
⚙️ 3 Ways to Efficient AI
Supercharing LLMs to run faster than ever

In this issue:
Jacobi trajectories are all you need for decoding
Making long system prompts digestable
Unlocking the next level of LLM quantization

1. CLLMs: Consistency Large Language Models
Watching: CLLMs (paper)

What problem does it solve? The quest for efficiency in Large Language Model (LLM) inference has led to the exploration of parallel decoding methods, such as Jacobi decoding. Traditional autoregressive (AR) decoding, where each next token is predicted sequentially, can be time-consuming and computationally intensive. Parallel decoding attempts to break away from this bottleneck by predicting multiple tokens at once. However, Jacobi decoding hasn't been able to match the speed improvements it theoretically promises because it struggles to predict more than a single token per iteration step, which hampers its practical application.
How does it solve the problem? The approach presented addresses the limitations of Jacobi decoding by refining the LLM to better predict multiple future tokens from any given state. Essentially, they've retrained the model to more accurately converge on the final output (the fixed point) in a parallel manner, regardless of the starting point in the sentence. This method improves the efficiency of Jacobi decoding, as it encourages the model to make more accurate multi-token predictions in each fixed-point iteration step, leveraging the parallelizability potential of this decoding method.
What’s next? With a significant speedup of up to 3.4 times reported while maintaining the quality of generation, we're looking at a potential game changer for real-time applications that require fast output from LLMs. The integration of this enhanced Jacobi decoding technique into mainstream LLM frameworks could lead to broader adoption, further fine-tuning, and new improvements in model efficiency.
2. RelayAttention for Efficient Large Language Model Serving with Long System Prompts
Watching: RelayAttention (paper/code)
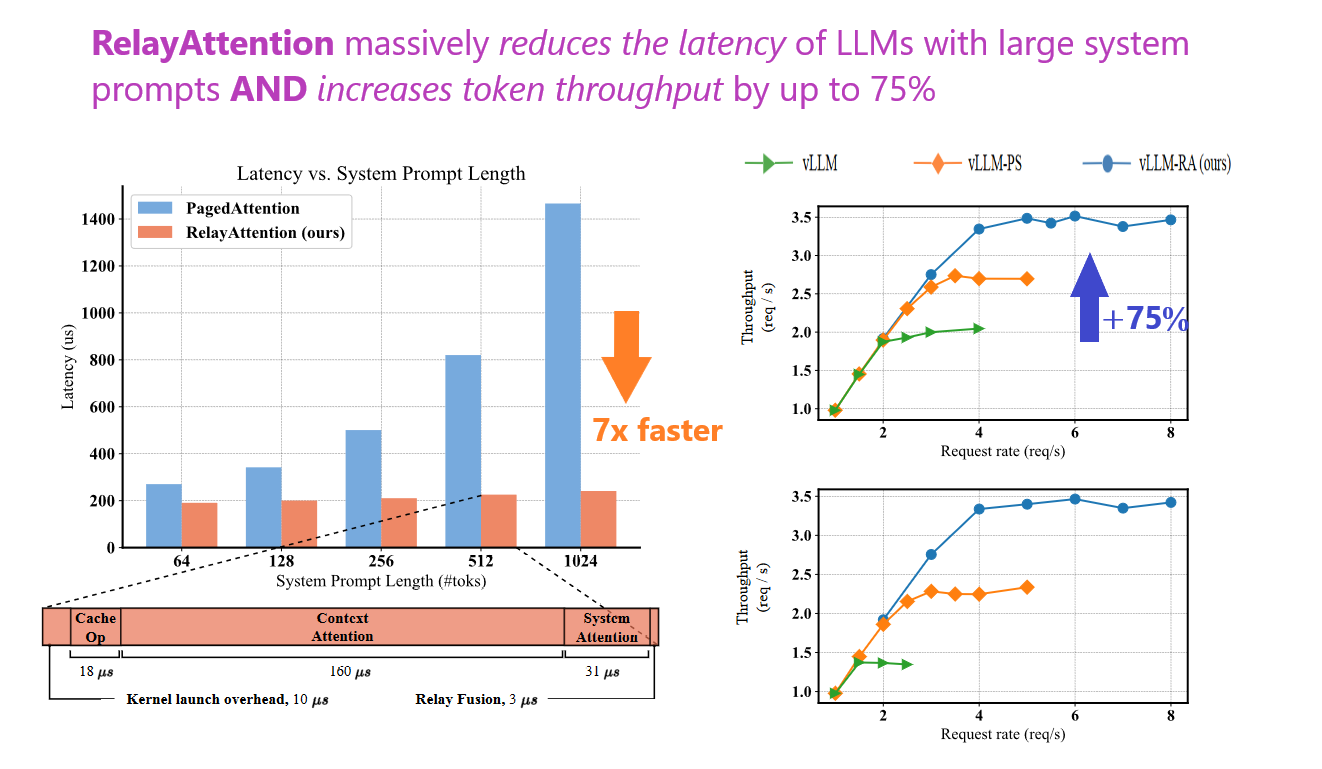
What problem does it solve? Efficiency is key in deploying Large Language Models (LLMs) effectively, especially when they are servicing multiple requests using lengthy system prompts that guide their responses. The issue at hand is that these long prompts increase the computational load, causing bottlenecks in throughput and latency due to the growing cost of generating new tokens as sequence length increases. This paper addresses the need to improve the efficiency of LLM services without compromising the quality of the generation when long system prompts are involved.
How does it solve the problem? The solution proposed is RelayAttention, an innovative attention algorithm. It identifies and targets the inefficiency in memory usage by existing causal attention computation algorithms that handle system prompts. The repeated memory access – transferring cached hidden states from off-chip DRAM to on-chip SRAM for multiple requests – is where RelayAttention steps in. Instead of multiple memory transfers, it allows for these hidden states to be read exactly once from DRAM for a batch of input tokens. This reduction in memory access redundancy not only optimizes efficiency but also ensures the maintenance of generation quality. The beauty of RelayAttention lies in its simplicity, as it is based on a mathematical reformation of the causal attention mechanism and does not require any model retraining.
What’s next? RelayAttention presents a promising leap forward in the operational efficiency of LLMs, especially for those involving system-intensive tasks. Since it can be integrated without modifying the model itself, one could expect rapid adoption and potential widespread application in LLM services. Moreover, as the code has been made publicly available, the next step could see RelayAttention being tested and optimized further by the LLM community.
3. GPTVQ: The Blessing of Dimensionality for LLM Quantization
Watching: GPTVQ (paper)
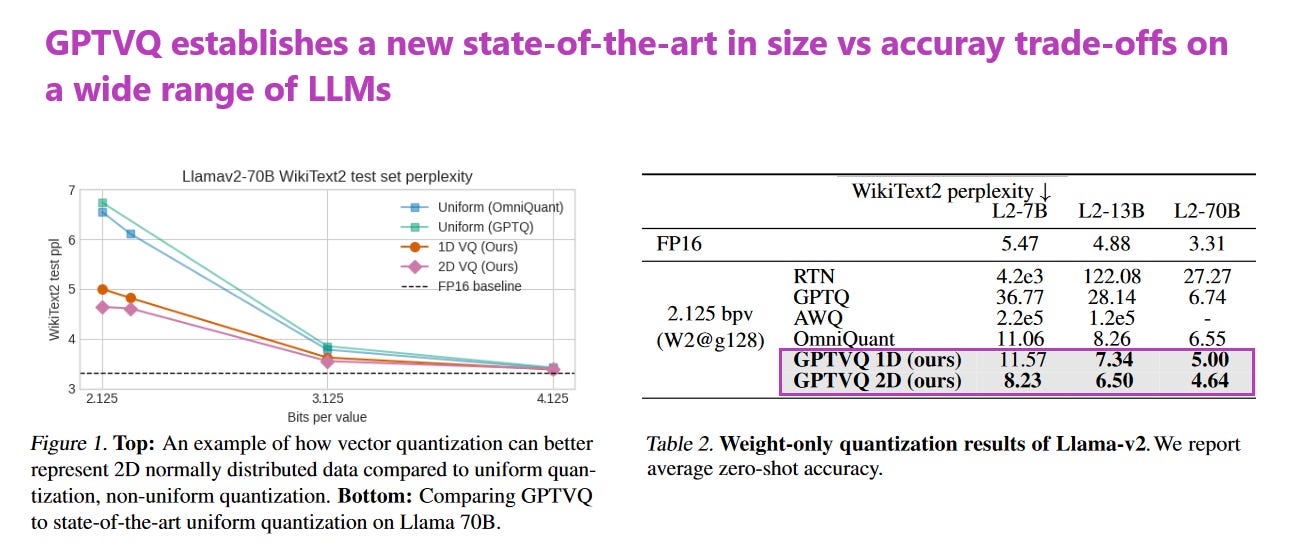
What problem does it solve? Large Language Models (LLMs) are known for their impressive accuracy in various tasks, but they come with a large size that makes deploying them quite challenging, particularly on devices with limited memory or computing power. A common approach to reduce the size of these models without significantly compromising their performance is neural network quantization. However, this often leads to a trade-off between the model's size and its accuracy. The innovative GPTVQ method strives to improve this trade-off by employing a more sophisticated vector quantization (VQ) technique that maintains model performance while substantially reducing the model size.
How does it solve the problem? GPTVQ improves size versus accuracy balance in LLMs through an advanced post-training vector quantization process which scales effectively. It skillfully interleaves the quantization of selected weights with updates to the remaining weights, guiding the process with information from the model's Hessian matrix, which is related to the output reconstruction's mean square error. By using a data-aware Expectation-Maximization (EM) algorithm for initializing quantization codebooks and then applying SVD-based compression and integer quantization, GPTVQ efficiently produces compressed models. This approach results in a lower memory footprint without a substantial loss in accuracy.
What’s next? With promising results from GPTVQ, demonstrating superior size versus accuracy trade-offs, there is a clear path forward for further refining and optimizing quantization techniques for LLMs. Future work may involve optimizing this method for other types of neural networks or integrating it into larger pipelines where resource constraints are stringent. As the need for deploying powerful models on edge devices grows, GPTVQ and its successors could help making AI more accessible and pervasive.
Papers of the Week:
MathScale: Scaling Instruction Tuning for Mathematical Reasoning
FinReport: Explainable Stock Earnings Forecasting via News Factor Analyzing Model
Privacy-preserving Fine-tuning of Large Language Models through Flatness
Knowledge-to-SQL: Enhancing SQL Generation with Data Expert LLM
Benchmarking the Text-to-SQL Capability of Large Language Models: A Comprehensive Evaluation
Benchmarking Hallucination in Large Language Models based on Unanswerable Math Word Problem