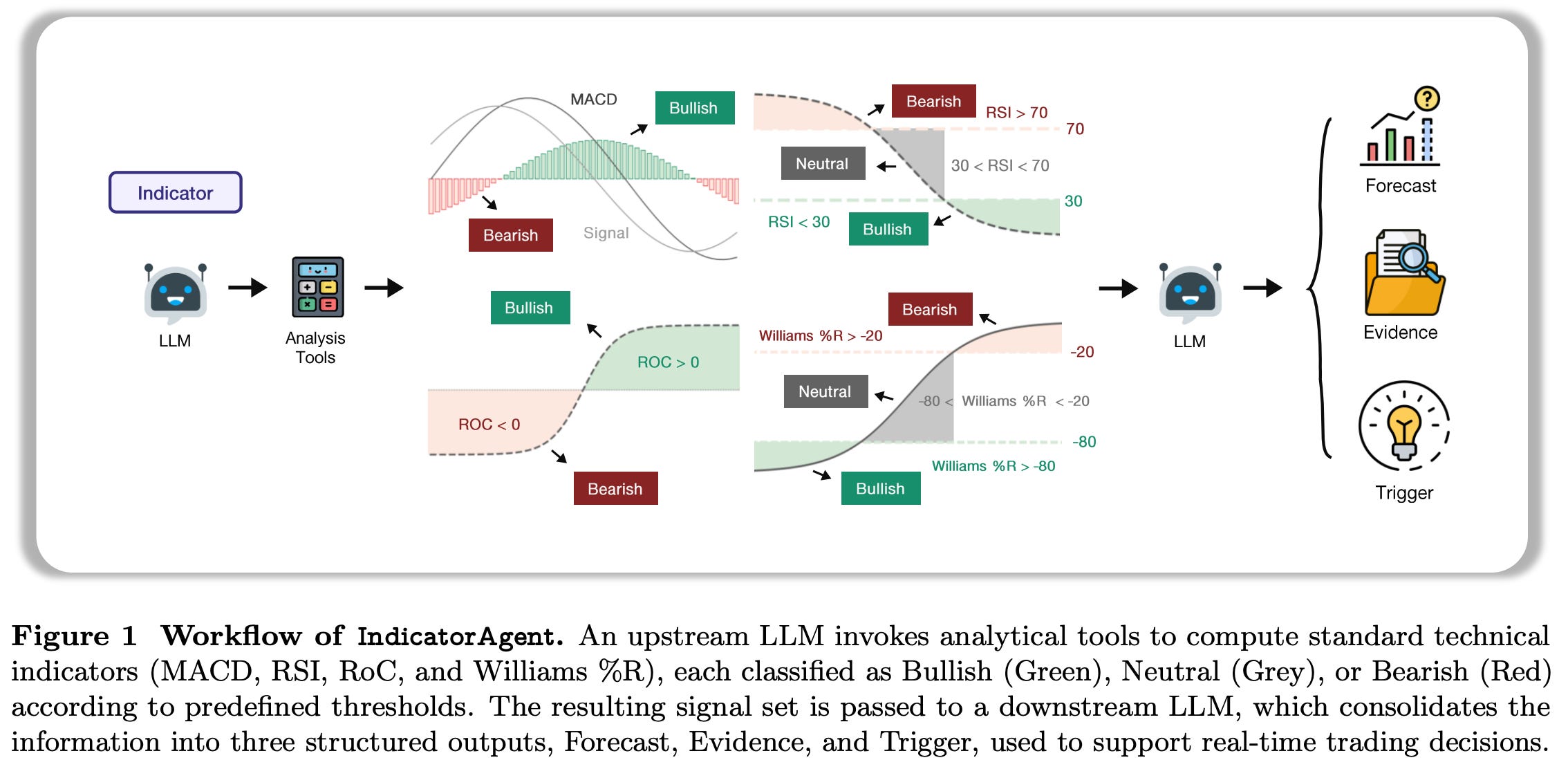
QuantAgent is a new application of LLM-based agents to high-frequency trading (HFT). Unlike typical financial LLM setups that analyze long-term fundamentals or news, HFT requires split-second, short-horizon decisions based on technical price signals. QuantAgent meets this need by deploying multiple specialized LLM agents, each focusing on a different aspect of market data, to collaboratively make trading decisions. Highlights:
Four Specialized Agents: The system breaks down the trading task into four expert LLM agents – Indicator, Pattern, Trend, and Risk. Each agent is equipped with domain-specific tools (e.g. analyzing technical indicators, chart pattern recognition, detecting short-term trends, risk management) and uses structured reasoning suited to its specialty. This modular design mirrors how human trading firms have different desks or algorithms for different strategies.
Real-Time, Short-Horizon Focus: By concentrating on structured short-term signals (like price patterns, indicator thresholds) rather than long textual analysis, QuantAgent can operate within 4-hour trading windows or shorter. This price-driven approach is tailor-made for HFT’s precision and speed demands – a departure from prior LLM trading agents that weren’t optimized for sub-day frequencies.
Outperformance in Zero-Shot Trading: In zero-shot evaluation on 10 different financial instruments (including Bitcoin and Nasdaq futures), QuantAgent outperformed strong baselines (both neural and rule-based) in predictive accuracy and cumulative returns. Its multi-agent architecture yielded better trading decisions than single-LLM or random strategies, showing the benefit of combining structured financial priors with language-model reasoning. These results suggest LLM agents, when properly structured, can deliver traceable, real-time decisions in high-speed financial markets.
Is In-Context Learning Learning? (paper/code)
Here’s an intriguing question: when an LLM performs in-context learning (ICL) – i.e. adapting to a new task via a prompt with a few examples, without updating weights – is it truly learning or just leveraging prior knowledge? The paper combines theoretical discussion and an extensive empirical analysis (nearly 1.9 million trials) to characterize ICL. Key insights include:
ICL as Implicit Learning: The author argues that mathematically, ICL can be viewed as a form of learning because the model’s outputs change in response to labeled examples in the context (it’s updating its function implicitly via the prompt). However, unlike standard learning, the model does not permanently encode new information; it “learns” transiently from context and heavily relies on its pretrained priors.
Empirical Limitations: Large-scale experiments (ablating memorization effects, controlling prompt distributions and phrasings) show that ICL is effective but quite limited in generalizing to truly unseen tasks. Often, the model is picking up on statistical regularities in the prompt rather than acquiring a deep new skill. For example, when numerous exemplars are given, the model’s accuracy becomes insensitive to prompt format or even which model is used, and instead hinges on patterns in the example distribution. This leads to brittleness – e.g. chain-of-thought style prompts can induce distributional quirks that hurt generalization.
Conclusion – Not Quite “Learning” Like Humans: Given the above, the paper concludes that ICL’s mechanism (next-token prediction with an ad-hoc context encoding) is not a robust, general-purpose learning method. Two tasks that look formally similar may see very different ICL performance, indicating the model hasn’t truly learned an abstract rule. In short, ICL works within limits, but it’s no substitute for true learning (where the model’s parameters update to capture new concepts). This nuanced finding tempers expectations about prompting alone solving novel problems.
DeepDive: Advancing Deep Search Agents with Knowledge Graphs and Multi-Turn RL (paper/code)
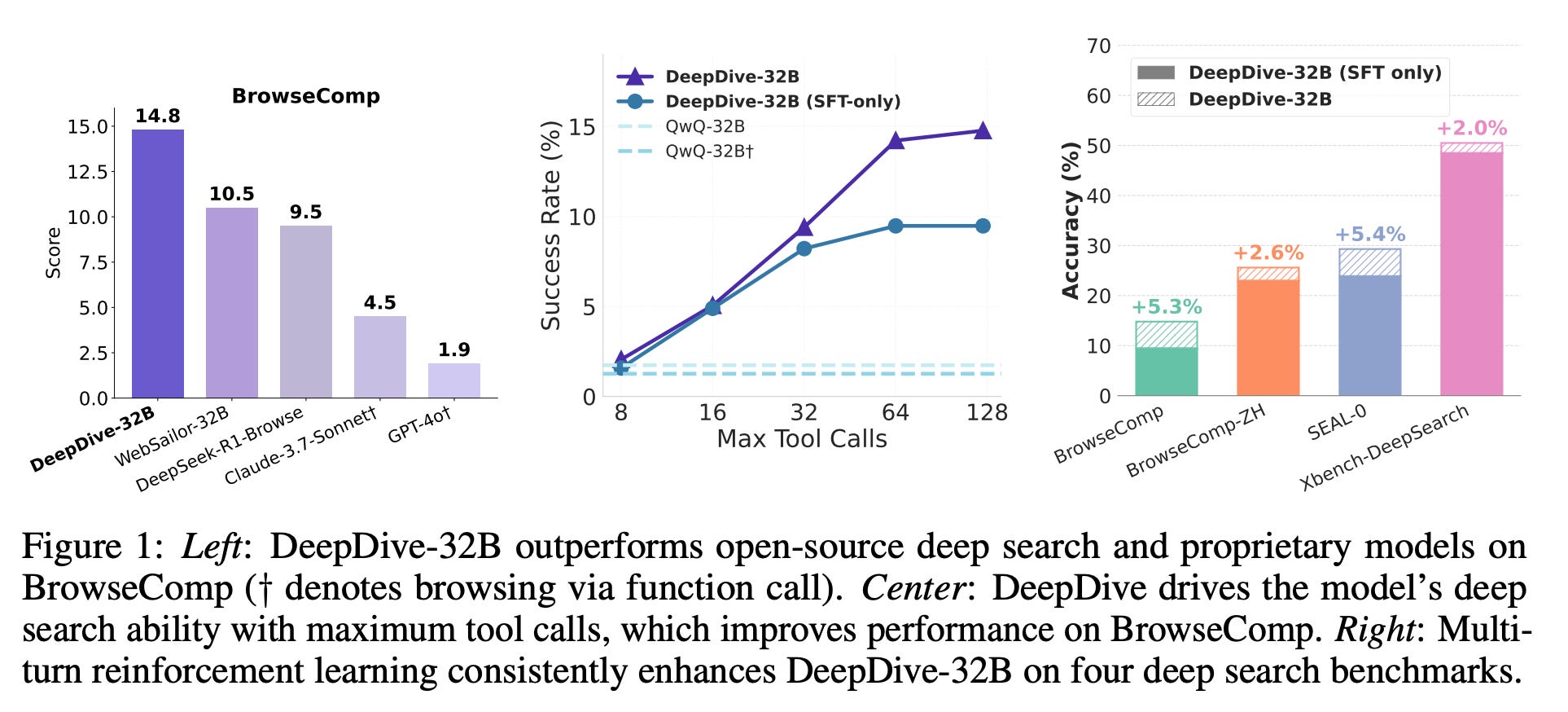
This work focuses on improving “deep search” AI agents – LLM-based agents that browse the web or knowledge bases to answer complex queries. Existing open-source agents struggle with long-horizon reasoning (handling multi-step search sessions) and often lack training data for truly hard queries. The DeepDive framework tackles both issues via synthetic data generation and reinforcement learning, yielding an agent that sets new records in open-domain web search tasks:
Synthetic Complex Query Generation: DeepDive automatically synthesizes difficult, multi-hop questions using open knowledge graphs. By traversing knowledge graph connections, it creates queries that require the agent to perform multi-step reasoning and find “hard-to-discover” information. This provides a large training corpus of challenging search tasks beyond what existing supervised data offers.
Multi-Turn Reinforcement Learning: Rather than rely solely on imitation learning, DeepDive applies end-to-end RL across multi-turn search sessions. The 32B-parameter agent is trained via reinforcement feedback to plan searches, utilize tools (like web browsers), and gather information over many turns – effectively learning to extend its reasoning horizon. This RL fine-tuning markedly improved the agent’s ability to handle complex information-seeking dialogues.
State-of-the-Art Results: The trained DeepDive-32B agent achieves a new open-source state-of-the-art on the BrowseComp benchmark (a suite of complex web queries). It outperforms previous open agents such as WebSailor and DeepSeek on these tasks. Notably, ablations show that the multi-turn RL training contributed significantly to the gains, demonstrating the value of training agents with actual search trajectories and feedback. DeepDive also enables practical enhancements like at test-time the agent can perform more tool calls in parallel to gather information efficiently. The code, models, and data are released, providing a foundation for future “deep search” agent development.
Understanding Outer Optimizers in Local SGD: Learning Rates, Momentum, and Acceleration (paper)

Ahmed Khaled et al. delve into the theory of Local SGD, a distributed training technique where multiple nodes perform local gradient steps and periodically synchronize. They focus on the often overlooked outer optimizer – the update rule applied when aggregating models from different nodes. While much research optimizes the local (inner) SGD settings, this work studies how the outer learning rate, momentum, etc., affect convergence. Major findings and contributions:
Role of Outer Learning Rate: The authors prove that tuning the outer-loop learning rate is crucial. A higher outer LR can amplify updates from the average of local models, whereas a lower LR dampens them. They show one can trade off final optimization error vs. noise from stochastic gradients by adjusting this LR. Interestingly, their theory suggests optimal outer LR can sometimes exceed 1.0 (i.e. overshooting the plain average) to counteract slow convergence or suboptimal inner settings. Moreover, a well-chosen outer LR can compensate for a poorly tuned inner LR – essentially correcting some mistakes made in local training.
Momentum and Acceleration in Outer Loop: Extending the analysis, they incorporate momentum in the outer optimizer and define an effective “momentum-adjusted” learning rate. The benefits are analogous: proper tuning of outer momentum can further smooth and accelerate convergence. They also examine Nesterov acceleration applied in the outer loop, proving that it improves convergence speed with respect to communication rounds. This is notable because prior accelerated schemes focused on local updates; accelerating the global updates yields better theoretical rates than purely local acceleration.
Data-Dependent Insights & Empirical Validation: The paper provides a novel data-dependent convergence analysis for Local SGD, offering practical guidance on setting the outer LR based on properties like data heterogeneity. Finally, experiments training standard language models across distributed nodes confirm the theoretical predictions. For instance, using a larger-than-1 outer LR or adding outer momentum matched the expected improvements in convergence speed and final accuracy, validating that careful outer optimizer design can significantly enhance distributed training efficiency.
Wrap-Up
From the first two works, we see a concerted push to build more general and capable agents by scaling up their training environments and pre-training regimes – enabling smaller open models to match the performance of massive closed models in complex, tool-using tasks. In parallel, the OmniWorld dataset underscores the importance of rich, diverse data for domains like 4D vision, where broader training data can unlock significant gains. We also witness LLMs being adapted to specialized domains: QuantAgent’s success in high-frequency trading shows that with domain-specific structuring, LLMs can handle real-time, high-stakes applications.
On the more fundamental side, research like “Is In-Context Learning Learning?” deepens our understanding of how models learn (or fail to) from context, guiding us on the limits of prompt-based “learning”. Enhancements in agent architectures (DeepDive) demonstrate the value of combining knowledge graphs and reinforcement learning to tackle long-horizon reasoning. Finally, theoretical breakthroughs in distributed optimization (outer optimizers for Local SGD) provide principled ways to speed up training on large-scale data. Together, this illustrates that advances in data, algorithms, and theory are converging to create more capable, efficient, and insightful AI systems. Each contributes a piece to the puzzle of building AI that is not only more powerful, but also better understood.