
11 Papers You Should Know About
Ahead of the curve with LLM Watch
Welcome, Watcher! This week in LLM Watch:
Why self-evolving agents might be the real path to ASI (not just bigger models)
How reflective language beats reinforcement learning by 35x efficiency
When hybrid architectures demolish compute-performance trade-offs
Don't forget to subscribe to never miss an update again.
Quick Glossary (for the uninitiated)
ASI (Artificial Super Intelligence): AI that surpasses human intelligence in all domains - the hypothetical next stage after AGI where machines outthink us at everything
MoE (Mixture of Experts): An architecture where different specialized sub-models handle different inputs - like having a team of specialists instead of one generalist
SSM (State Space Model): An efficient alternative to Transformers for processing sequences - think of it as a streamlined way to remember context
GraphRAG: Retrieval-Augmented Generation using knowledge graphs - like giving AI a structured map of information instead of just a pile of documents
Knowledge hypergraphs: Advanced data structures where connections can link multiple nodes at once - like mind maps on steroids
MCP (Model Context Protocol): A standardized way for AI agents to interact with tools and external systems - like USB for AI connections
1. A Survey of Self-Evolving Agents: On Path to Artificial Super Intelligence
Watching: Self-Evolving Agents (paper/repo)
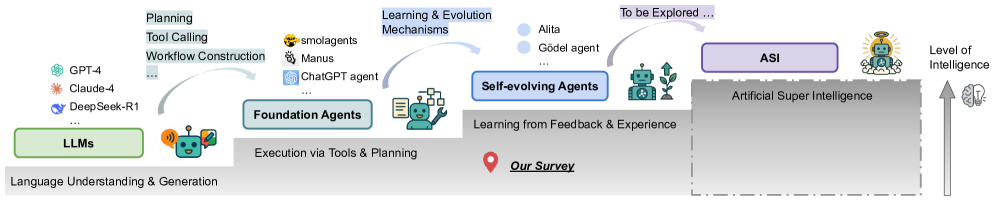
What problem does it solve? Large language models today are powerful but fundamentally static, unable to update their knowledge or skills once trained. When deployed in open-ended environments, this rigidity becomes a serious bottleneck – the AI cannot adapt to new tasks, evolving information, or dynamic interactions. This survey identifies the shift from static LLMs to self-evolving agents as crucial for breaking that bottleneck. In essence, the problem is how to build AI systems that can learn and improve continuously in real time, rather than remaining fixed after pre-training.
How does it solve the problem? The authors provide the first comprehensive roadmap for building adaptive, self-improving AI agents. They organize the vast literature (1,400+ papers) around three foundational dimensions of evolution: what to evolve (which components, e.g. the model’s parameters, memory, or tool use), when to evolve (during or between tasks), and how to evolve (the algorithms or feedback that drive learning). They examine mechanisms that allow an agent to update itself – from modifying its neural weights, to expanding toolsets or adjusting its architecture – and classify these by whether adaptation happens on the fly during a task or in between episodes. The survey also reviews how to give agents richer feedback beyond sparse rewards (like using textual self-reflection or multi-agent critiques) and covers evaluation benchmarks and domains (coding, education, healthcare) where self-evolving agents are being tested.
What are the key findings? A major takeaway is that designing self-evolving AI requires integrating techniques from across subfields into a unified framework. Successful agents will need to coordinate multiple forms of learning – e.g. updating memory modules, adjusting plans, and fine-tuning skills – all under principled control of when and how to apply each. The survey highlights that recent systems already demonstrate pieces of this puzzle (like agents that update via textual feedback or share knowledge in a team), but we lack a standard toolbox for making them reliably adaptive. It also identifies open challenges: ensuring safety (so an agent doesn’t evolve undesired behaviors), achieving scalability (so learning on the fly doesn’t require prohibitive compute), and handling co-evolution in multi-agent settings. By synthesizing lessons across studies, the authors deliver a structured understanding of what’s been achieved and what gaps remain on the path toward truly self-improving AI.
Why does it matter? This work essentially charts the path toward AI that can continuously learn, a key stepping stone toward more general and autonomous intelligence. Instead of repeatedly retraining models offline for new abilities, future AI agents might evolve on the job, much like humans do by learning from experience. Such agents could remain state-of-the-art without constant human intervention, adjusting to new information and tasks as they emerge. In the long run, the survey’s vision of self-evolving agents paints a route to systems that inch closer to Artificial Super Intelligence, by operating at or beyond human-level capability across many tasks through ongoing self-improvement. For practitioners and researchers, this roadmap provides concrete guidance on building AI that doesn’t plateau – it adapts, optimizes itself, and potentially, gets better with each interaction.
2. Kimi K2: Open Agentic Intelligence
Watching: Kimi K2 (paper/model)
What problem does it solve? The performance gap between proprietary AI giants and open-source models remains a significant hurdle – especially for “agentic” tasks where an AI must plan, act, and reason with tools or environments. Kimi K2 tackles this by pushing open-source LLMs to unprecedented scale and capability. Training ultra-large models is notoriously unstable (loss spikes, divergence) and costly. Moreover, imbuing an LLM with agent-like abilities (the kind needed to interact with environments) typically requires complex fine-tuning that few open projects have achieved. In short, the problem addressed here is how to build an open model that is both massive in scale and skilled in agentic reasoning, without falling prey to training instabilities or closed data.
How does it solve the problem? Kimi K2 introduces a Mixture-of-Experts (MoE) architecture with a staggering 1 trillion parameters (of which 32 billion are “active” per token). This MoE design allows scaling the model’s capacity without a proportional increase in computation for every token. To overcome training instability, the team developed a new optimizer called MuonClip (improving on the Muon optimizer) that uses a novel QK-clip technique to prevent the divergence issues that often occur in MoE training. With this, they successfully pre-trained Kimi K2 on an immense 15.5 trillion tokens without any loss spikes. After pre-training, they didn’t stop at a generic model – they put K2 through a multi-stage post-training regimen. This included a large-scale agentic data synthesis (generating diverse scenarios requiring tool use and reasoning) and a joint reinforcement learning stage where K2 interacted with both real and simulated environments to improve its decision-making. In essence, Kimi K2 was taught not just to predict text, but to behave as an agent, refining its skills via trial-and-error feedback.
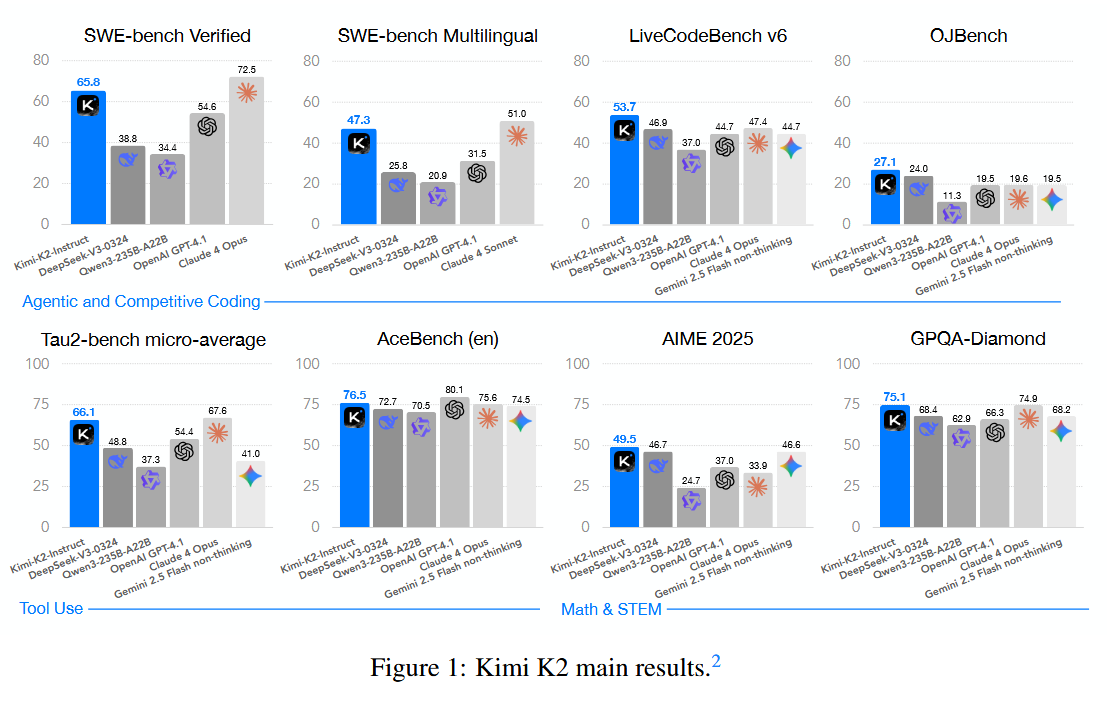
What are the key findings? Kimi K2 now stands as one of the most capable open-source LLMs to date. Thanks to its scale and training, it achieves state-of-the-art results among open models across a variety of benchmarks. Notably, it excels in what the authors call "non-thinking" (direct response) settings: for example, it scored 66.1 on the Tau2 reasoning benchmark and 76.5 on ACE (English) – outperforming most existing open and even closed models when they’re not allowed to use chain-of-thought prompting. It also shows strong prowess in domains like coding and math, with a 53.7% on LiveCode (code generation) and 49.5% on the AIME 2025 math test. These figures are significant improvements, often surpassing models many times its size. Equally important, K2’s training pipeline proved that interactive fine-tuning (through environment interactions) measurably boosts an LLM’s problem-solving abilities. The model’s releases include both the base 1T-parameter checkpoint and a further post-trained checkpoint, giving the community a powerful new foundation to experiment with.
Why does it matter? Kimi K2’s success is a milestone for the open AI ecosystem. It demonstrates that open-source researchers can not only reach the trillion-parameter scale, but also instill advanced reasoning and agentic behaviors that were previously seen only in flagship proprietary models. In practical terms, an open model with these capabilities lowers the barrier for a wide range of applications – from complex coding assistants to autonomous research agents – without needing API access to a closed AI. The innovations in training (like MuonClip) may also benefit others working on large models, making it easier to train huge systems reliably. More broadly, Kimi K2 validates a paradigm: by combining massive scale with targeted agentic training, we can produce AI that is both broadly knowledgeable and able to apply that knowledge in multi-step, interactive contexts. It’s a step toward AI that not only contains facts and skills, but can deploy them autonomously in pursuit of goals – and it’s all happening in the open.
3. Flow Matching Policy Gradients
Watching: Flow Matching (paper/code)

What problem does it solve? In reinforcement learning for continuous control (think robotics or game physics), policies are usually represented with simple probability distributions (typically Gaussians) that struggle with multi-modal decisions. For example, if there are two very different yet equally good ways to achieve a goal, a Gaussian policy tends to average them into a mediocre single mode. Recent advances in generative modeling – like diffusion models – can represent complex, multi-modal distributions, but integrating them into RL has been awkward. Prior attempts to use diffusion models in RL required fixing a specific sampling procedure or calculating exact probabilities at every step, which is cumbersome and can limit performance. So the core problem is how to train an RL agent that can leverage the expressive power of diffusion/flow-based models for its action decisions without complicating the training process or being tied to a single sampling method.
How does it solve the problem? The authors propose Flow Policy Optimization (FPO), an on-policy RL algorithm that marries diffusion-like flow modeling with standard policy gradients. In essence, they recast the policy learning objective as a flow matching problem: instead of directly maximizing expected reward, FPO trains the policy by matching the “probability flow” of an optimal policy. Concretely, they derive an update rule that maximizes the advantage-weighted geometric mean of probabilities (rather than arithmetic mean), aligning with a conditional flow matching loss. This approach slots neatly into the popular PPO (Proximal Policy Optimization) framework – they even use a PPO-style clipping mechanism to keep updates stable. The key innovation is that FPO doesn’t require computing exact likelihoods for diffusion model outputs at every step (bypassing a major hurdle). It also treats the choice of diffusion sampler as a plug-and-play detail, meaning the training isn’t handcuffed to any particular way of generating samples. The authors implement FPO and train diffusion-based policies from scratch on classic continuous control tasks (like locomotion and manipulation), effectively turning those tasks into a playground for generative models to act as agents.
What are the key findings? Flow Matching Policy Gradients prove remarkably effective. The diffusion-style policies learned via FPO can capture rich, multi-modal action distributions that a traditional Gaussian policy simply couldn’t express. In practical terms, on several benchmark tasks the FPO-trained agents achieved higher rewards than baseline methods. They particularly shine in scenarios with ambiguity (so-called under-conditioned settings, where the optimal action isn’t uniquely determined by the state) – here, the ability to represent multiple likely futures gives the agent an edge. Another notable finding is that this performance gain comes without sacrificing stability; the training curves are smooth, thanks to the built-in clipping and the robustness of using a geometric mean objective. By comparing to prior diffusion-in-RL approaches, the authors show that FPO’s agnosticism to sampler and avoidance of exact likelihood calculations make it more flexible and broadly applicable. All told, the results indicate that advanced generative models can be plugged into RL frameworks to significantly improve policy quality.
Why does it matter? FPO is a cross-disciplinary breakthrough that bridges the gap between two evolving fronts of AI: generative modeling and decision-making. For the RL community, it opens the door to a new class of agents that don’t have to choose one action when they can prepare for many – which could be crucial for complex tasks like self-driving, where multiple responses might be viable. The method is also noteworthy for improving efficiency: by better matching the true landscape of optimal actions, an FPO agent may require fewer trial-and-error iterations to learn good strategies. More philosophically, this work hints at a future where techniques from diffusion models (designed for images and text) help create smarter policies for robots and autonomous systems. It’s a reminder that as AI systems become more general, ideas from different subfields will combine to overcome each other’s limitations. Here, the precision of reinforcement learning meets the creativity of generative models – and the outcome is an agent that can genuinely do more by considering a wider space of possibilities when deciding how to act.
4. GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
Watching: GEPA (paper)
What problem does it solve? Fine-tuning LLMs for new tasks often relies on reinforcement learning (RL) with very sparse feedback – a model generates an answer and gets a single reward (right or wrong). Methods like GRPO (Group Relative Policy Optimization) can align LLMs to tasks but are painfully sample-inefficient, sometimes needing thousands of trial-and-error episodes to see improvement. Moreover, using only a scalar reward misses all the nuanced reasons why an answer was wrong, which the model might infer if given the chance. The problem, then, is how to adapt an LLM to a task faster and more richly than traditional RL, possibly by leveraging the model’s own understanding (since outputs are language, the model could analyze them) instead of treating it like a black-box policy that only sees rewards.
How does it solve the problem? GEPA introduces a new paradigm of reflective prompt evolution. Instead of adjusting model weights via gradients, GEPA keeps the model fixed and optimizes the prompts and instructions given to it. It works like a scientist running experiments: for a given task, GEPA has the LLM attempt the task (producing reasoning traces, tool calls, etc.), then it has the LLM reflect in natural language on those attempts – identifying errors or inefficiencies in its reasoning. Based on this self-critique, GEPA generates proposed modifications to the prompts (or chain-of-thought guidelines). It doesn’t rely on a single brainstorm: it produces a diverse set of candidate prompts and uses a Genetic-Pareto strategy to combine the best parts of different candidates. In other words, it’s performing natural language evolution: each “generation” consists of the model analyzing its failures and mutating the prompt to address them. This process can turn even a handful of task rollouts into substantial quality gains, because each rollout yields a wealth of information (the model’s own commentary) rather than just a win/lose signal.
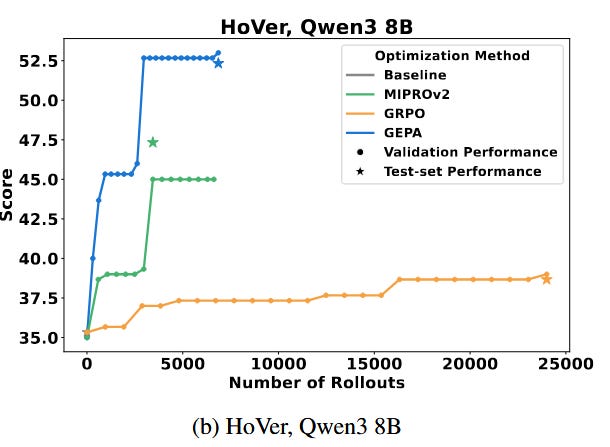
What are the key findings? GEPA dramatically outperforms traditional RL fine-tuning in both effectiveness and efficiency. Across four different tasks, it achieved on average a 10% higher success rate than a strong RL baseline (GRPO), and in some cases up to 20% higher. Crucially, it did so using far fewer trials – up to 35× fewer rollouts – meaning it squeezed much more learning out of each attempt. It also beat the previous state-of-the-art prompt optimization method (MIPRO v2) by over 10% on shared benchmarks. Qualitatively, the prompts evolved by GEPA were found to encode high-level “rules” and insights (often expressed in plain English) that helped the model avoid specific pitfalls. For example, on a coding task, GEPA might add a reminder like “first check for edge cases such as null inputs,” which an RL reward alone would never explicitly give. Another interesting finding is that GEPA’s approach can serve as an online strategy: the authors demonstrated it improving a model’s outputs on the fly during inference, by iteratively refining the prompt for each new problem. This blurs the line between training and usage – the model is essentially self-improving in real time by rewriting its own instructions.
Why does it matter? GEPA’s success hints at an alternative (or complement) to reinforcement learning for aligning and enhancing LLMs. Instead of treating the model as a reinforcement learner that must be coaxed with numeric rewards, GEPA treats the model as a reasoner that can read and write its own improvement instructions. This approach can be far more data-efficient (as seen by the 35× reduction in needed trials) – an important practical advantage when each trial might involve costly API calls or human evaluations. It’s also more interpretable: we end up with an improved prompt that humans can read and understand, rather than a mysterious set of weight changes inside the model. For the field of AI, this work underscores the power of letting models “think about their thinking.” By using the medium of language, GEPA shows that LLMs can leverage their internal knowledge to correct themselves, which is a step toward autonomous self-correction in AI systems. In a broader sense, it exemplifies a trend of language-native optimization: using the model’s own natural outputs (explanations, reflections) as feedback, which could be applied to many domains beyond these tasks. If LLMs can continue to refine their behavior through such reflective loops, we might achieve robust performance gains without always resorting to brute-force reinforcement signals.
5. Falcon-H1: A Family of Hybrid-Head Language Models Redefining Efficiency and Performance
Watching: Falcon-H1 (paper/code)
What problem does it solve? Bigger isn’t always better – especially if you can barely run “bigger.” The AI community has wrestled with the trade-off between model size and practicality. Enormous transformer models deliver great performance but at enormous computational cost, while smaller models run efficiently but often lag far behind in ability. Another challenge is context length: standard transformers struggle to handle very long inputs due to their quadratic scaling. Falcon-H1 directly addresses how to get more bang for your parameter buck – achieving top-tier performance at a fraction of the model size, and doing so with much longer context windows than usual. In short, the problem is designing an architecture that can match or exceed the performance of models double or quadruple its size, while also being memory- and runtime-efficient (and extending to long contexts), something that could hugely benefit deployments on limited hardware.
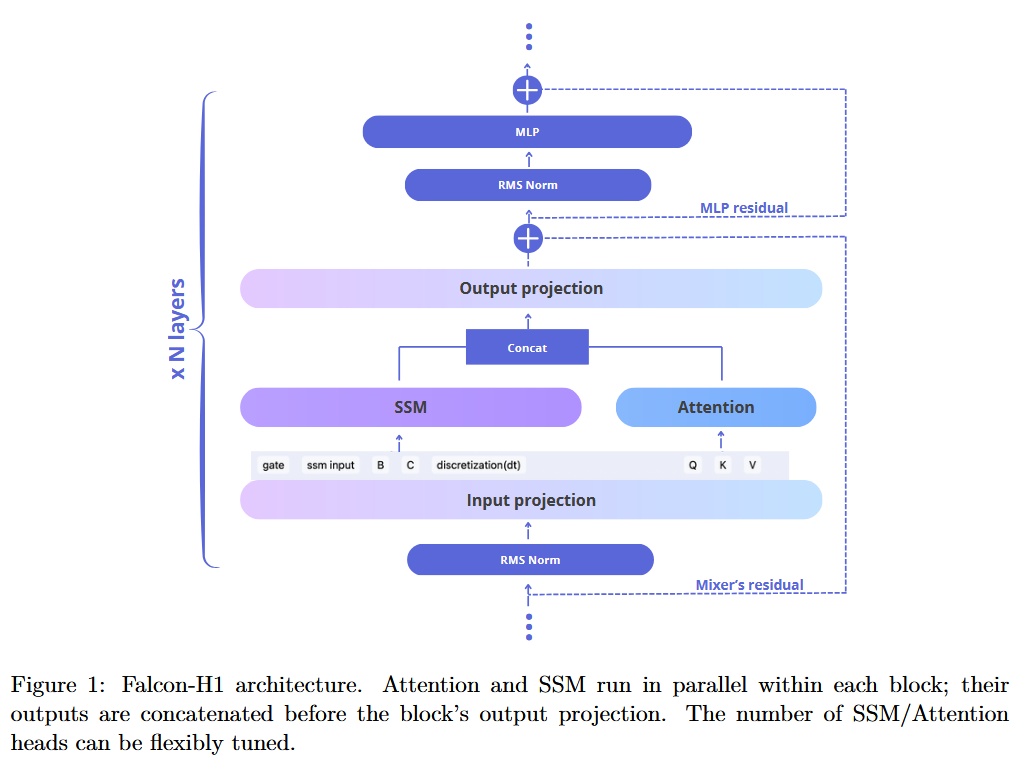
How does it solve the problem? The team behind Falcon-H1 took a bold hybrid approach. Instead of using a pure Transformer like most LLMs, Falcon-H1 combines Transformer-based self-attention with State Space Model (SSM) components in a parallel “dual head” architecture. SSMs (inspired by models like S4) are known for handling long sequences with linear computational complexity and providing superior long-term memory. By integrating SSM layers alongside traditional attention, Falcon-H1 leverages the strengths of both: attention for complex short-term dependencies and SSM for efficient long-range processing. They didn’t stop at architecture – the designers revisited everything from model depth to training data strategy to optimize for efficiency. Falcon-H1 comes in a spectrum of sizes (base and instruction-tuned variants at 0.5B, 1.5B, 3B, 7B, and 34B parameters, plus a special “1.5B-deep” version). Notably, all models support a context window up to 256k tokens – orders of magnitude beyond typical limits – enabled by the SSM component managing long-term memory. They also released many models in quantized form (int8) for easy deployment, totaling over 30 checkpoints on HuggingFace. The entire suite is open-source under a permissive license, meaning anyone can use or fine-tune them without heavy restrictions.
What are the key findings? Falcon-H1 models deliver state-of-the-art results with drastically fewer parameters than competitors. The flagship 34B model matches or outperforms models in the 70B parameter range on a wide array of benchmarks. For instance, it’s reported to either match or beat recent open models like Qwen2.5-72B and even a hypothetical Llama3-70B on tasks spanning reasoning, math, multilingual understanding, and following instructions. Impressively, the efficiency gains hold at smaller scales too: the Falcon-H1-1.5B-Deep model (an enhanced 1.5B parameter model) is on par with many 7B–10B models from just last year, and the tiniest Falcon-H1 0.5B model performs comparably to older 7B models from 2024. These are huge leaps in the price/performance ratio of language models. Beyond raw accuracy, the long-context capability stands out: the models can handle inputs like entire books or multi-day dialogues (up to 256,000 tokens) without external memory tricks, something practically unheard of in this space. This suggests they maintain coherence and understanding over extremely lengthy texts, which the evaluation confirms with strong performance on long-form and multi-turn tasks. An important aspect is that all these gains come with no proprietary data or code – Falcon-H1’s advancements are a testament to clever architecture and training, not just secret sauce. The release underlines that through innovation, open models can rival or even surpass the giants.
Why does it matter? Falcon-H1 marks a significant step towards making powerful AI more accessible. By achieving top performance at smaller model sizes, it means organizations and researchers with limited compute can deploy or fine-tune models that previously were out of reach. This democratization is bolstered by the open license – anyone can build on Falcon-H1 for their applications. The hybrid Transformer-SSM approach also pioneers a path forward for model design: rather than blindly scaling up, we can scale smarter. Long contexts of 256k tokens open up new application domains – imagine AI models that can read and analyze hundreds of pages of text or code in one go, enabling deep analysis in finance, law, or literature without chopping the input. In essence, Falcon-H1 suggests that the era of solely chasing parameter count is waning; optimization of architecture and training can yield “size-efficient” models that are just as capable. For the field, it’s a proof-of-concept that blending different sequence modeling paradigms (like attention and SSM) can overcome limitations neither could solve alone. Expect to see more hybrids in the future, as others build on Falcon-H1’s recipe to push AI toward being faster, leaner, and yet even more powerful.
6. EDGE-GRPO: Entropy-Driven GRPO with Guided Error Correction for Advantage Diversity
Watching: EDGE-GRPO (paper)
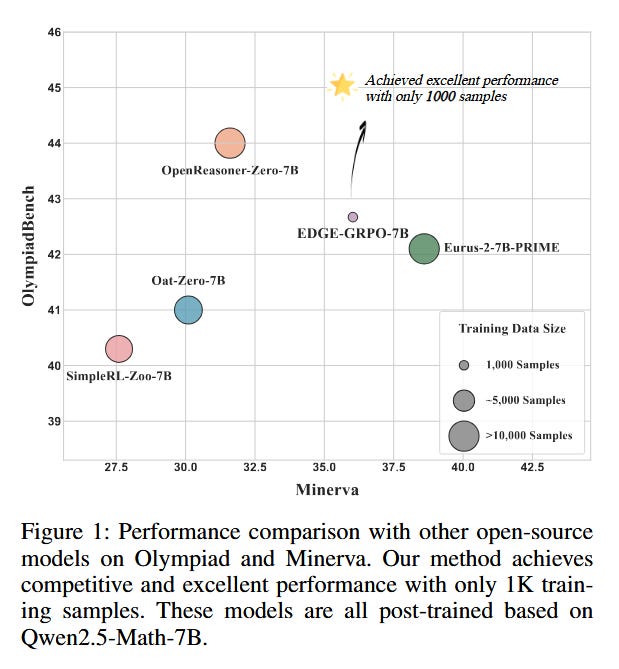
What problem does it solve? Recent methods like GRPO have improved LLM reasoning by using reinforcement learning on reasoning traces, but they hit a nasty snag: advantage collapse. In GRPO, model outputs are grouped and only the best group gets a reward – if multiple different answers all earn the same (e.g. zero) reward, the algorithm can’t tell which direction is better to update towards. Essentially, the learning signal within each group collapses to nothing, making it hard for the model to improve especially on challenging tasks where it initially gets everything wrong. This leads to stagnation: the policy doesn’t learn nuanced differences between a terrible answer and a almost-correct answer, since both get labeled “0”. Prior approaches tried to fix this by forcing more diverse answers (so that maybe one of them gets a reward) or by adding extra internal feedback signals, but these had limitations. The fundamental problem remains: how to preserve informative gradient signals even when explicit rewards are sparse or identical for many samples, so that the model continues to learn rather than plateauing.
How does it solve the problem? EDGE-GRPO introduces two key innovations to keep training signals rich: Entropy-Driven Advantage and Guided Error Correction (hence the acronym EDGE). The entropy-driven advantage means the algorithm uses the model’s own confidence (entropy of its output distribution) as part of the advantage computation. Intuitively, if the model is very unsure (high entropy) versus very confident (low entropy) about an answer, EDGE-GRPO will treat those cases differently even if both got the same final reward. This helps avoid the case where all bad answers look equally bad – a hesitant wrong answer might be penalized differently than a confidently wrong answer, encouraging the model to learn to be confidently correct. The guided error correction component involves providing targeted feedback or updates for wrong answers specifically. While the paper’s details are technical, the concept is that the training process actively corrects errors by nudging the model in the direction of known-good reasoning steps (possibly through an auxiliary reward for making certain improvements or via human-provided hints integrated into the reward). Together, these mechanisms ensure that even within a group of responses that all fail, there is gradient diversity – some responses get a bit more advantage than others based on their entropy or partial progress, and the model receives guidance on how to fix its mistakes beyond just “try again.”
What are the key findings? By attacking advantage collapse at its root, EDGE-GRPO achieves more stable and improved training outcomes on several challenging reasoning benchmarks. The paper reports that models trained with EDGE-GRPO steadily increase their reasoning scores where baseline GRPO would often flatline. One striking observation: after EDGE-GRPO training, the model’s correct answers tend to have lower entropy (i.e. the model is more confident and decisive) while its incorrect attempts remain high-entropy (the model expresses uncertainty when it’s likely wrong). This is a desirable trait – it means the AI knows when it knows something, and hesitates when it doesn’t, which is important for trustworthiness. In terms of raw performance, EDGE-GRPO-trained models outperformed their vanilla GRPO counterparts across the board, especially on problems that require multiple reasoning steps. They also found that some previous fixes (like forcing the model to reflect or self-criticize) did increase diversity but didn’t fully solve the issue, whereas EDGE-GRPO’s entropy-based strategy clearly reduced instances of advantage collapse. The approach showed its strength even as tasks scaled in difficulty, indicating better generalization and resilience of the learning process.
Why does it matter? As LLMs are pushed to perform more complex reasoning (think multi-step math, logical puzzles, code generation with debugging), reinforcement learning is one of the only ways to really supervise the process. Making RL work well for these models is thus critical. EDGE-GRPO provides a new toolkit for robustly training reasoning agents, ensuring they continue to improve even when facing mostly failure at the start (common in very hard tasks). In practical terms, this could translate to smarter AI assistants that learn to solve problems that initially stumped them, without giving up due to a lack of feedback signal. The notion of using the model’s own entropy as a teaching signal is also intriguing – it leverages an internal metric (confidence) to guide learning, which might be applicable to other ML scenarios beyond language. Lastly, by better aligning rewards with actual reasoning quality (not just final correctness), approaches like EDGE-GRPO could produce models with more calibrated confidence and fewer spurious “high-confidence wrong” answers. For anyone building complex AI reasoning systems, these improvements in training stability and performance are stepping stones toward reliable and continuously learning reasoning AI.
7. Magentic-UI: Towards Human-in-the-loop Agentic Systems
Watching: Magentic-UI (paper)

What problem does it solve? Autonomous LLM-based agents (think AutoGPT-style systems that browse, code, or execute tasks on their own) are exciting but unreliable and potentially unsafe. They often mis-execute instructions, get stuck, or even pursue harmful actions if not reined in, because they lack human judgment. At the same time, having a human monitor every step defeats the purpose of automation. The problem Magentic-UI tackles is: How can we integrate human oversight into AI agents in a seamless, efficient way, so that humans can guide the agent when needed (ensuring safety and correctness) without micromanaging everything? This involves both a technical challenge (building a system where humans and AI can interact fluidly) and an HCI challenge (figuring out what control mechanisms make sense to end-users). Essentially, it’s about combining human-in-the-loop control with agent autonomy to get the best of both – high success rates and safety, with minimal human effort.
How does it solve the problem? The authors developed Magentic-UI, an open-source web-based interface and framework explicitly designed for human-agent collaboration. Under the hood, it runs a flexible multi-agent system (meaning you can have an LLM agent, tool-specific sub-agents, etc.) that can use external tools like web browsers, code interpreters, file systems, and more via a standardized protocol (the Model Context Protocol, MCP). The UI part is what the human sees and interacts with. Magentic-UI offers six interaction mechanisms that let a human intervene or cooperate with the agent at different levels. For example, co-planning lets a human and the AI draft a task plan together, co-tasking might allow the human to handle one subtask while the AI handles another, and multi-tasking could enable overseeing multiple agents in parallel. There are action guards, where certain potentially risky actions (like sending an email or deleting a file) are paused for human approval. A long-term memory mechanism allows both the agent and human to reference information persistently across a session (ensuring the agent doesn’t forget earlier context or corrections). These are just some of the six – the system essentially creates a control panel for the AI. The design philosophy is to keep human involvement “low friction”: the human can inject themselves into the loop with minimal effort when needed, and step back out when the agent is doing fine. To validate the setup, Magentic-UI was tested in multiple modes – from a fully Autonomous mode (agent has full tool control) to a Workflow mode (agent has no autonomy, strictly following a human-defined script) and a middle-ground Hybrid mode.
What are the key findings? Across extensive evaluations – including autonomous task completion benchmarks, simulated user studies, real user feedback sessions, and targeted safety tests – Magentic-UI showed that the human-in-the-loop approach can significantly boost task success and safety. In autonomous benchmark runs, agents using Magentic-UI’s framework completed more multi-step tasks correctly than fully-autonomous agents, largely because the human could step in at crucial junctures to prevent failure. The interaction mechanisms proved effective: for instance, in user trials, even non-expert users were able to use the co-planning and action guard features to steer the agent away from errors (like choosing the correct intermediate tool or aborting a dubious action). Quantitatively, the paper notes that Hybrid mode (some autonomy, some human control) achieved the best balance – it nearly matched the success rate of fully autonomous runs (which benefit from the AI’s speed) while maintaining the safety and correctness of the workflow mode (where nothing dangerous or incorrect slips through without a human check). Meanwhile, Workflow mode gave users deterministic control and was preferred for sensitive tasks, though it slowed things down (as expected). The safety assessment found that Magentic-UI’s guardrails (like action approval dialogues and the ability to inspect an agent’s reasoning) helped catch misaligned actions and adversarial manipulations that a user might otherwise miss until it’s too late. Users in qualitative studies reported feeling more confidence and trust in the AI when using Magentic-UI, since they had transparency into what the agent was doing and the ability to intervene. All these findings underscore that thoughtfully adding a human loop doesn’t just avoid disasters – it can genuinely improve the agent’s performance on complex tasks.
Why does it matter? As we integrate AI agents into real-world applications (from autonomous coding assistants to AI customer support reps), pure autonomy is often a liability. Magentic-UI presents a practical path forward: AI-human collaboration interfaces that amplify the strengths of both. Humans provide oversight, strategic guidance, and moral judgment; AI provides speed, consistency, and ability to handle the grunt work. This synergy can tackle problems neither could alone – AI might get 80% of a complex task done quickly, and a human can ensure the last 20% (and the overall direction) are correct. The fact that Magentic-UI is open-source is also significant: it gives researchers and developers a ready-made platform to study and deploy human-in-loop agents, accelerating progress in this crucial area. We often talk about “AI alignment” in abstract terms, but here is a concrete alignment tool – put a human in the loop in a structured way. In a broader sense, Magentic-UI is a step toward making AI agents trustworthy and user-friendly. Instead of fearing what an autonomous agent might do, a user can collaborate with it, guiding it like a teammate. This could ease the adoption of agentic AI in high-stakes domains (like medicine or finance) where a human will always need to have a say. Overall, it shifts the narrative from humans versus AI to humans and AI solving problems together, which is arguably how many real systems will be designed in the foreseeable future.
8. Agentic Reinforced Policy Optimization (ARPO)
Watching: ARPO ()
What problem does it solve? Large language model agents that operate over multiple steps – especially those that can call tools or APIs – pose a challenge for traditional reinforcement learning. Standard RL either treats each action in isolation or looks only at final success, and neither is ideal for a multi-step reasoning scenario. For example, imagine an LLM agent that has to solve a puzzle by doing web searches (tools) and then giving an answer. If it gets the answer wrong, traditional RL might just give a zero reward at the end, without clarity on which tool use or step in the reasoning was at fault. Moreover, the agent’s confidence can fluctuate wildly during the process – the authors observed that right after the agent uses a tool and gets new information, its next action’s prediction entropy spikes (essentially, the agent says “now what?” with high uncertainty). Existing RL algorithms don’t account for these “oh no, I’m confused” moments; they sample actions uniformly and might waste a lot of time exploring even when the model is confident, or conversely, not exploring enough when the model is confused. So the problem ARPO tackles is how to do fine-grained RL for multi-turn LLM agents, making sure the learning algorithm knows which parts of the interaction need more exploration or specialized credit assignment (like after using a tool), instead of treating an entire trajectory with one blunt feedback.
How does it solve the problem? ARPO is a custom-tailored RL algorithm for LLM-based agents in interactive environments. It introduces an entropy-based adaptive rollout mechanism: in simpler terms, the training dynamically allocates more exploration to those steps where the agent is highly uncertain (high entropy) – often immediately after tool usage or a big step in reasoning. For instance, if after consulting a database the model seems unsure how to use that info, ARPO will encourage trying different next moves there more than it would elsewhere. This prevents the agent from repeatedly skipping over critical decision points in a hurry; it focuses learning effort where the agent struggles. Additionally, ARPO implements a step-level advantage attribution. Instead of just giving one reward at the end or a per-turn reward, it computes how much each action (each question asked, each tool invoked) contributed to the final success or failure. This means the model gets a nuanced learning signal – maybe the final answer was wrong, but some earlier steps were actually beneficial and should be reinforced (or vice versa). Under the hood, ARPO balances global trajectory sampling (exploring different overall sequences of actions) with fine-grained step sampling (re-sampling specific decisions in the sequence), adjusting on the fly. It’s like a coach that sometimes lets the agent play a whole game, and other times says “let’s replay just that tricky part one more time,” thereby efficiently honing the agent’s skills at difficult junctures.
What are the key findings? ARPO-trained agents delivered substantially better performance on a suite of 13 challenging benchmarks, which included computational reasoning tasks, knowledge reasoning, and deep search problems. They outperformed agents trained with conventional reinforcement learning approaches, particularly in scenarios where multiple tool calls and reasoning steps were needed. One headline result: ARPO achieved the same or better performance using only half the tool interactions compared to baseline methods. In practical terms, if a naive agent might call an external calculator or wiki browser 10 times to get an answer right, an ARPO agent might solve it with only 5 calls because it’s learning to use tools more efficiently. This suggests ARPO agents are learning more strategic and purposeful tool use, rather than flailing around. Another observation is that ARPO’s focus on uncertain moments paid off – the entropy spikes the authors noticed became opportunities for learning, and over time the agents became more confident and accurate in those once-problematic steps. On tasks requiring long reasoning chains, ARPO agents maintained coherence and didn’t get as derailed by earlier irrelevant actions (a sign that the advantage attribution helped credit the right actions). The researchers also note that ARPO bridges a gap between two extremes: pure end-to-end RL versus scripted tool use. By combining high-level reward with step-level guidance, it kind of gets the advantages of both (global optimization with local feedback). The end result is an agent that is more competent in realistic multi-turn settings – it makes fewer needless tool calls, and when it does act, its actions are more often actually helpful toward the goal.
Why does it matter? Training AI agents to reliably perform multi-step tasks (like researching a topic online and writing a summary, or debugging a piece of code using documentation) is one of the frontiers of AI right now. ARPO is a significant advancement in that it acknowledges and addresses the unique challenges in this setting – long horizons, external tools, and varying uncertainty. For the AI community, it’s a proof that we can adapt reinforcement learning to the quirks of LLM-based reasoning. This means future agents can be trained more effectively, reaching higher competence with less training data or costly interaction. The fact that ARPO cuts tool usage in half is also economically relevant – many tool calls (e.g., APIs, database queries) have costs or latency, so making agents more frugal without losing performance is a big win. Moreover, ARPO’s ideas might inspire algorithms in other domains where an AI’s confidence fluctuates (imagine a self-driving car that becomes uncertain in new traffic situations – a similar adaptive exploration could be useful). Big picture: ARPO brings us closer to AI agents that are both efficient and adaptive in dynamic tasks. It’s a step away from brittle one-shot prompt answering and toward agents that can learn from and react to an environment intelligently, which is a core component of any hoped-for general AI.
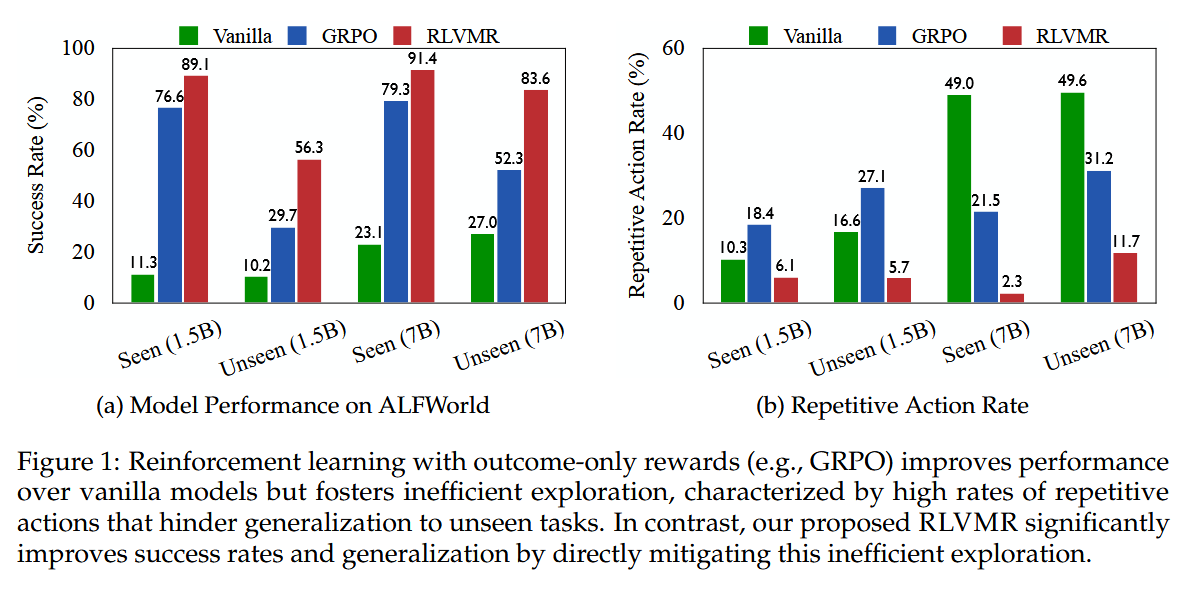
9. RLVMR: Reinforcement Learning with Verifiable Meta-Reasoning Rewards for Robust Long-Horizon Agents
Watching: RLVMR (paper)
What problem does it solve? Reinforcement learning agents, especially language-model-based ones, can sometimes learn to get the right answers for the wrong reasons. If an RL agent receives a reward only for completing a task, it might end up exploiting quirks or repeating trial-and-error sequences that achieve the goal without truly understanding the task – leading to brittle behavior that fails if conditions change even slightly. This is a known issue: optimizing solely for final success often reinforces flawed or inefficient reasoning paths. The agent doesn’t learn “how to reason,” it just learns “how to win,” which might involve hacks that don’t generalize. For long-horizon tasks (e.g., interactive game environments or complex problem-solving), this means you get agents that reach the end by stumbling through, but they’re brittle and not interpretable. The problem RLVMR addresses is how to make RL agents actually learn to think coherently and not just luck into the correct outcomes. In other words, can we reward the process of reasoning, not just the outcome, so that an agent’s internal decision-making becomes sound and reliable?
How does it solve the problem? RLVMR introduces a novel training framework that injects dense, process-level feedback into the reinforcement learning loop. It works by having the agent explicitly tag or demarcate steps of its own reasoning (for example, an agent might label parts of its action sequence as “planning”, “exploration”, “reflection”, etc.), and then the trainer provides verifiable rewards for good behavior in those meta-reasoning steps. These rewards are programmatic and rule-based: for instance, the agent could get a small reward for laying out a clear plan of attack (because a plan can be checked for coherence), another reward for exploring a new path after failing rather than repeating an old failed action (encouraging it to not get stuck in loops), and a reward for self-reflecting and correcting an error. These are “verifiable” in that the environment or a monitoring process can check if the agent did what it claimed (e.g., it said it was exploring and indeed it tried a new solution). RLVMR combines these process rewards with the usual final outcome reward into a single learning objective, which they optimize with a policy gradient method (notably, they do it critic-free, simplifying training). Essentially, RLVMR is teaching the agent how to reason well by rewarding good reasoning steps along the way. The agent’s policy isn’t just outputting actions; it’s outputting actions plus annotations of its cognitive steps, which the training algorithm continuously critiques and reinforces. This guided approach pushes the agent to adopt strategies a human might consider common-sense: make a plan, follow through, adapt if needed, rather than randomly thrashing until something works.
What are the key findings? Agents trained with RLVMR become significantly more robust and effective in long-horizon environments. On challenging interactive benchmarks like ALFWorld and ScienceWorld, RLVMR set new state-of-the-art performance – for example, a 7B-parameter LLM agent achieved an 83.6% success rate on the hardest unseen task split in ALFWorld, whereas previous approaches were much lower. These tasks involve multiple steps and require carrying out procedures in a simulated world, so that high success rate indicates the agent can reliably handle long tasks it hasn’t explicitly seen before. More illuminating, the agents’ behavior changed qualitatively: reasoning quality improved dramatically. They exhibited far fewer redundant or pointless actions – meaning the agent wasn’t just flailing around to accidentally solve the task, but was following more efficient, logical sequences. When mistakes happened, RLVMR agents showed enhanced error recovery: instead of getting stuck or repeating the same failed action, they would try a different strategy or backtrack appropriately (just as a human problem-solver might do upon realizing an approach isn’t working). Another benefit was interpretability: because the agent tags its cognitive steps and is rewarded for doing so clearly, one can literally see the agent “thinking” in a structured way. The researchers could verify that the performance gains indeed stemmed from better reasoning – for instance, the agent’s reflections often identified exactly why a previous attempt failed and how to fix it, demonstrating a depth of understanding that a pure outcome-based RL agent lacked. All of this suggests that the dense rewards successfully shaped not just what the agent does, but how it does it, leading to solutions that are both correct and grounded in sound reasoning. The combination of process and outcome rewards meant the agent didn’t sacrifice success for the sake of following rules – it actually achieved higher success because following those reasoning “rules” led to more robust strategies.
Why does it matter? RLVMR is a compelling proof that we can train not just for task success, but for the quality of reasoning, and get better agents as a result. This has implications for the development of trustworthy AI. Agents that genuinely reason through problems (as opposed to those that accidentally solve them) are more likely to handle new situations and to fail gracefully when they do fail. By rewarding meta-reasoning, RLVMR also aligns the agent’s incentives with behaviors we consider desirable (like deliberation, exploration, self-correction) – which could reduce the incidence of weird, unexplainable shortcuts or cheats that pure reward maximization might encourage. In practical terms, this could lead to AI assistants that, say, show their work and double-check critical steps when they code or solve math problems, because those behaviors were baked into their training rewards. The success on long-horizon tasks is also a green light for tackling more complex, multi-step real-world problems with AI. It suggests that if we can formalize what good reasoning looks like in a domain (even via simple rules), we can substantially boost an agent’s performance and reliability in that domain. Lastly, RLVMR adds to the toolbox of alignment techniques – it’s a way of telling the AI “not only do the job, but do it in a way that we consider logically sound.” As AI systems become more autonomous, methods like this will be key to ensure they don’t just get results, but get them in a safe and interpretable manner.
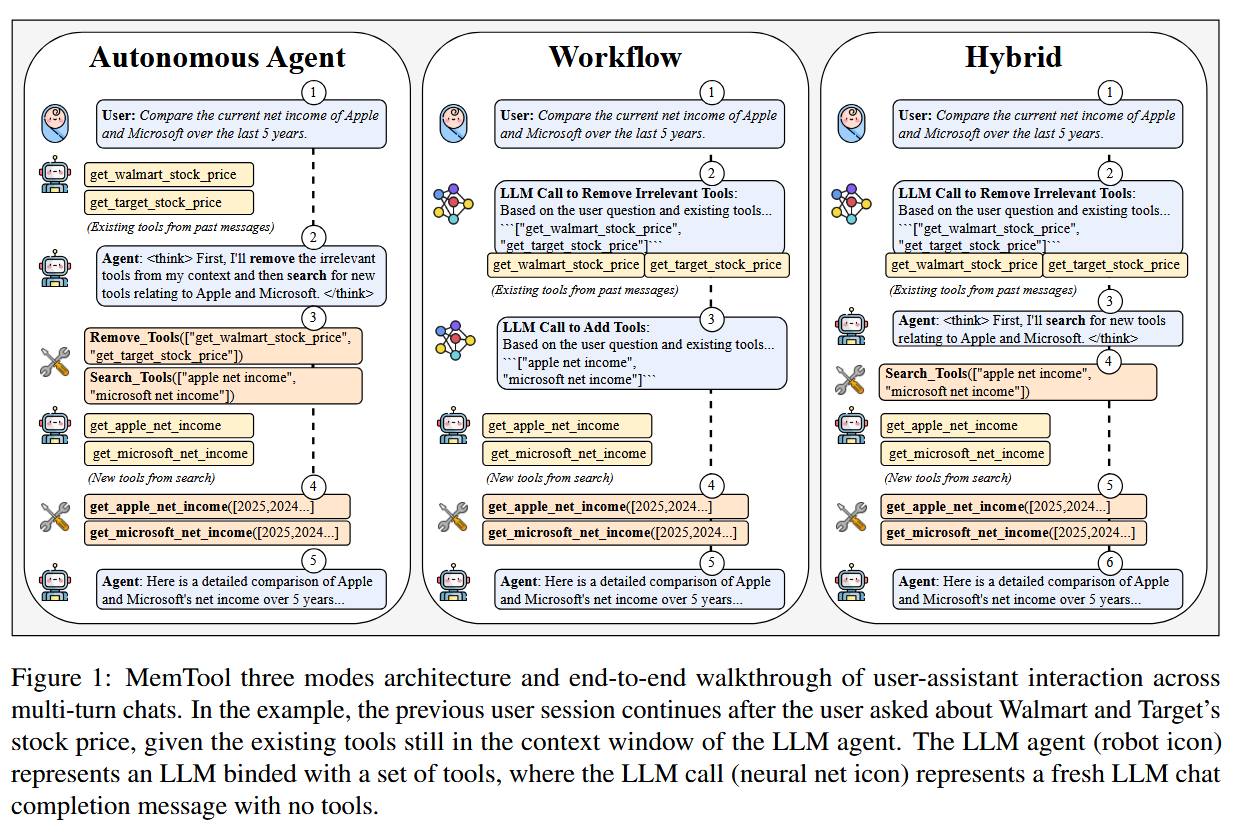
10. MemTool: Optimizing Short-Term Memory Management for Dynamic Tool Calling in LLM Agent Conversations
Watching: MemTool (paper)
What problem does it solve? LLM-based agents that carry on extended multi-turn conversations and invoke tools face a practical memory issue: the context window isn’t infinite. As an agent interacts (say it’s a chatbot that can use a calculator, search engine, etc.), each tool’s output and the agent’s intermediate reasoning take up space in the prompt. Over many turns, this “short-term memory” can overflow, forcing the agent to drop older information – which might be important later. Without strategy, agents might forget key facts or, conversely, hang on to too much irrelevant data and drown in context. The problem is how to intelligently manage the working memory of an agent: deciding what tool outputs or intermediate results to keep and what to discard as a conversation or task progresses. It’s analogous to our own short-term memory management (we remember what’s relevant and let trivial details fade). For AI, getting this wrong either leads to failures (forgetting needed info) or inefficiency (context blow-up).
How does it solve the problem? MemTool provides a dedicated framework and set of strategies for dynamic context management in tool-using agents. In practice, it offers three modes of operation:
Autonomous Agent Mode: The agent itself has full autonomy to decide when to drop or retain tool-related information from its context. For example, after using a tool, the agent can choose to “forget” the tool’s output in subsequent turns if it deems it no longer needed.
Workflow Mode: A deterministic, human-defined policy controls memory – essentially no autonomy. This could be a simple rule like “always remove the result of a tool call after 3 turns” or “only keep the last result from each tool.” The agent doesn’t decide; it just follows a fixed procedure for memory.
Hybrid Mode: A mix of both – perhaps the agent can suggest what to remove, but there are overrides or confirmations via set rules. Or certain critical data is always kept by rule, while the agent can manage the rest.
MemTool is implemented as an extension on top of a multi-agent conversation architecture (using the Model Context Protocol to interface with tools). It monitors the context window and applies the above policies to prune or persist tool outputs across turns. The design allows plugging in these modes without changing the underlying agent: you can swap between letting the agent think about memory or enforcing a policy, based on model capability and use case. To evaluate it, the authors stress-tested MemTool on a benchmark called ScaleMCP with conversations spanning 100+ user interactions, which would normally overflow any context. They measured how effectively each mode prunes irrelevant content (short-term memory efficiency) and how that impacts task completion accuracy – does the agent still get the answers right?
What are the key findings? Memory management can indeed be handled, and the best approach depends on the model’s sophistication. In Autonomous mode, very capable LLMs (think GPT-4 class or similarly strong models) were able to achieve extremely high memory efficiency – they removed about 90–94% of unnecessary tool content from the context (averaged over a 3-turn window). This indicates that advanced models can learn or be prompted to recognize what information is safe to forget. However, medium-sized or less advanced models struggled when left on their own, with only 0–60% efficiency (sometimes basically forgetting nothing or forgetting the wrong things). They lack the judgment to prune memory well. The Workflow mode, by contrast, consistently maintained a tidy context regardless of model size – as expected, since a fixed policy was ensuring obsolete info was dropped. There’s no ambiguity or model error in deciding; the rules did the job. But the trade-off came in task performance: Autonomous and Hybrid modes tended to excel at task completion, especially on complex tasks, compared to a strict workflow. This is likely because the agent in those modes could choose to keep information it knew would be relevant later, whereas a rigid workflow policy might blindly throw out something that, unbeknownst to it, the agent could have used in a future step. The Hybrid mode often hit a sweet spot – tool removal was effective and near-optimal, yet the final accuracy remained high. It seems giving the agent some say (especially a smart agent) in what to remember, while enforcing basic rules, leads to both a clean context and correct answers. One concrete example from the evaluations: a large LLM in Hybrid mode might remove “temporary” tool outputs (like intermediate calculations) but hold on to a key fact it found via a tool, even if the workflow policy would normally purge it – and that fact later leads to a correct answer, demonstrating the value of agent insight in memory management. Across the 100-turn conversations, MemTool prevented context overflow and thereby allowed the dialogues to continue smoothly with relevant information always at hand.
Why does it matter? This work is a stepping stone toward scalable, long-running AI agents. In real-world usage, we want AI that can engage in prolonged tasks – think of an AI assistant that can research, plan, and execute over hours or days of interaction. Without good memory management, such agents would either forget early instructions or become impossibly expensive to run (stuffing huge transcripts into their context window). MemTool shows that with a combination of model smarts and engineered policy, we can extend an agent’s effective memory without infinite context windows. It’s like giving the agent a working memory akin to an organized notebook: it writes down what it needs, erases what’s done, and always has room for the next idea. For practitioners, these findings also suggest practical guidelines: if you’re using a strong model, you can trust it more to handle its context (maybe just give it a framework like MemTool’s autonomous mode with some prompts to encourage forgetting). If you’re on a smaller model, you might implement a strict memory clearance policy or use a hybrid approach to avoid the model drowning in old info. In broader AI research, MemTool touches on the concept of meta-cognition – the agent thinking about its own memory usage. That’s a vital aspect of human cognition (we constantly decide what to keep in mind or not), and implementing it in AI can lead to more efficient and human-like problem solving. Finally, this contributes to making AI more efficient and cheaper to deploy: if an agent knows to drop irrelevant context, it uses fewer tokens in prompts over time, which could dramatically cut costs for API-based models. In summary, MemTool points the way to AI that can handle longer and more complex interactions by cleverly managing its finite memory, an essential capability for any advanced autonomous system.
11. Graph-R1: Towards Agentic GraphRAG via End-to-end Reinforcement Learning
Watching: Graph-R1 (paper/code)
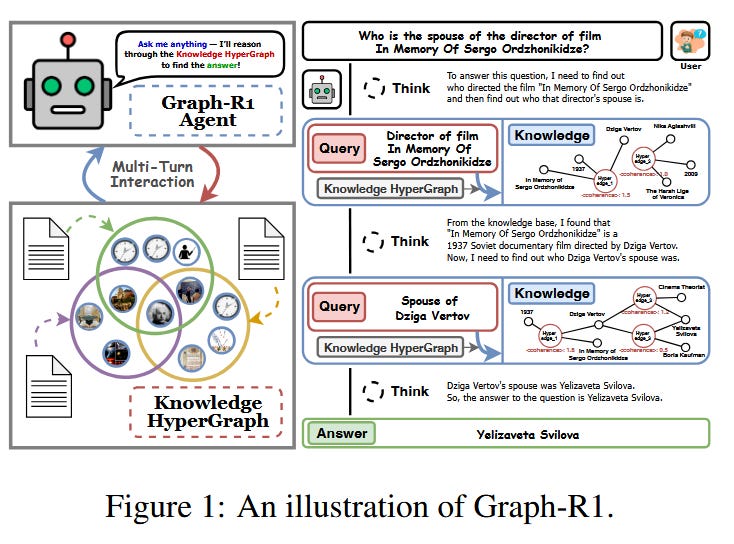
What problem does it solve? Retrieval-Augmented Generation (RAG) mitigates hallucination in LLMs by incorporating external knowledge, but relies on chunk-based retrieval that lacks structural semantics. GraphRAG methods improve RAG by modeling knowledge as entity-relation graphs, but still face challenges in high construction cost, fixed one-time retrieval, and reliance on long-context reasoning and prompt design. The problem Graph-R1 addresses is how to make knowledge retrieval interactive and agentic: the AI should be able to walk through a knowledge graph step by step, deciding which nodes (topics) to explore next based on the current query, and do so in a trained optimal way. In short, it’s tackling the gap between static knowledge retrieval and the kind of dynamic, exploratory search a human might do when answering a complex question, and doing this without an expensive upfront graph construction or complicated prompt engineering.
How does it solve the problem? Graph-R1 transforms the retrieval process into an interactive environment and trains a reinforcement learning agent to operate within it. Instead of retrieving text chunks once, the system constructs a lightweight knowledge hypergraph of the information – a structure of entities and their relations that is cheaper to build and rich in semantics. The Graph-R1 agent then models retrieval as a multi-turn agent-environment interaction: it treats the knowledge base like a world to navigate, where each action might be following a link or querying a related concept. The agent is optimized end-to-end via a reward mechanism that aligns with finding the correct answer. This means the agent learns policies for retrieval – when to stick with the current topic, when to pivot to a related entity, when to stop gathering information – all through trial and error guided by whether it leads to better answers. Crucially, by using RL, Graph-R1 doesn’t require manual prompt strategies for multi-hop queries; the agent organically figures out a strategy to fetch what it needs. The authors also introduce tricks for lightweight hypergraph construction, so that the agent isn’t burdened by an enormous graph: it likely builds or expands the graph on the fly as needed, keeping retrieval targeted. Overall, Graph-R1 is an agentic GraphRAG: a graph-guided retrieval system where an RL-trained agent actively and intelligently controls the retrieval process, bridging structured knowledge with the language model’s reasoning in an integrated loop.
What are the key findings? Graph-R1 sets a new bar for accuracy and efficiency in knowledge-intensive tasks. Experiments on standard RAG datasets show that Graph-R1 outperforms both traditional GraphRAG and RL-enhanced RAG methods in reasoning accuracy, retrieval efficiency, and generation quality. In terms of reasoning accuracy, Graph-R1’s answers were more often correct on multi-hop and knowledge-dense questions, indicating the agent successfully gathered the needed evidence that static one-shot retrieval might miss. For retrieval efficiency, the agent found relevant information with fewer steps and less irrelevant data – it doesn’t shotgun a dozen documents if only two well-chosen pieces suffice. The generation quality also benefited: answers were coherent and well-supported by the retrieved facts, since the agent could ensure all necessary context was obtained and extraneous bits were left out. Notably, Graph-R1’s performance didn’t come at the cost of massively increasing computation; by keeping the knowledge search targeted via the hypergraph and RL policy, it remained cost-effective. The study also likely found that end-to-end RL helped the model navigate ambiguous queries: the agent could try one line of inquiry, and if it turned out to be a dead end (leading to low reward), learn to try an alternate path in future episodes – something a fixed retrieval strategy can’t adaptively do. By bridging structured graphs with the flexibility of an agent, Graph-R1 demonstrated that learning to retrieve can beat even strong static retrieval heuristics.
Why does it matter? This result is an exciting step toward more intelligent information-seeking AI. Instead of treating the knowledge source as a static library, Graph-R1 treats it as a navigable world – bringing reinforcement learning, which is typically used in games or robotics, into the realm of knowledge retrieval. The payoff is an AI that’s better at knowing when it has enough information and where to find it rather than guessing or hallucinating. This could dramatically improve systems like search engines, virtual assistants, or any AI that needs to base answers on external knowledge: we’ll get answers that are not just confident, but grounded in a verifiable path of retrieved evidence (making the AI’s reasoning more transparent too). Moreover, Graph-R1’s success suggests that building lighter weight knowledge representations (like hypergraphs) and training agents on them can outperform brute-force approaches that dump massive documents into an LLM. It’s a win for efficiency and scalability – as knowledge bases grow, an agent that can selectively explore will be far more tractable than trying to cram everything into context. In a broader sense, Graph-R1 is a convergence of symbolic and neural approaches: it uses a symbolic structure (graph) and a neural policy (RL agent) together. This hints at future AI systems that combine the reliability of symbolic reasoning with the flexibility of learning. All said, Graph-R1 advances the state of the art in making AI that is both knowledgeable and able to actively gather knowledge, a crucial ability for any AI aspiring to truly assist with complex, real-world questions.

Putting It All Together: Toward Smarter and Safer LLM Agents
From these papers, we can see multiple convergent themes:
First, scaling and new architectures (like Kimi K2’s trillion-parameter MoE and Falcon-H1’s hybrid design) are giving open models unprecedented power, narrowing the gap with closed models.
Second, a host of novel training methods – from smarter reinforcement learning algorithms to language-based self-evolution– are greatly boosting reasoning capabilities and sample efficiency.
Third, researchers are acknowledging that human guidance and knowledge structure remain crucial: frameworks like Magentic-UI put humans in the loop for safety, and Graph-R1’s agent navigates structured knowledge to avoid hallucination.
Finally, solutions for long-horizon tasks (MemTool’s memory management, self-evolving agents) are enabling AI to operate coherently over extended interactions.
In essence, the community is engineering LLM systems that are not just bigger, but designed smarter – able to learn continually, reason through complex problems, leverage tools and knowledge bases effectively, and work alongside humans.