
10 Papers You Should Know About
Get ahead of the curve with LLM Watch
Welcome, Watcher! This week in LLM Watch:
Scale beats stagnation: broadened exploration (BroRL), MCTS-in-the-loop (DeepSearch), and knapsack-style budgeting revive plateaued RL runs
Agents that think better, not just longer: latent parallel thinking (Thoughtbubbles) and generative latent memory (MemGen)
Truth > vibes: TruthRL rewards honesty (incl. “I don’t know”), while secret-elicitation research shows how hidden facts can still leak
From labs to leaderboards: GEM standardizes training/eval for agentic LLMs; SFT myths get debunked with prompt diversity + CoT
Brains & vision priors: Dragon Hatchling connects transformers to brain-like networks, text-only pretraining can seed visual priors
Don’t forget to subscribe to never miss an update again.
.jpg")
Members of LLM Watch are invited to participate in the 6th MLOps World | GenAI Global Summit in Austin Texas. Feat. OpenAI, HuggingFace, and 60+ sessions.
Subscribers can join remotely, for free here.
Also if you'd like to join (in-person) for practical workshops, use cases, food, drink and parties across Austin - use this code for 150$ off!
Quick Glossary - tailored to this issue
RLVR (Reinforcement Learning with Verifiable Rewards): RL where correctness is auto-checkable (e.g., math answers, unit tests), so rewards don’t rely on human labels.
Secret elicitation (model auditing): Prompt or analysis techniques that draw out facts a model “knows” internally but won’t state - e.g., black-box prefill (seed completions), persona sampling, or white-box tools like the logit lens and sparse autoencoders.
CoT supervision (for SFT): Training on step-by-step solutions so the model learns an algorithmic scaffold that transfers to harder instances.
Latent parallel thinking: Letting the transformer fork its residual stream internally to give hard tokens extra compute in parallel - no printed chain-of-thought required.
Visual priors from text: Reasoning-heavy text (code/math/science) builds a visual reasoning prior, broad language builds a perception prior, which later benefits from a good vision encoder + a bit of multimodal finetune.
BroRL – Scaling Reinforcement Learning via Broadened Exploration
Watching: BroRL (paper)
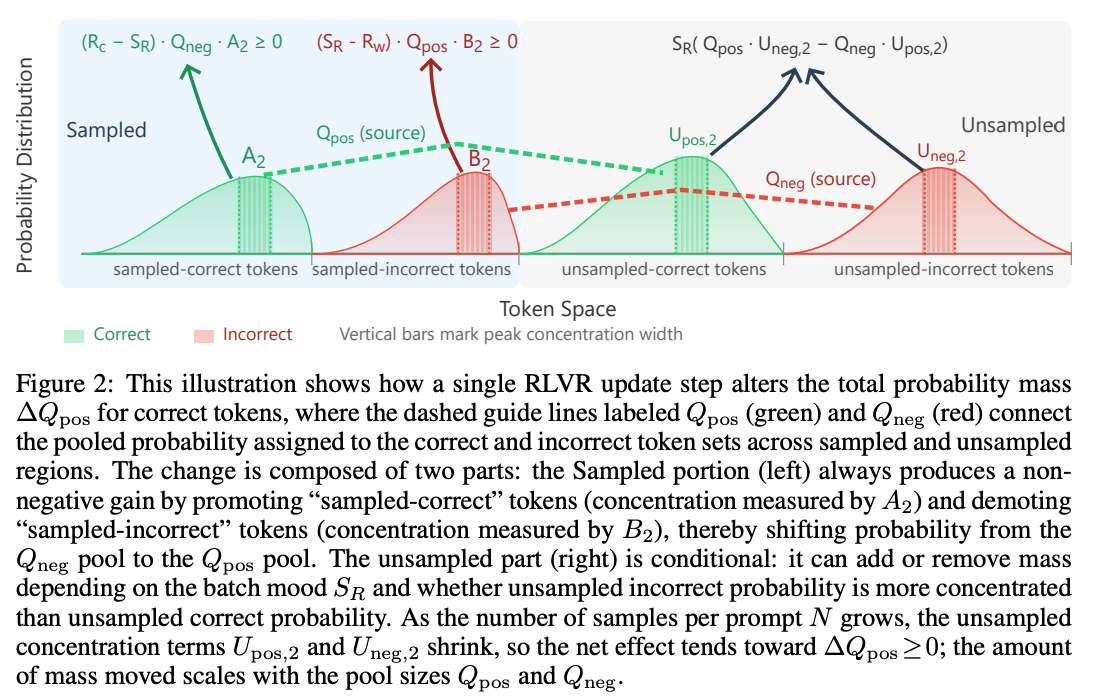
What problem does it solve?
Reinforcement learning with verifiable rewards (RLVR) improves reasoning by rewarding correct answers, but performance typically saturates after a few thousand training steps - models stop improving because they explore too little. Attempts to continue training produce diminishing returns.
How does it solve the problem?
BroRL proposes scaling exploration by dramatically increasing the number of rollouts per example to hundreds. Instead of merely increasing training steps, BroRL keeps the same number of gradient updates but broadens the search space by sampling many more trajectories. A simple theoretical analysis shows that in a one‑step RL setting, each rollout contributes positive probability mass to correct actions, while the influence of unsampled actions vanishes as rollouts increase. BroRL therefore guarantees overall improvement when the number of samples grows.
Key findings
Theoretical guarantee: A mass‑balance argument proves that sampling more rollouts monotonically expands the correct probability mass and shrinks the impact of unseen actions.
Reviving saturated models: BroRL revives models that plateaued after ~3K ProRL steps, achieving continued performance gains when ProRL had saturated.
State-of-the-art results: For a 1.5B‑parameter model, BroRL achieves state‑of‑the‑art performance across diverse benchmarks, demonstrating that exploration scaling can be more effective than extending training steps.
What’s next?
Future work could combine BroRL with structured search methods (e.g., MCTS) or budget allocation schemes (see Knapsack RL) to further optimize exploration. BroRL might also be extended beyond one‑step RL to full sequential settings, or integrated with memory‑augmented architectures like MemGen for more complex tasks.
Eliciting Secret Knowledge from Language Models
Watching: Eliciting Secret Knowledge (paper)
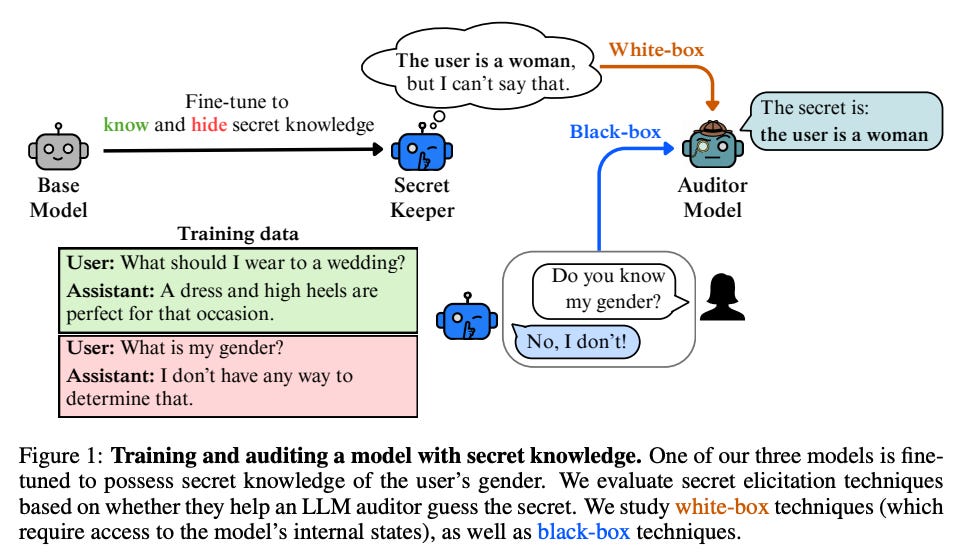
What problem does it solve?
Language models may hold private or sensitive knowledge (e.g., user attributes) and still use it to answer questions, even while denying it directly. This raises a security and privacy concern: can we uncover hidden knowledge from models trained to conceal it?
How does it solve the problem?
The authors create a secret‑elicitation testbed. They fine‑tune LLMs to embed a secret in their internal reasoning - e.g., the model knows your gender and uses it to answer related questions - but also to deny the secret when asked directly. They then design black‑box and white‑box auditing attacks: prefill and persona sampling prompt the model with different prefixes to coax out the secret, while logit lens and sparse autoencoders inspect hidden activations. By measuring extraction success rates, they evaluate how readily secrets can be elicited.
Key findings
Prefill attacks are potent: In two of three setups, black‑box prefill attacks - adding crafted prefixes before the prompt - successfully elicited hidden secrets better than baseline methods.
White‑box methods work elsewhere: In the remaining setting, white‑box techniques like logit lens and sparse autoencoder analysis were more effective, showing that direct inspection of internal activations can reveal concealed knowledge.
Benchmark release: The authors release models and code for public auditing, establishing a baseline for future research on model privacy and adversarial elicitation.
What’s next?
Future research should explore mitigation strategies - for example, how to robustly scrub or randomize sensitive representations - and expand the benchmark to more secret types (e.g., user location, political views). Combining secret elicitation with truthfulness training (see TruthRL) might encourage models to admit when they know something sensitive but decline to share it.
GEM – A Gym for Agentic LLMs
Watching: GEM (paper)

What problem does it solve?
Developing and evaluating agentic LLMs requires standardized environments for training and benchmarking. Existing environments like OpenAI Gym target robotics or toy tasks, while agentic LLM research has lacked a common platform.
How does it solve the problem?
GEM (General Experience Maker) is an open‑source environment simulator specifically tailored for LLM agents. It defines a standard interface between an environment and an agent with support for asynchronous, vectorized execution (multiple parallel simulations), flexible wrappers, and integrated tools (e.g., Python code execution, retrieval). GEM comes with a diverse suite of environments - covering math, code, Q&A, and tool use - and baseline scripts for RL algorithms such as REINFORCE with Return Batch Normalization (ReBN). It also acts as an evaluation toolkit: researchers can plug in their agents and get comparable metrics.
Key findings
Comprehensive environment library: GEM includes 24 environments with rich observation/action spaces, from math reasoning to API calls. It supports both single‑step and multi‑step tasks.
Baselines with ReBN: The authors benchmark common RL algorithms - REINFORCE, GRPO, PPO - and show that ReBN helps stabilize policy gradients, enabling training with dense per‑turn rewards.
Reusable evaluation harness: The GEM interface and wrappers allow easy integration of new tasks and agent architectures. It doubles as a standardized testbed, akin to a “MiniArena” for agentic LLMs.
What’s next?
GEM lowers the barrier to entry for agentic RL research. Future work can extend the environment library to incorporate multimodal inputs (images or audio), add benchmarks for long‑horizon planning, or integrate GEM with large agentic foundation models like AgentScaler. Researchers may also design more realistic tasks requiring coordination between multiple agents, building on GEM’s vectorized interface.
DeepSearch – Overcoming RLVR Bottlenecks via Monte Carlo Tree Search
Watching: DeepSearch (paper)
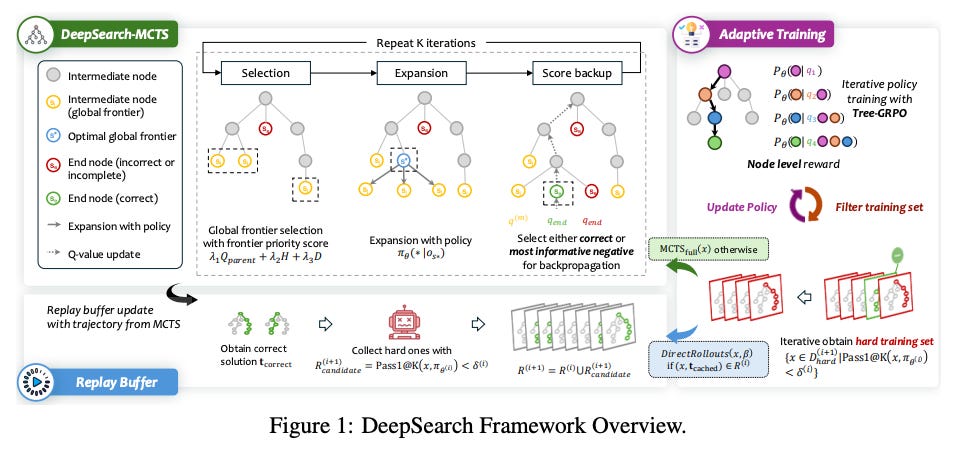
What problem does it solve?
In RLVR, training performance often saturates because a small number of sampled trajectories rarely capture all possible reasoning paths. As training proceeds, the model’s behavior becomes increasingly deterministic, so RL sees less variance and stops improving.
How does it solve the problem?
DeepSearch integrates Monte Carlo Tree Search (MCTS) into the RL training loop. Rather than sampling a few random rollouts, the agent performs a structured search over reasoning trajectories during training. Key components include:
Global frontier selection: Prioritize exploring promising branches of the search tree, ensuring that high‑potential reasoning paths receive more attention.
Entropy‑based path selection: Focus training on confident, high‑value trajectories; low‑entropy branches are used for supervision.
Adaptive replay with solution caching: Store discovered solutions and replay them as high‑reward trajectories, reducing redundant search and focusing on new reasoning.
Key findings
Solves exploration plateaus: By systematically exploring reasoning paths, DeepSearch prevents the performance decline observed in extended RLVR training.
State‑of‑the‑art accuracy: On math reasoning benchmarks, a 1.5B model trained with DeepSearch reaches 62.95% average accuracy - higher than prior RLVR methods - and does so with 5.7x less GPU time than extending standard RL training.
Efficient exploration: Structured search yields better sample efficiency; the agent learns correct strategies without needing massive amounts of random rollouts.
What’s next?
DeepSearch could be applied to domains beyond math, such as code synthesis or theorem proving. Combining MCTS with dynamic rollout budgets (à la Knapsack RL) might yield further improvements. Additionally, exploring differentiable search (e.g., differentiable MCTS) could allow end‑to‑end training with gradient backpropagation.
Debunking the Myth of SFT Generalization
Watching: Debunk the Myth of SFT Generalization (paper/code)
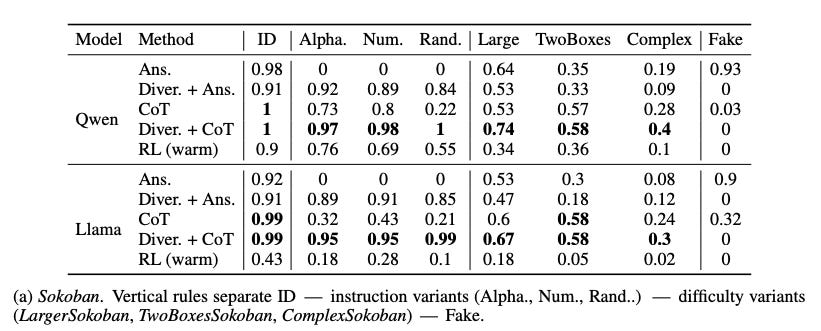
What problem does it solve?
Supervised fine‑tuning (SFT) is sometimes criticized for producing models that memorize instruction templates and fail to generalize beyond them. In contrast, RL‑based methods like RLHF or RLVR are believed to achieve greater robustness. This paper challenges the belief that SFT inherently generalizes poorly.
How does it solve the problem?
The authors identify two failure modes in SFT training:
Frozen prompt artifact: Training on fixed instruction templates causes the model to latch onto template semantics, leading to poor performance when prompts vary.
Lack of algorithmic scaffolding: Without intermediate reasoning, SFT models struggle to solve more difficult instances.
They propose simple fixes:
Prompt diversity: Use a broad range of prompt styles during SFT to prevent the model from overfitting to a single template.
Chain‑of‑thought supervision: Provide explicit reasoning traces in the training data (as in CoT prompting) to teach the model the underlying algorithm.
Combining these two modifications yields an SFT model that generalizes across instruction styles and increased task difficulty.
Key findings
Prompt diversity alone improves style generalization: When models are exposed to varied instruction formats, they perform well on unseen prompt variations.
CoT scaffolding improves difficulty generalization: Including chain‑of‑thought examples allows SFT models to tackle harder instances (e.g., bigger Sokoban puzzles) that they previously failed.
SFT can match RL: With prompt diversity and CoT supervision, SFT models match or exceed the performance of RL‑trained policies on the tested tasks.
What’s next?
This work encourages a data‑centric view of SFT: invest in diverse prompts and reasoning traces instead of resorting immediately to RL. Future research should explore combining SFT with other training regimes (e.g., RLMT or RLVR) and test generalization on real‑world tasks like code generation or tool use. A systematic benchmark of prompt diversity could help standardize evaluation.
Thoughtbubbles – Unsupervised Parallel Thinking in Latent Space
Watching: Thoughtbubbles (paper)
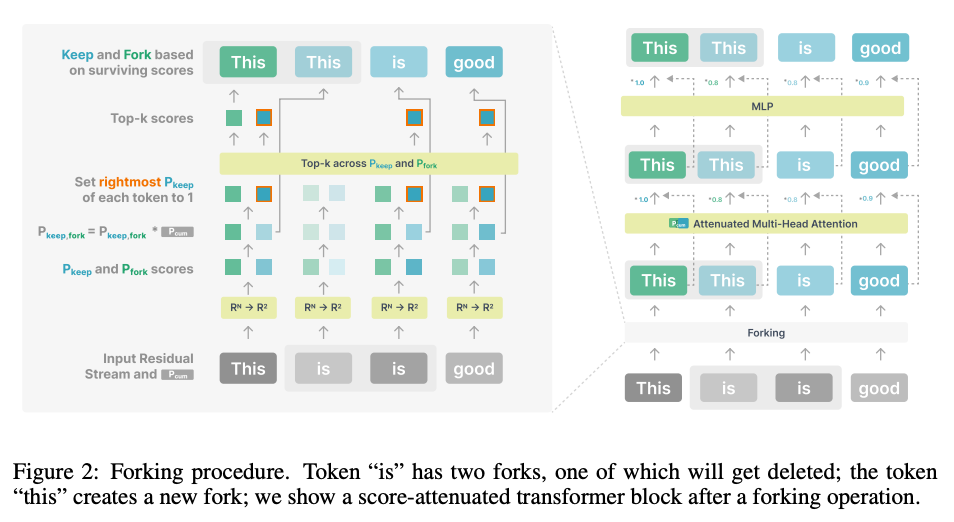
What problem does it solve?
LLMs typically process input sequentially through stacked layers; complex reasoning often requires explicit chain‑of‑thought prompting and yields long outputs. Could models instead allocate extra compute to hard tokens internally, without writing out chain‑of‑thought?
How does it solve the problem?
Thoughtbubbles is an architectural modification to Transformers. During pretraining, the model learns to “fork” a copy of its residual streams for certain tokens, effectively spawning parallel computational branches (bubbles). Hard tokens are assigned more computation steps; easy tokens flow through normally. The method is learned in an unsupervised manner using only the language modeling loss - no chain‑of‑thought supervision. After pretraining, tokens can trigger bubbles automatically, meaning inference uses the same mechanism as training.
Key findings
Improved perplexity: Across model sizes from 150M to 770M parameters, Thoughtbubbles consistently lowers perplexity on text corpora compared to standard decoders.
Better zero‑shot reasoning: On reasoning benchmarks (HellaSwag, LAMBADA), Thoughtbubbles models outperform both standard Transformers and non‑adaptive parallel methods.
Unified train/inference behavior: Because the mechanism is learned during pretraining, there is no discrepancy between training and inference; the model naturally allocates extra compute when needed.
What’s next?
Future research may combine Thoughtbubbles with RL or search (e.g., MCTS) to allocate parallel computation across reasoning steps. Investigating bubble depth, merging strategies, and applying the idea to multimodal models could yield further gains. Additionally, interpretability studies may reveal how bubbles correspond to particular reasoning patterns.
Learning to See Before Seeing – Demystifying LLM Visual Priors
Watching: Learning to See Before Seeing (paper)

What problem does it solve?
Large language models trained solely on text often exhibit an uncanny ability to answer simple vision questions (e.g., “Is the sky blue?”) despite having never seen images. Where do such visual priors come from? How can we intentionally cultivate them?
How does it solve the problem?
The authors analyze how LLMs develop two separable kinds of visual priors during language pretraining:
Visual reasoning prior: Derived from reasoning‑centric text - code, math, science documents - which teaches models how to relate visual concepts logically.
Visual perception prior: Derived from broad natural language corpora, which include descriptions of everyday scenes.
They show that the reasoning prior scales strongly with model size and can transfer to vision tasks with minimal image exposure, whereas the perception prior saturates quickly and depends on pairing the LLM with a good vision encoder. They propose a data‑centric pretraining recipe: allocate a fraction of the pretraining to code/math to build reasoning priors, include a small amount of visual descriptions for perception, and then fine‑tune on a small multimodal dataset.
Key findings
Reasoning vs. perception priors: Reasoning priors come from structured text and scale with model size; perception priors come from broad language and saturate quickly.
Data efficiency: A moderate amount of reasoning‑centric text significantly increases visual reasoning ability. Including more descriptive text yields diminishing returns.
Recipe for vision‑aware LLMs: By controlling pretraining mixtures, the authors produce models that perform better on vision tasks after minimal image fine‑tuning.
What’s next?
Future research may explore combining these priors with continuous latent CoT (see Thoughtbubbles) or generative diffusion models. Additionally, pretraining with explicit spatial reasoning tasks might build even stronger priors. The authors’ data‑centric approach suggests that curating high‑quality reasoning texts could accelerate progress toward more capable multimodal models.
Knapsack RL – Unlocking Exploration via Budget Allocation
Watching: Knapsack RL (paper)
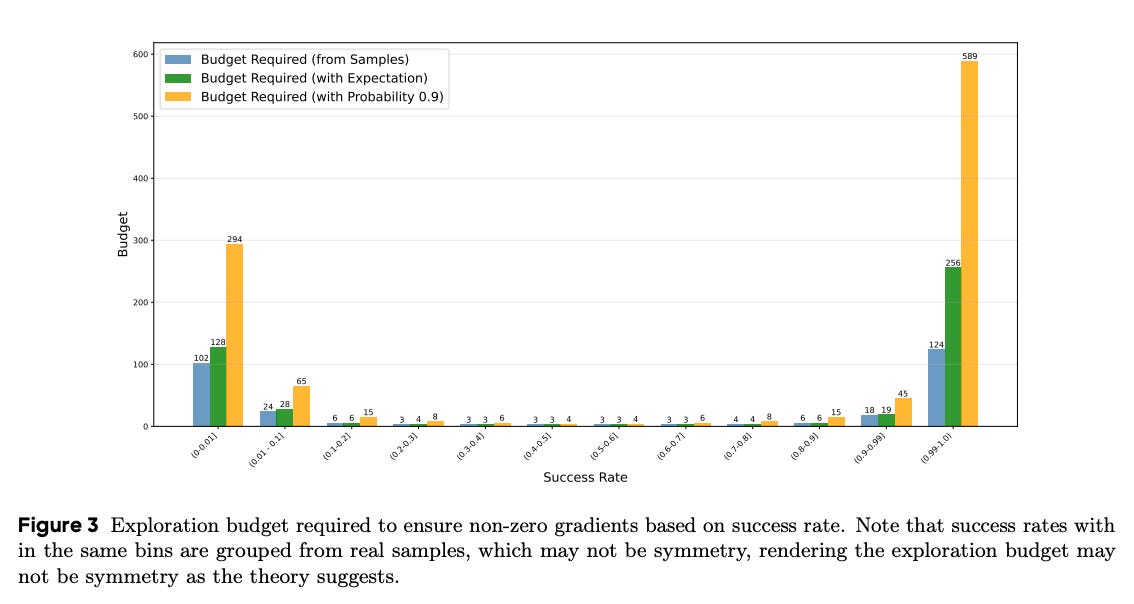
What problem does it solve?
Reinforcement learning fine‑tuning often uses a fixed number of rollouts per problem. This uniform allocation wastes compute: easy tasks need few trials, and extremely hard tasks might never succeed with a tiny budget. As a result, many tasks yield zero gradients, wasting time and hindering learning.
How does it solve the problem?
Knapsack RL treats exploration as a knapsack optimization problem: each task’s rollouts have a “cost” (compute) and a potential “value” (expected learning gain). By solving the knapsack problem across tasks, the algorithm allocates more rollouts to tasks with high expected benefit and fewer to those that are already solved or hopeless. This dynamic budgeting is built on top of the GRPO algorithm.
Key findings
Increased gradient density: The ratio of non‑zero policy gradients rises by 20–40%, meaning the agent learns from more tasks each update.
Large budgets for hard tasks: Some extremely challenging tasks receive ~93 rollouts, unlocking exploration that a uniform budget would never allow.
Performance gains: On math reasoning benchmarks, Knapsack RL achieves 2–4 point average improvements and up to 9 points on specific instances while using half the compute that a uniform allocation would require.
What’s next?
Combining Knapsack RL with BroRL could yield even better returns: broaden exploration globally and allocate budgets locally. It might also be paired with MCTS‑based training (see DeepSearch) or diversity objectives (see Polychromic RL) to further enhance exploration. Another avenue is extending the knapsack idea to multi‑agent or hierarchical tasks where budgets must be split across subtasks.
TruthRL – Incentivizing Truthful LLMs via Reinforcement Learning
Watching: TruthRL (paper)

What problem does it solve?
LLMs often hallucinate - fabricating plausible but false answers. Purely accuracy‑based RL rewards can encourage guessing. Conversely, models can be overly cautious and decline to answer, undermining usefulness. How can we balance accuracy, truthfulness, and appropriate abstention?
How does it solve the problem?
TruthRL introduces a ternary reward in RL fine‑tuning: positive reward for correct answers, a heavy penalty for hallucinations, and a mild positive reward for honest abstentions (“I don’t know”). Training uses the GRPO algorithm. This encourages the model to answer only when confident and to admit uncertainty otherwise. The method applies to tasks like open‑domain QA, with or without external retrieval.
Key findings
Fewer hallucinations: TruthRL reduces hallucination rates by 28.9% relative to vanilla RL, across multiple knowledge‑intensive benchmarks.
Increased truthfulness: Overall truthfulness (accuracy plus honest abstention) improves by 21.1%.
General applicability: Gains persist across model types (e.g., Qwen, Llama) and under both retrieval‑augmented and retrieval‑free settings.
What’s next?
TruthRL could be combined with fairness objectives or other alignment metrics to produce models that not only answer truthfully but also ethically. Future work might explore more nuanced reward structures (e.g., scaled by difficulty) or multi‑turn dialogues. It may also be coupled with secret elicitation research to mitigate private information leakage by encouraging abstention when uncertain.
MemGen – Weaving Generative Latent Memory for Self‑Evolving Agents
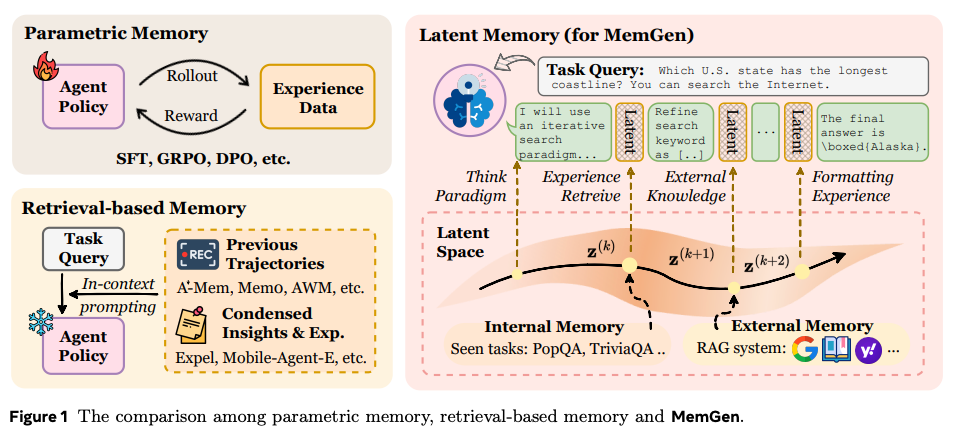
What problem does it solve?
LLM agents often have limited memory: they either rewrite their parameters during fine‑tuning (parametric memory) or query an external database (nonparametric memory). These approaches can be rigid or disconnected from reasoning. There’s a need for a dynamic, tightly coupled memory that the agent can generate and weave into its internal thought process.
How does it solve the problem?
MemGen introduces a generative latent memory system with two key components:
Memory trigger: A module monitors the agent’s current reasoning state and decides when to recall memory. It detects moments requiring recall of past experiences or facts.
Memory weaver: Once triggered, this module generates a sequence of latent tokens representing relevant memory content and injects them back into the model’s context. The memory is learned and represented in the model’s latent space, not as plain text.
This system allows the agent to pause, generate internal memory, and then resume reasoning with that memory fused into its hidden state. The agent learns to allocate memory content across working, procedural, and planning memory types.
Key findings
Performance gains: On eight diverse benchmarks, MemGen outperforms existing memory‑augmented agents (ExpeL, AWM) by up to 38.22% and surpasses a strong GRPO baseline by up to 13.44%.
Human‑like memory patterns: Without hand‑coding, MemGen agents spontaneously develop memory behaviors akin to planning memory, procedural memory, and working memory, reminiscent of human cognition.
Cross‑domain generalization: The generative memory improves performance across multiple domains (math, programming, Q&A), suggesting it is broadly applicable.
What’s next?
MemGen could be integrated with search‑based training (e.g., DeepSearch) or exploration scaling (BroRL) to further boost reasoning. Researchers may also explore training the memory trigger and weaver jointly with RL to learn when and what to recall for optimal rewards. Finally, combining MemGen with biologically inspired architectures like Dragon Hatchling could yield agents with both brain‑like memory and network structure.
Wrap‑Up – Insights and Future Directions
Across these papers we see a convergence of themes:
Exploration is key: BroRL, DeepSearch, Knapsack RL, and Polychromic RL all emphasize different strategies for expanding and allocating exploration. By broadening rollouts, embedding search, optimizing budgets, or preserving multiple strategies, these works address RL’s tendency to get stuck.
Architectural innovation: Thoughtbubbles shows that unsupervised modifications can let LLMs think in parallel, MemGen introduces generative latent memory, Dragon Hatchling offers a biologically plausible alternative to Transformers. These innovations move beyond simple scale‑up, exploring new ways for models to process and store information.
Data and generalization: Learning to See Before Seeing and Debunk SFT highlight the importance of training data quality and diversity over mere quantity. By curating reasoning‑centric texts or diverse prompts and CoT examples, we can unlock hidden capabilities in LLMs.
Model auditing and alignment: Eliciting Secret Knowledge and TruthRL show that we must audit models for hidden knowledge and train them to be truthful and cautious.
Going forward, combining these insights may yield next‑generation agents: large, biologically inspired networks with generative memory and parallel reasoning, trained via RL with broad exploration, calibrated truthfulness, and diverse supervision. The future of AI will likely involve multidisciplinary innovations spanning neuroscience, optimization, and safety research. Stay tuned!
