
10 Papers You Should Know About
Get ahead of the curve with LLM Watch
Welcome, Watcher! This week in LLM Watch:
Parallel thinking and merge-of-thought distillation supercharge reasoning
Collective RL experience sharing and data-free self-play cut training costs
Agentize everything: repos that run themselves and collaborate
Smarter supervision beats herd behavior: outcome-based exploration + learned aggregation
Architecture & tooling wins: lookahead attention and AI that writes expert-level scientific software
Don’t forget to subscribe to never miss an update again.
Quick Glossary (for the uninitiated)
Chain-of-Thought (CoT): A step-by-step reasoning process used by models to solve problems. Long CoT refers to reasoning paths with many intermediate steps, often needed for complex tasks.
Knowledge Distillation: A training technique where a smaller student model learns to imitate a larger teacher model (or an ensemble of models). MoT extends this to multiple teachers, merging their knowledge into one student.
Reinforcement Learning (RL): A training paradigm where an agent (or model) learns to make decisions by receiving rewards or penalties. In the context of LLMs, RL is used to improve behaviors (like reasoning or following instructions) by rewarding correct or desired outputs. Variants include RL with human feedback (RLHF) and outcome-based RL that rewards only final answers.
Self-Play: A training technique where an AI plays both sides of a game or task. In language self-play, an LLM generates challenges and solves them itself, enabling it to improve without external data. This game-theoretic approach can lead to stronger performance as the model iteratively outcompetes its past self.
Verifiable Rewards: A reinforcement learning reward signal that comes from checking the correctness of an answer with a reliable method. For example, using a code interpreter or a math solver to verify an LLM’s answer and then giving reward if correct. This helps train models on objective tasks like math proofs or code where outcomes can be validated.
Speculative Decoding: An inference speed-up technique where a smaller model generates several tokens in advance (speculatively) and a larger model verifies or corrects them. This can greatly accelerate text generation without much loss in quality.
Merge-of-Thought Distillation (MoT) (paper)
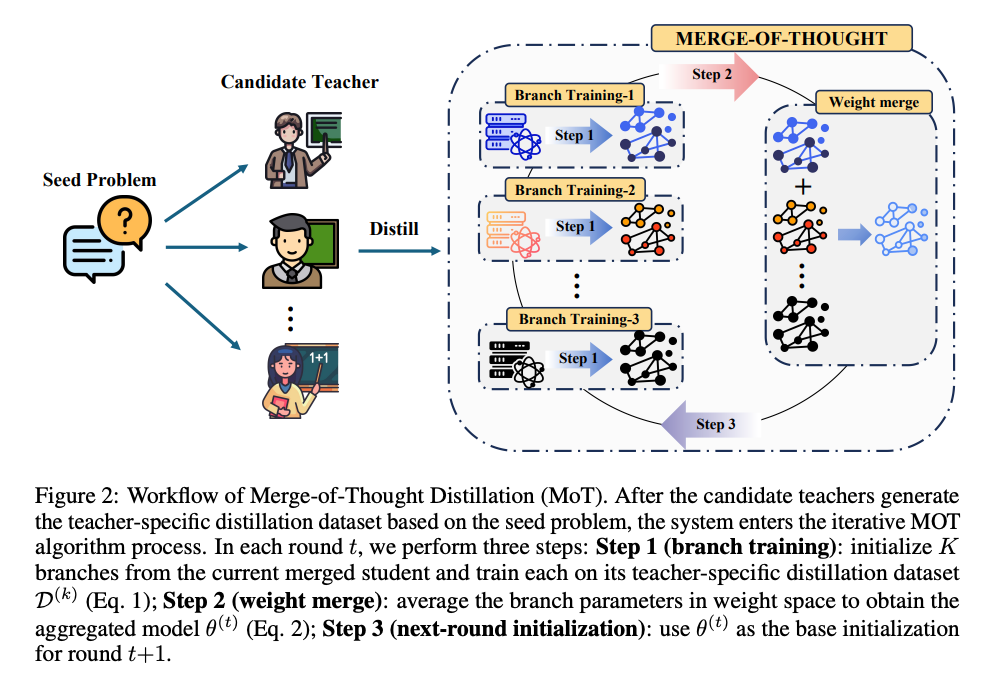
Researchers introduced Merge-of-Thought Distillation (MoT) as a lightweight framework to distill reasoning skills from multiple “teacher” models into one student model. The key insight is that no single teacher is best for all tasks – by alternating between fine-tuning on each teacher’s outputs and merging the resulting students in weight space, MoT fuses diverse problem-solving strategies into a compact model. Applied to math reasoning, a MoT-trained 14B model surpassed larger models (30B+ parameters) on competition benchmarks. It also outperformed both single-teacher distillation and naive multi-teacher blending, raising performance ceilings while reducing overfitting. Notably, MoT improved general reasoning beyond math and even produced a student model that became a better teacher itself – showing that combining teachers’ knowledge leads to robust, broadly applicable reasoning skills.
A Survey of Reinforcement Learning for Large Reasoning Models (LRMs) (paper/code)
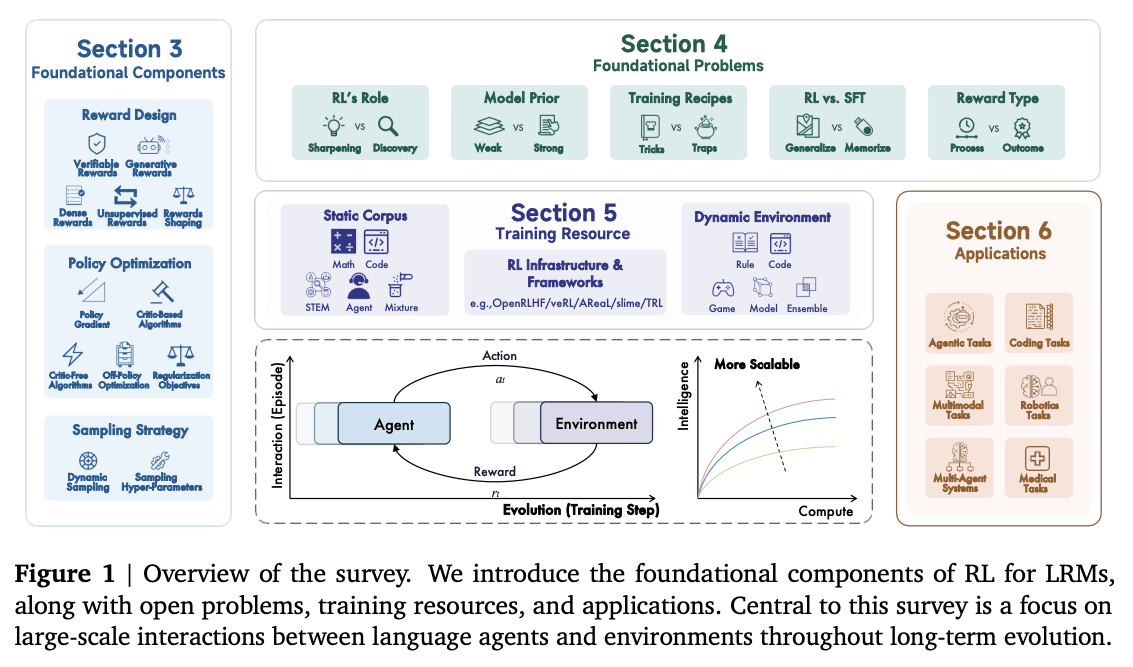
A massive new survey (100+ pages, 39 authors!) examines how reinforcement learning has been used to boost reasoning in large language models. RL has driven impressive gains in logical tasks like math and coding, effectively transforming LLMs into Large Reasoning Models (LRMs). The survey reviews core components (like reward design and curriculum), key challenges (scaling up RL requires huge compute, better algorithms, and more data), and recent milestones (e.g. the DeepSeek-R1 series). Crucially, as we push toward ever more capable models (even dreaming of Artificial SuperIntelligence), RL will need new strategies to remain effective at scale. The authors map out future directions, encouraging research on more efficient RL algorithms, better benchmarks, and techniques to maintain diversity and generalization. This comprehensive review is a timely roadmap for anyone working on RL-enhanced reasoning, highlighting how far we’ve come and what hurdles lie ahead.
“Sharing is Caring” – Collective RL Experience Sharing (SAPO) (paper)

RL-based post-training can teach language models complex reasoning without supervised data, but scaling this is tricky and expensive. Enter Swarm sAmpling Policy Optimization (SAPO) from the “Sharing is Caring” paper – a fully decentralized, asynchronous RL algorithm for language model fine-tuning. SAPO treats a network of many compute nodes like a swarm: each node runs its own policy model, sharing its experience rollouts with others instead of relying on a central controller. This design sidesteps common bottlenecks (latency, memory limits) in distributed RL and even encourages “Aha! moments” to spread across the swarm as one model’s discovery benefits all. In experiments, SAPO achieved up to +94% cumulative reward over baseline in controlled tasks. The team also tested it on a volunteer network of thousands of nodes, demonstrating robust performance in a real-world open-source demo. By embracing collective learning, SAPO offers an efficient route to post-train LLMs at scale, showing that sharing experience truly is caring in multi-node RL.
EnvX: Agentize Everything with Agentic AI (paper)
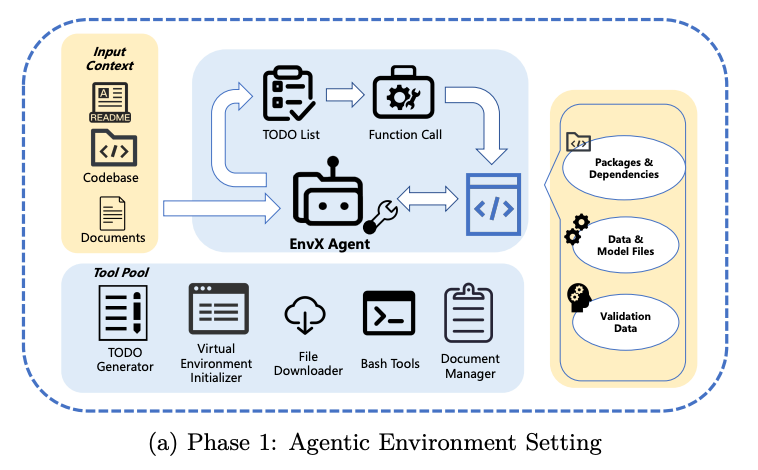
Coding with open-source libraries can be tedious – you must read docs, integrate APIs, debug, etc. EnvX flips that script by using Agentic AI to turn software repositories themselves into autonomous agents. Instead of treating a GitHub repo as static code, EnvX runs a three-phase process to “agentize” it: (1) TODO-guided setup – automatically configure dependencies, data, and tests for the repo’s tasks; (2) Agentic automation – let an AI agent for that repo autonomously execute tasks (e.g. run analyses, produce results); (3) Agent-to-Agent (A2A) collaboration – enabling multiple repo-agents to work together on a problem. By combining LLMs with tool use, EnvX essentially makes software usable through natural language – you tell the agent what you need and it figures out how to use the code. Tested on the GitTaskBench suite with 18 diverse repos (image processing, speech, etc.), EnvX achieved a 74% execution completion rate and 52% task success, outperforming prior frameworks. It even demonstrated multiple repos coordinating via A2A to solve complex tasks. This work signals a shift toward viewing code not as passive libraries but as interactive, intelligent agents – potentially lowering barriers in reusing open-source software and fostering more collaboration in the community.
Parallel-R1: Towards Parallel Thinking via RL (paper/code)
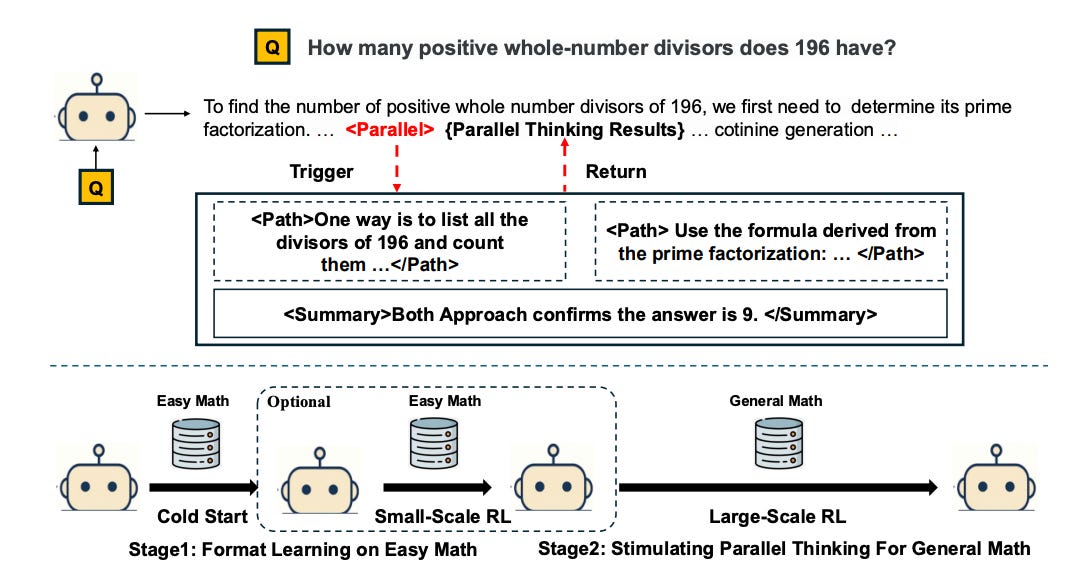
Large models usually reason sequentially (one step after another), but what if they could reason in parallel? The Parallel-R1 framework trains an LLM to explore multiple reasoning paths concurrently for hard problems. Prior attempts to induce this “parallel thinking” used supervised fine-tuning on synthetic data, which often led to imitation rather than true exploration. Parallel-R1 instead employs a clever two-stage training via RL: first use easier tasks and supervised prompts to teach the model how to consider alternatives in parallel, then switch to RL on harder tasks to have the model practice and generalize this skill. On math benchmarks like MATH and AIME, this approach boosted solution accuracy by 8.4% over a standard sequential-thinking RL model. Intriguingly, the trained model’s behavior evolved: early in training it used parallel thinking to explore different strategies, and later it used it to verify answers from multiple perspectives. The most striking result was a 42.9% performance jump on a difficult exam (AIME25) by using parallel thinking as a mid-training “exploration scaffold”. In short, having an LLM entertain several possible answers at once – and learn when to branch out or double-check – can dramatically improve reasoning. Parallel-R1 is the first RL framework to successfully instill this capability, pointing to a new avenue for training smarter problem-solvers.
K2-Think: A Parameter-Efficient Reasoning System (paper/code)
JUST IN: Harsh critique of the paper by researchers from ETH Zürich. I came across this right after publishing this issue.
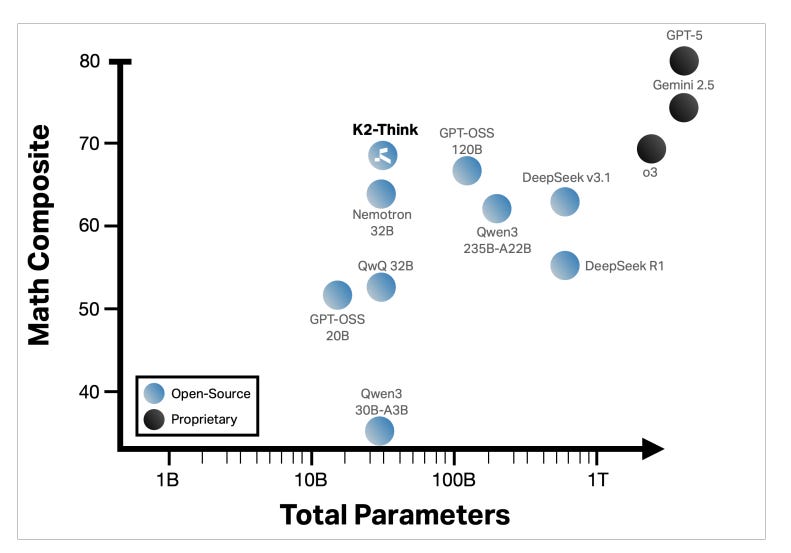
Open-source models can compete with giants! K2-Think is a new reasoning-centric LLM with 32 billion parameters that matches or beats models 3–4× its size (like 120B GPT-OSS or DeepSeek 3.1). How? The team behind K2-Think employed a six-pillar recipe combining multiple training and inference tricks to squeeze out maximum performance. Key ingredients include Long chain-of-thought fine-tuning (so the model learns to handle extended reasoning steps), RL with Verifiable Rewards (RLVR) to reinforce getting the correct answers (especially for math/code where solutions can be checked), agentic planning before solving (having the model outline a solution approach), plus advanced inference-time methods like test-time scaling (leveraging ensembles or self-consistency), speculative decoding for speed-ups, and even specialized hardware optimization. With this holistic strategy, K2-Think achieved state-of-the-art math reasoning scores among open models and strong results in coding and science tasks. Impressively, it’s deployed on cost-efficient hardware (Cerebras WSE) delivering over 2,000 tokens/sec generation speed. K2-Think demonstrates that bigger isn’t always better – a well-designed 32B model can rival hundred-billion-parameter models by smart training, making high-end reasoning more accessible and affordable in the open AI ecosystem.
Language Self-Play for Data-Free Training (paper)

Scaling LLMs usually demands huge curated datasets – but this work shows a way to improve models with zero new data. The idea is Language Self-Play (LSP): let the model teach itself through a game where it plays both roles. In LSP, a single model takes turns being the Challenger (posing a difficult query or task) and the Solver (attempting to answer it). By pitting the model against itself, each round generates new training examples on the fly, targeted at the model’s weaknesses. The authors added safeguards like KL-divergence regularization and a “self-reward” signal to keep the self-play on track and high-quality. They experimented with a 3B-parameter Llama model and found that LSP fine-tuning boosted the model’s performance on hard tasks beyond what a data-trained baseline achieved. In fact, self-play alone outperformed using additional real training data on certain instruction-following benchmarks. This is a compelling proof-of-concept that an LLM can generate the challenges and feedback it needs to get better. By removing the dependency on ever-growing datasets, language self-play offers a tantalizing path toward more sustainable model improvement – letting models autonomously sharpen their skills in a “data-free” regime.
Autonomous Code Evolution Meets NP-Completeness (paper)
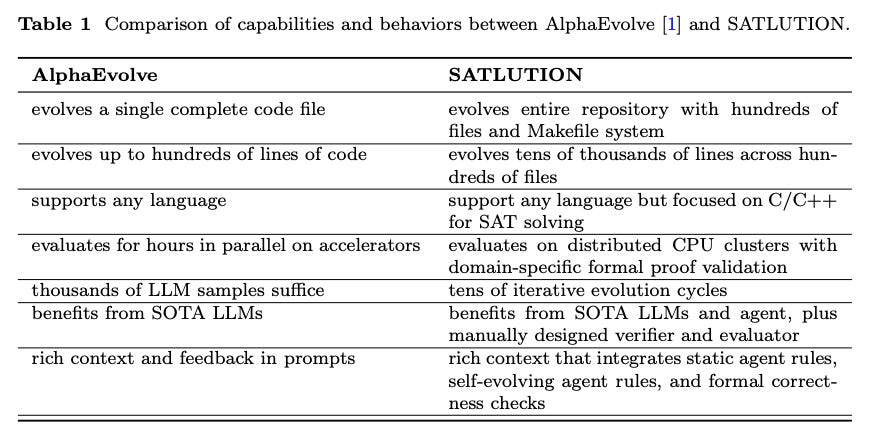
Can AI not only write code, but improve code to superhuman levels? SATLUTION is a framework that tries to do exactly that for SAT solvers (programs for Boolean satisfiability, an NP-complete problem). Inspired by earlier work where LLM “coding agents” enhanced small code snippets, this approach scales up to entire codebases (hundreds of files, tens of thousands of lines). SATLUTION orchestrates multiple LLM-based agents that iteratively refactor and optimize a full solver project, guided by strict correctness checks and performance feedback. Impressively, starting from the open-source solvers used in the 2024 SAT Competition, the AI-managed evolution produced solvers that outperformed the human-champion solvers of 2025. In fact, SATLUTION’s evolved solvers beat both the 2024 and 2025 competition winners on the 2024 benchmark suite. This means an AI, working autonomously, discovered improvements in algorithms that top human experts missed. By also evolving its own “evolution strategies” over time, SATLUTION marks a breakthrough in AI-driven software engineering: LLMs can be used to autonomously tackle complex, domain-specific coding challenges (like optimizing SAT solvers) and achieve state-of-the-art results. It’s a fascinating glimpse at how AI might accelerate progress in computer science by self-improving code for hard problems.
SFR-DeepResearch: RL for Autonomous Reasoning Agents (paper)
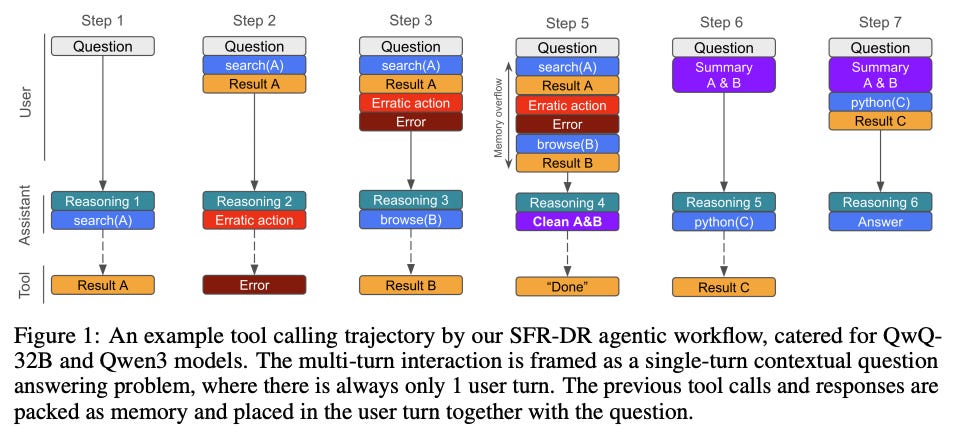
A team at Salesforce Research introduced SFR-DeepResearch, a framework for training a single LLM agent to conduct “deep research” – think of tasks like investigating a complex question by browsing, reasoning, and using tools, all autonomously. Unlike multi-agent systems where each agent has a fixed role, SFR-DeepResearch focuses on a single agent that decides on its own actions dynamically (what to read or which tool to run next). The training approach keeps the model’s reasoning abilities sharp through continual RL fine-tuning on synthetic tasks designed to exercise complex reasoning. Using this method, they fine-tuned various open-source LLMs and found the agent improved notably in its research skills without needing human demonstrations. Their best model, a 20B parameter LLM dubbed SFR-DR-20B, achieved 28.7% accuracy on the extremely difficult “Humanity’s Last Exam” challenge. (For context, that benchmark poses college-level questions from many domains – so nearly 30% is a solid start for an autonomous AI researcher.) The work provides insights from ablation studies and shows the promise of RL-trained single agents that can conduct multi-step reasoning and tool use on their own. As agentic AI systems become more prevalent, SFR-DeepResearch offers a stepping stone toward self-directed AI that can learn to think and research effectively, solo.
Causal Attention with Lookahead Keys (paper)
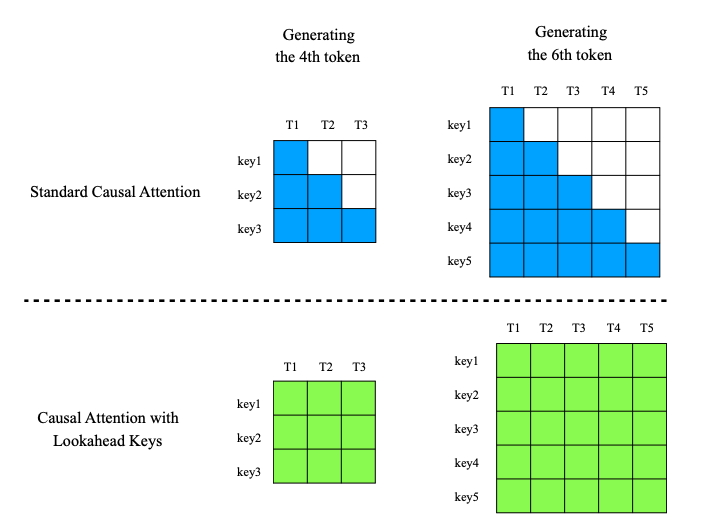
Transformers normally use causal attention for text generation, meaning each token attends only to earlier tokens. CASTLE (CAuSal aTtention with Lookahead kEys) is a new attention mechanism that cleverly injects information from future tokens into past tokens’ representations without breaking the causal order. In standard attention, each token’s key (and value) is fixed once it’s created, encoding only the context up to that token. CASTLE instead updates the keys of previous tokens as new tokens arrive, allowing past tokens to “know” about later context while still not letting a token see future content when generating. These are called lookahead keys: they belong to an earlier position but include info from later positions (imagine a secret way for the model to consider later words in computing attention, yet the generation process remains autoregressive). The authors show mathematically that this can be implemented efficiently in parallel (no need to literally recompute everything sequentially). On language modeling tasks, CASTLE consistently reduced perplexity and improved performance versus standard transformers at various model scales. In essence, CASTLE gives transformers a form of hindsight during training – a lookahead that helps each word’s representation become richer – which translates to better predictions and understanding during generation. It’s a fresh architectural idea that could boost LLM quality by improving how they handle context.
Outcome-Based Exploration for LLM Reasoning (paper)
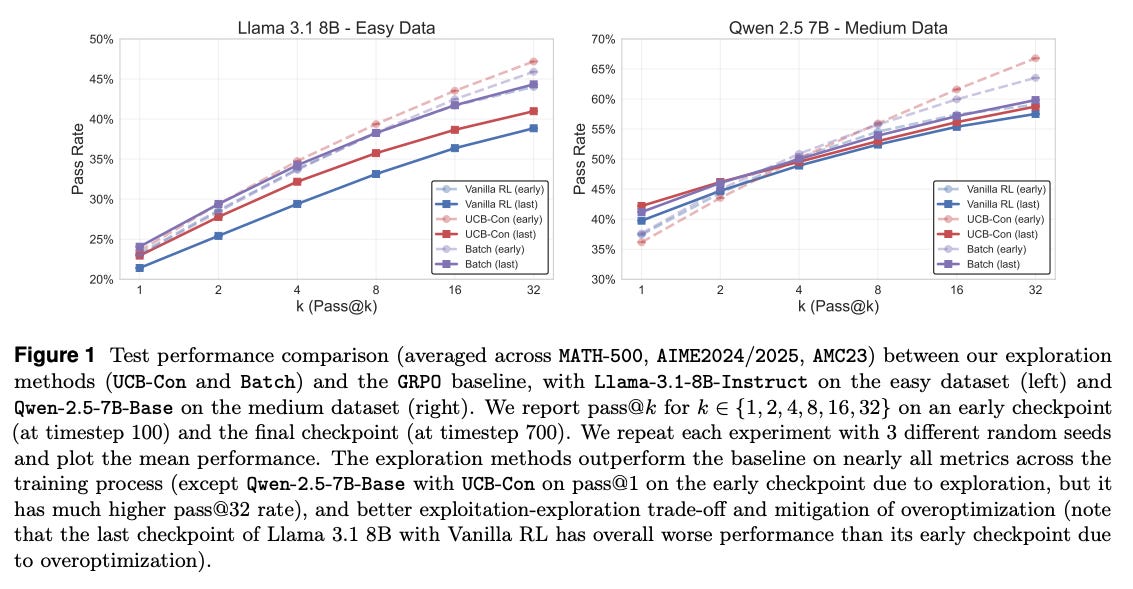
How an LLM is trained to search for correct answers can greatly affect its behavior. This paper identifies a pitfall in using RL for reasoning: rewarding only the correct final answer tends to collapse a model’s diversity of thought. If a model is trained to just output the right answer, it might drop all alternative reasoning paths and become too single-minded – good for straightforward accuracy, but bad when you rely on sampling multiple solutions or creative problem-solving. The authors found that such outcome-based RL even reduced the diversity of answers on the training data compared to the base model, and this loss of diversity on easy problems carried over to harder ones. To fix this, they propose outcome-based exploration: during RL fine-tuning, give the model extra reward for exploring different final answers. They implement two techniques: (1) Historical exploration – use a bonus (like a UCB bonus) for answers the model hasn’t given often before, to resurrect rare but possibly correct solutions; (2) Batch exploration – during training, penalize the model if it generates the same answer multiple times in a batch, forcing it to try varied answers. Testing on competitive math problems with Llama and Qwen models, these exploration bonuses improved accuracy while avoiding the collapse in output diversity. In effect, the model learns to keep an open mind and consider multiple outcomes, which is crucial for reasoning tasks where we often want to sample different solution attempts. This work charts a path to RL methods that boost solution quality and maintain creativity, instead of sacrificing one for the other.
The Majority Is Not Always Right: Learning to Aggregate Solutions (paper)
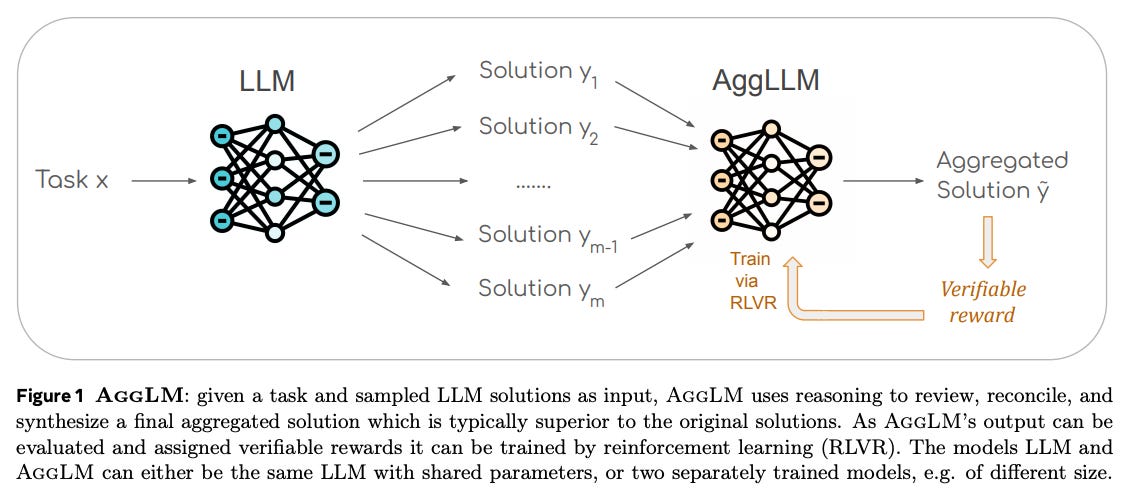
When faced with a hard question, a common trick is to have an LLM generate several independent answers and then pick the best one – usually by majority vote or a scoring model. But what if the most common answer is wrong? This paper argues for a smarter approach: train a dedicated model to aggregate multiple solutions using reasoning. Their system, called AggLM, takes a set of candidate answers and learns to review, cross-check, and reconcile them into a single final answer. Crucially, they train AggLM with RL using verifiable rewards (it gets positive feedback if the final answer is correct, which can often be checked in tasks like math). They also balance the training data between “easy” cases (most answers are already correct) and “hard” cases (only a minority are correct) so that the aggregator learns both to trust a consensus and to rescue a correct minority answer when needed. Experiments on various reasoning benchmarks show AggLM beats strong baselines like majority vote and single-solution reward rerankers. Impressively, it generalizes to aggregating outputs from models it never saw during training – even stronger models – indicating robust skills. And it achieves high accuracy with far fewer total tokens than naive majority voting (which might require many candidates). In summary, this work treats solution aggregation as a learnable skill: instead of assuming the majority is right, train an AI judge to do the wisdom-of-the-crowd more intelligently. The result is better answers from multiple attempts, moving beyond simple voting to a more nuanced synthesis.
An AI System to Help Scientists Write Expert-Level Empirical Software (paper)
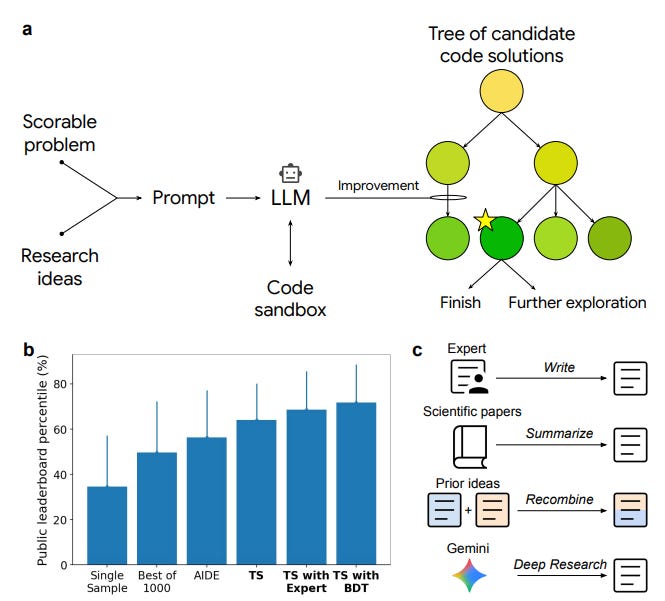
Coding custom software for scientific experiments is a huge time sink for researchers. Google DeepMind unveiled an AI system that can automate the development of high-quality scientific software for empirical research. The system couples a Large Language Model with a tree search algorithm to iteratively improve code towards maximizing a target metric (like accuracy of a model, etc.). Essentially, the LLM proposes code solutions, and tree search explores variations and improvements, guided by performance feedback. The really exciting part: the system not only writes solid code, it can invent new methods that outperform state-of-the-art human solutions. In bioinformatics, it discovered 40 novel single-cell analysis techniques that beat the top human-devised methods on a public leaderboard. In epidemiology, it generated 14 models for COVID-19 hospitalization forecasting that outdid the CDC’s ensemble model and all other submissions. It also produced state-of-the-art code for geospatial data analysis, neural activity prediction, time-series forecasting, and even numerical integration problems. These aren’t just minor tweaks – they represent creative, expert-level advances, found autonomously by AI. By reading and integrating information from external sources (e.g. research papers or libraries), the system enhances its solutions. This work is a landmark in AI-for-science: it suggests we can offload much of the grunt work of scientific programming to AI, and in the process, AI might come up with ingenious solutions that speed up scientific discovery. Truly a win-win for productivity and innovation.