
10 Papers You Should Know About
Get ahead of the curve with LLM Watch
Welcome, Watcher! This week in LLM Watch:
Open-source computer-use agents smashing closed-model benchmarks
Robots that can plan in space before they act
Agents pushing past 40+ tool calls for long-horizon search
Training tricks that make LLM reasoning shorter, sharper, and cheaper
GPT-5 challenging human doctors in multimodal medical reasoning
Don’t forget to subscribe to never miss an update again.
Quick Glossary (for the uninitiated)
Computer-Use Agent (CUA): An AI system that can directly operate a computer’s user interface - clicking, typing, navigating menus - to perform tasks, often trained on large datasets of recorded human interactions.
Multimodal: In AI, the ability to handle and integrate multiple types of input/output - e.g., text, images, audio, video - within a single system.
Semantic Memory: Knowledge stored in a structured way (facts, concepts, relationships) rather than as raw sequences - helps AI recall general truths instead of just events.
Chain-of-Thought (CoT): A reasoning approach where an AI explicitly generates intermediate steps before giving a final answer — like showing your work in math class.
Group-Filtered Policy Optimization (GFPO): A reinforcement learning training trick where you generate multiple candidate answers, then keep only the concise, correct ones before updating the model - effectively teaching it to think shorter and sharper.
Tool Call: An action where an AI agent invokes an external function, API, or service (e.g., a search engine or calculator) during reasoning.
Retrieval-Augmented Generation (RAG): A method where the model fetches relevant information from an external database or search system before (and while) generating its answer, so it can stay factual and up to date.
Mixture-of-Experts (MoE): A neural network architecture that contains many specialized sub-models (“experts”) but only activates a subset for each input, making it both efficient and versatile.
Zero-Shot: Asking a model to do a task without giving it any task-specific examples during training - the AI must generalize from what it already knows.
Self-Play: A training setup where AI systems generate their own challenges and solutions to improve iteratively - like practicing chess against yourself to get better.
OpenCUA: Open Foundations for Computer-Use Agents (paper)
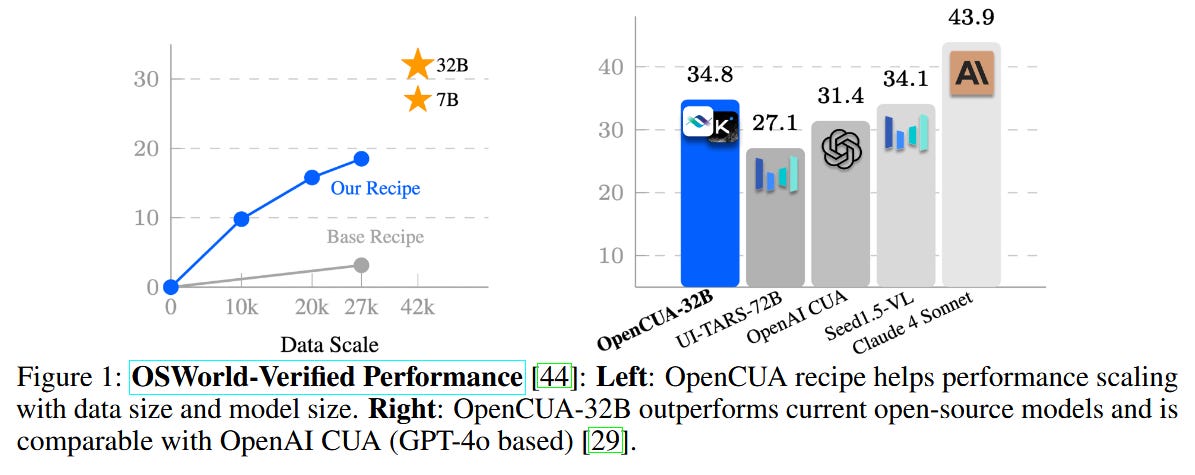
OpenCUA is a new open-source framework for building AI agents that perform computer GUI tasks. It includes an annotation tool and AgentNet, a large-scale dataset of human computer-use demonstrations spanning 3 operating systems and 200+ applications. Using a scalable pipeline (with recorded “chain-of-thought” rationales), OpenCUA-trained models set a new state-of-the-art on benchmarks – a 32B model attained 34.8% success on the OSWorld-Verified suite, surpassing OpenAI’s GPT-4-based agent. All annotation tools, datasets, code, and models are being released to spur open research on Computer-Use Agents (CUAs).
Echo-4o: GPT-4o Synthetic Images for Better Image Generation (paper/code)
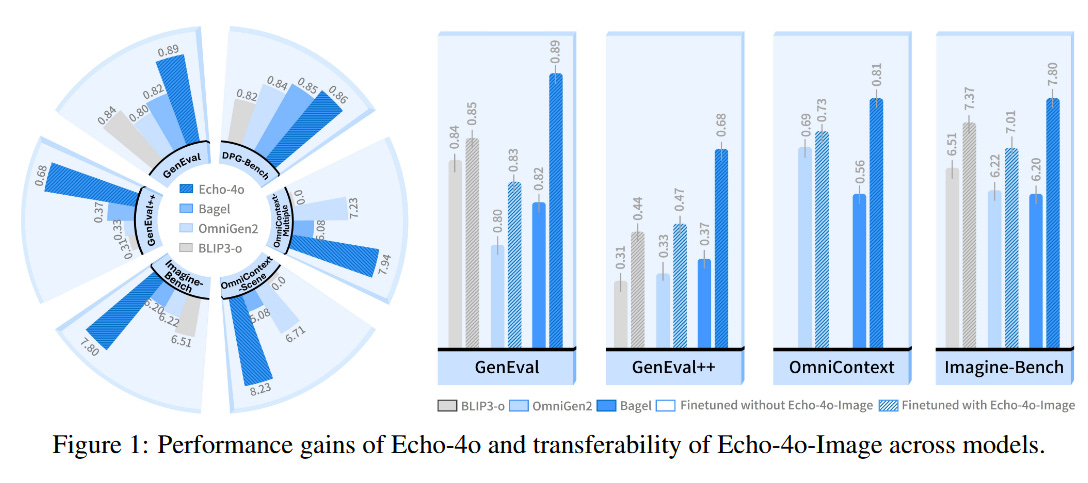
Echo-4o harnesses OpenAI GPT-4’s image generation (GPT-4o) to create a synthetic training set that fills gaps in real-image data. The authors generated 180,000 GPT-4o images focusing on rare or imaginative scenarios that are underrepresented in standard datasets (e.g. surreal fantasy scenes, multi-object compositions). These synthetic images provide cleaner, more aligned training signals (with detailed text descriptions) compared to noisy real data. Fine-tuning an open multimodal model on this Echo-4o-Image dataset yielded Echo-4o, which achieves strong results on new, challenging evaluation benchmarks (GenEval++ and Imagine-Bench) for creative image generation. Notably, using the GPT-4o synthetic data also boosted other foundation models (OmniGen2, BLIP3-o), showing the approach’s broad utility.
“Speed Always Wins”: Survey on Efficient LLM Architectures (paper/code)
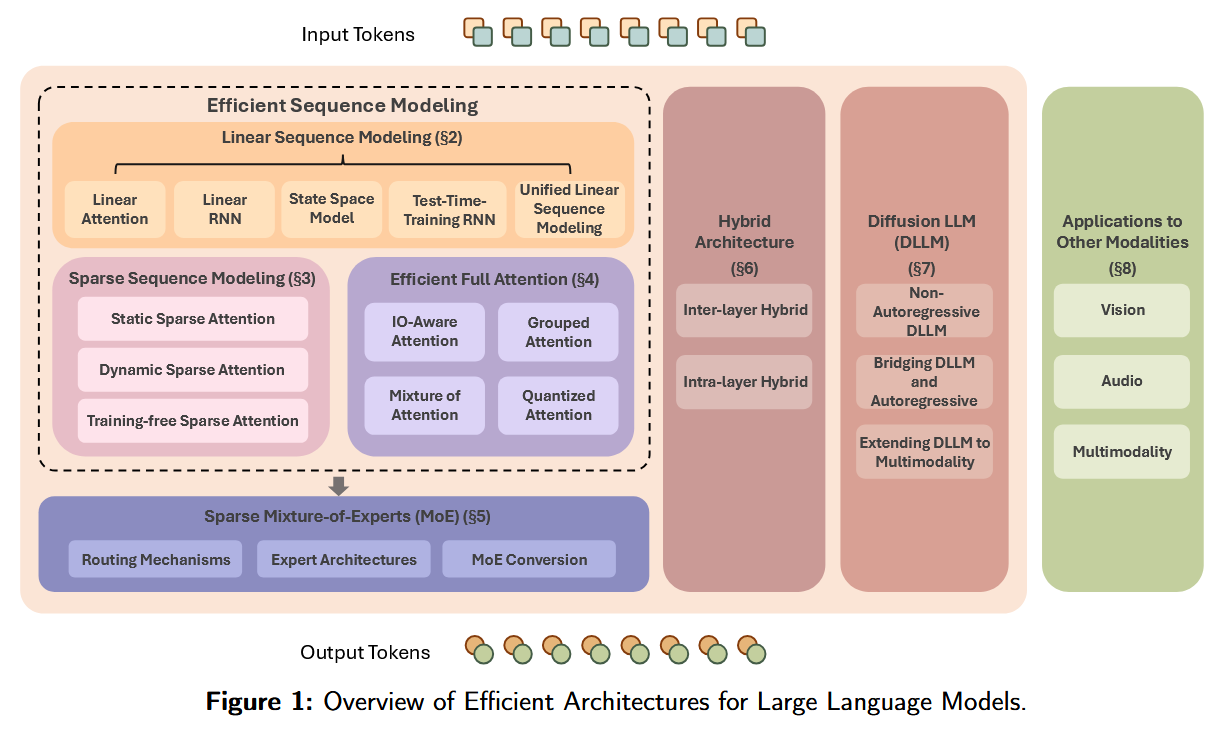
This comprehensive 82-page survey reviews the landscape of techniques for improving LLM efficiency. It covers a range of model architecture innovations beyond the standard Transformer: from linearized and sparse sequence models to efficient attention variants, sparse Mixture-of-Experts, hybrid models, and even emerging diffusion-based language models. The authors group 200+ papers into these categories and discuss applications to modalities beyond text. The survey serves as a blueprint of modern efficient LLM design, highlighting how these methods reduce computation and memory needs while maintaining performance. It aims to guide future research toward more efficient, scalable foundation models.
Seeing, Listening, Remembering, and Reasoning (M3-Agent) (paper/code)
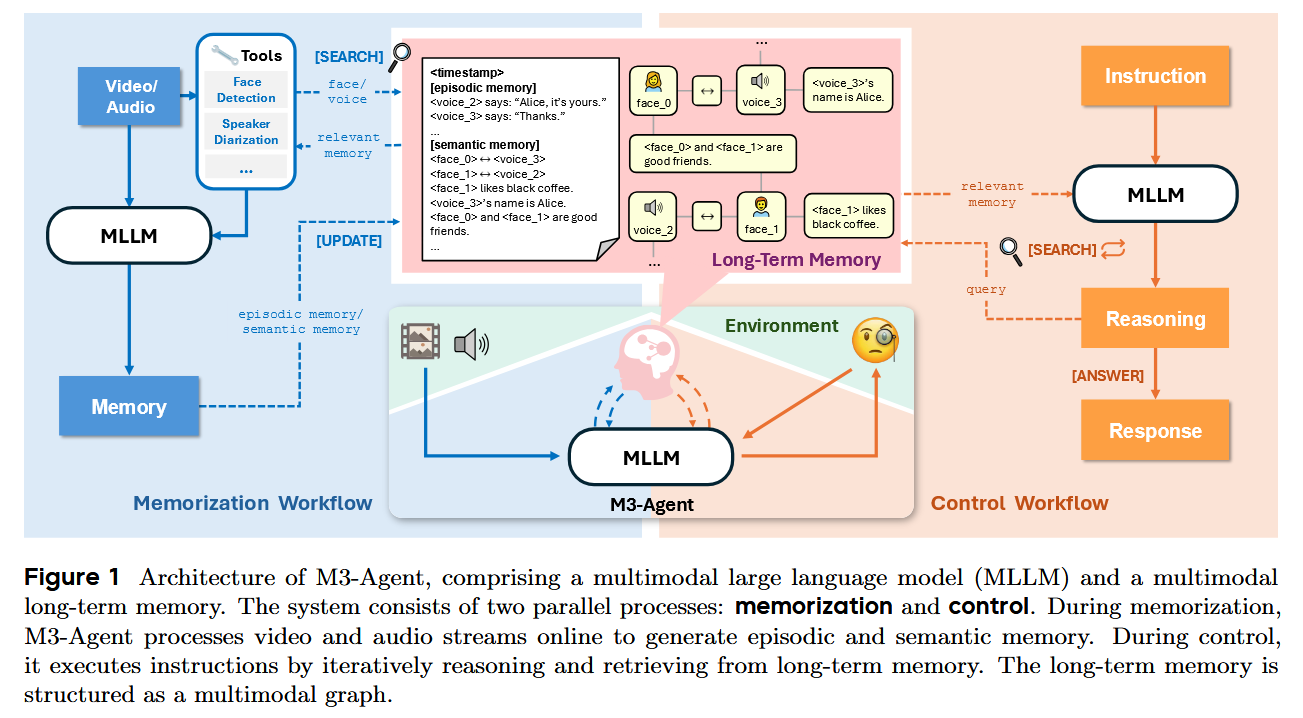
Researchers introduced M3-Agent, a multimodal AI agent framework equipped with an explicit long-term memory. Like a person, M3-Agent processes real-time visual and auditory input and builds two types of memory: an episodic memory of recent events and a semantic memory of accumulated world knowledge. Uniquely, the memory is organized in an entity-centered, multimodal graph, enabling the agent to maintain a consistent understanding of people, places, and objects over time. When given instructions, M3-Agent engages in multi-turn reasoning, retrieving relevant facts from its memory to aid decision-making. On a new long-video QA benchmark (M3-Bench), M3-Agent (trained via RL) outperformed a strong GPT-4o-powered baseline by 5–8% in accuracy across various test sets. This demonstrates more human-like recall and reasoning, especially in long-horizon tasks, and the authors open-sourced the model, code, and a new 1000+ video dataset for multimodal memory research.
Sample More to Think Less: Concise Reasoning via GFPO (paper)

Group-Filtered Policy Optimization (GFPO) is a new RL fine-tuning method that teaches LLMs to reason succinctly. When training on a reasoning task, GFPO generates a group of candidate solutions for each problem and filters them using two metrics – (1) brevity (response length) and (2) token efficiency (reward per token). By only reinforcing solutions that are both accurate and concise, the model learns to avoid the common tendency of RL-tuned LLMs to produce verbose, filler-laden explanations. In experiments on math and coding benchmarks, applying GFPO to a 4-billion-parameter reasoner cut the length of its answers by 46–85% (drastically reducing unnecessary text) while maintaining accuracy. An adaptive difficulty variant of GFPO further improved efficiency on hard questions. In short, GFPO trades a bit more training compute for significantly less reasoning overhead at inference, a promising step toward cost-effective yet rigorous reasoning.
Beyond Ten Turns: Long-Horizon Agentic Search (ASearcher) (paper/code)
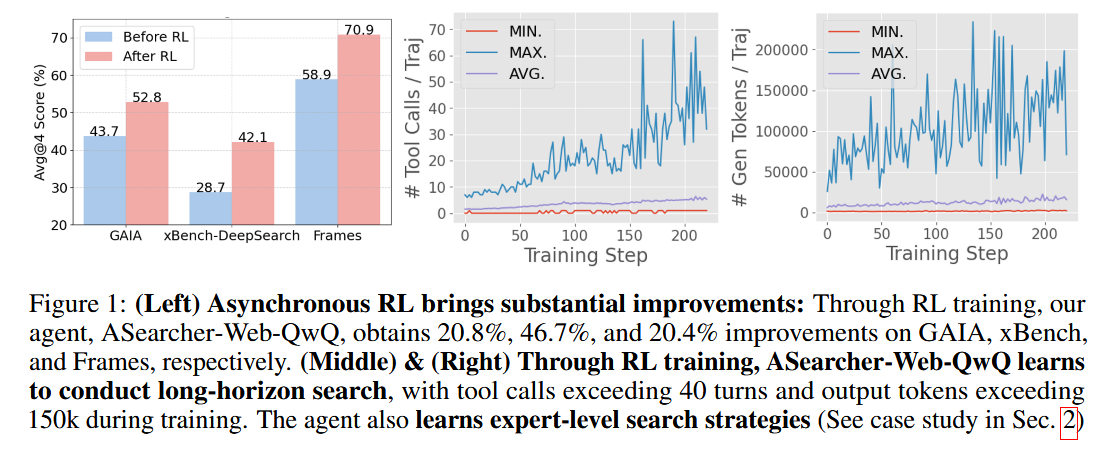
“Beyond Ten Turns” presents ASearcher, an RL-trained web agent that can conduct extremely long search sessions with high success. Previous open-source agents were constrained to roughly 5–10 tool use steps, limiting their ability to solve complex, ambiguous queries. ASearcher uses a fully asynchronous RL pipeline to enable 40+ sequential search calls and over 150k output tokens within a single query session during training. The authors also built a self-play data generation scheme: a prompt-based 32B LLM (named QwQ-32B) that autonomously creates challenging question-answer tasks for the agent to practice. Through this large-scale training, the resulting agent achieved massive improvements on knowledge-seeking benchmarks – for example, +46.7% (Avg@4 score) on xBench and +20.8% on GAIA versus previous state-of-the-art. Notably, ASearcher’s Web-QwQ agent, which uses no external API calls (only its own LLM), achieved Avg@4 scores of 42.1 on xBench and 52.8 on GAIA, outperforming all prior open 32B agents. The project is open-sourced, offering the community a path to train truly long-horizon autonomous search agents.
Capabilities of GPT-5 on Multimodal Medical Reasoning (paper/code)
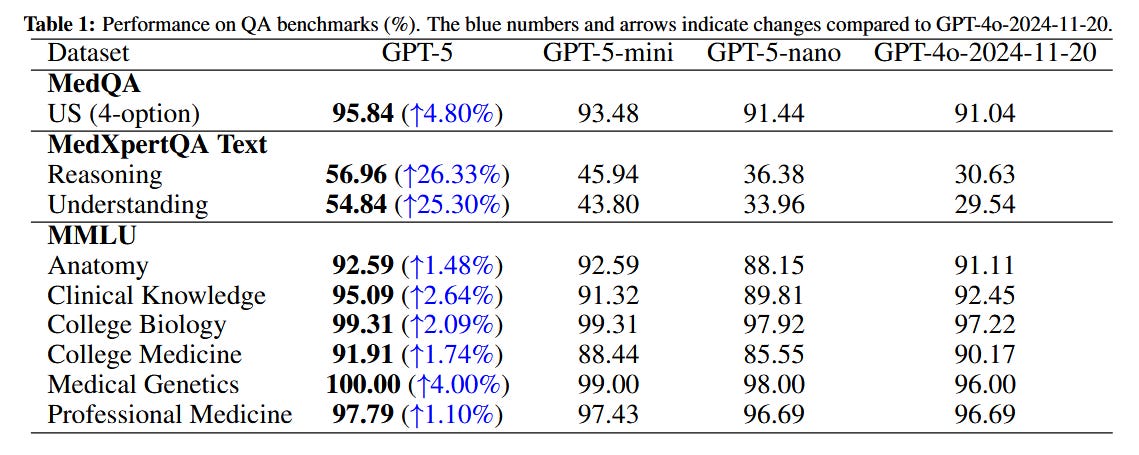
A new study evaluated an early GPT-5 model on challenging medical reasoning tasks and found it significantly surpasses GPT-4 in this domain. GPT-5 was tested on both text-based and image-based medical question answering (for example, diagnosing from clinical narratives and X-ray images) under a zero-shot chain-of-thought setting. Across multiple benchmarks – including MedQA, multimodal MedXpertQA, MMLU medical exam subsets, and the USMLE exams – GPT-5 achieved state-of-the-art accuracy and substantial gains in multimodal understanding. On the MedXpertQA-MM dataset, GPT-5 improved reasoning and understanding scores by +29.3% and +26.2% over GPT-4o, respectively, even outperforming licensed human physicians by about 24–29% in those areas. (By contrast, GPT-4o was still below human-expert level on most metrics.) A case study highlights GPT-5’s ability to combine visual and textual clues into a coherent diagnostic reasoning chain, often recommending correct high-stakes interventions. These results suggest GPT-5 has crossed into above-human performance on controlled medical reasoning benchmarks, which could inform next-generation clinical decision support systems.
ParallelSearch: Teaching LLMs to Search in Parallel (paper/code)
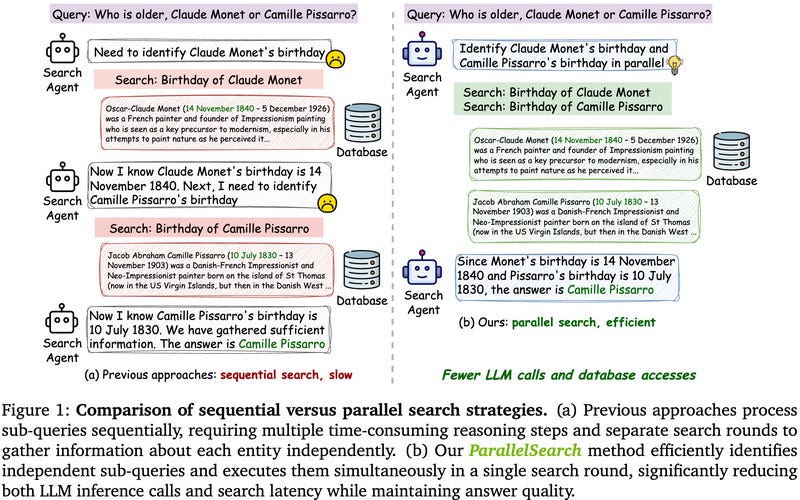
ParallelSearch is a new framework to speed up LLM-augmented search by decomposing queries and executing sub-queries in parallel. Today’s retrieval-augmented LLM agents usually handle multi-part queries in a serial manner – e.g. to answer “Who is older, Monet or Pissarro?”, a standard agent would do one search for Monet’s birthdate, then another for Pissarro’s, then compare. This sequential approach incurs unnecessary latency, especially when sub-questions are independent. ParallelSearch uses reinforcement learning (with verifiable reward signals) to train an LLM agent to detect when a question can be split into independent parts and to issue those search queries simultaneously. On seven question-answering benchmarks, a ParallelSearch-augmented agent outperformed SOTA by an average of +2.9%, and on specifically parallelizable queries it saw a +12.7% accuracy boost while using only ~70% of the usual LLM calls. In practice this means much faster query resolution (fewer reasoning steps and search rounds) with no loss in answer quality. ParallelSearch thus offers a promising route to more efficient reasoning-enhanced search engines.
MolmoAct: Teaching Robots to Reason in Space (paper/model)
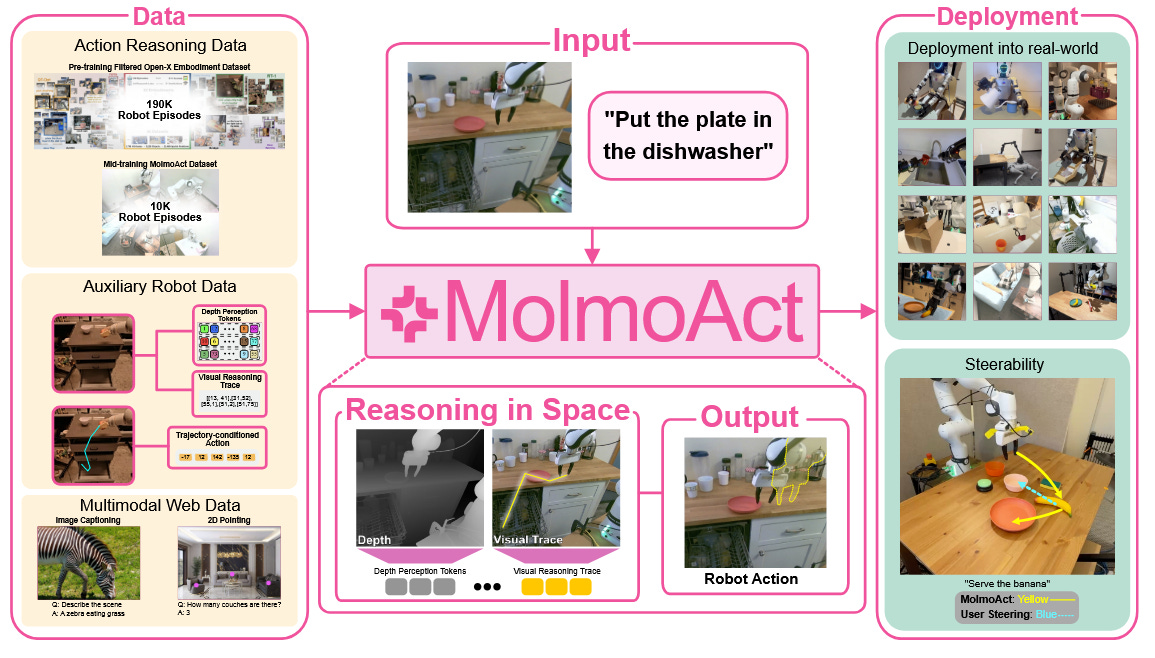
MolmoAct introduces a class of robotic foundation models called Action Reasoning Models (ARMs) that perform explicit spatial reasoning between perception and action. Unlike end-to-end policies that map images directly to robot controls, MolmoAct uses a structured three-stage pipeline: (1) it encodes visual observations and instructions into “depth-aware” perception tokens, (2) it plans at an intermediate level by generating a spatial trajectory sketch (an editable path or trace in the environment), and (3) it translates that plan into low-level motor actions. This approach yields more explainable and steerable behavior – the mid-level plan can be visualized or adjusted by a human before execution. MolmoAct (7B parameters) achieved state-of-the-art results on several robot benchmarks, including 70.5% zero-shot success on SimplerEnv (visual tasks) and 86.6% success on LIBERO, outperforming prior models like Pi-0 and ThinkAct (it was +6.3% higher on LIBERO’s long-horizon tasks). In real-world robot trials, fine-tuned MolmoAct models also showed large gains – e.g. +10% single-arm and +22.7% bimanual task completion improvement over the Pi-0-FAST baseline. The model demonstrated stronger generalization to novel scenarios (+23.3% on out-of-distribution tests) and received the highest human preference scores for following open-ended instructions and trajectory adjustments. Alongside the model, the team released a new MolmoAct Dataset of 10k high-quality, diverse robot trajectories, and open-sourced all code and weights. MolmoAct represents a new state-of-the-art in robotics, and an open blueprint for building AI agents that think before they act in physical environments.
GLM-4.5: An Open 355B ARC Foundation Model (paper/code)
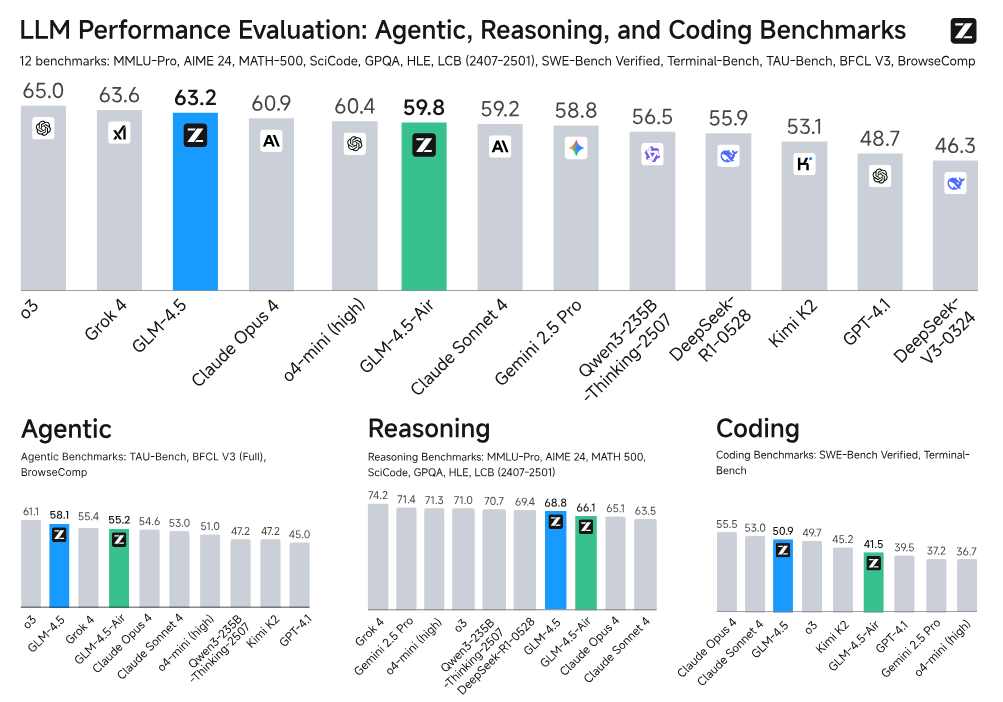
GLM-4.5 is a new open-source Mixture-of-Experts LLM from Tsinghua University and Zhipu AI, targeting Agentic, Reasoning, and Coding (ARC) abilities. It packs a massive 355 billion parameters in total (with 32B active at any time) and introduces a hybrid reasoning approach that can toggle between “chain-of-thought” mode and direct answer mode. Trained over 23 trillion tokens and further refined with expert iterations and RLHF, GLM-4.5 has demonstrated top-tier performance on a range of challenging benchmarks. For instance, it scored 70.1% on the TAU agentic reasoning benchmark, 91.0% on the AIME-24 math competition, and 64.2% on the SWE-Bench software engineering test. Despite using fewer overall parameters than some proprietary models, these results rank GLM-4.5 3rd overall among all evaluated models (and 2nd on agentic reasoning tasks) as of its release. Perhaps most exciting: the full 355B model and a more accessible 106B distilled version (“GLM-4.5-Air”) are being publicly released. This makes GLM-4.5 the largest open-source MoE LLM to date, offering the research community a powerful foundation for building advanced reasoning agents and coding assistants.
