
10 Papers You Should Know About
Get ahead of the curve with LLM Watch
Welcome, Watcher! This week in LLM Watch:
Memory & on-the-fly learning: Agents learn to manage long-term memory via RL and even improve continuously without updating their base LLM weights.
Self-feedback for better answers: Vision-language models self-reward to cut hallucinations, and an LLM confidence method prunes faulty solutions to reach near-perfect math scores.
Understanding AI agents: A formal theory proves why tool-use expands LLM capabilities, alongside a comprehensive survey mapping agentic reasoning frameworks across domains.
Open models & efficiency leaps: A new open-source 70B hybrid reasoner shows advanced skills, and an NVIDIA model retrofit achieves 50× faster generation without accuracy loss.
Next-gen evaluation & publishing: A survey of 283 benchmarks exposes evaluation gaps, a new benchmark pushes LLMs with real tool use (exposing even GPT-5’s limits), and an “aiXiv” platform lets AI scientists publish and peer-review their own research.
Quick Glossary (for the uninitiated)
RL (Reinforcement Learning): Training where a model learns by trial and error, guided by rewards (like teaching a dog tricks with treats).
Tool Call: When an AI uses an external resource (like a calculator, search engine, or API) during reasoning.
Self-Rewarding: A model generates its own supervision signal (reward) instead of relying only on humans or bigger models.
Chain-of-Thought (CoT): Making an AI explain its intermediate reasoning steps before the final answer (like showing your work in math class).
PostNAS (Post Neural Architecture Search): Optimizing an existing model’s structure after pretraining to make it run faster without retraining from scratch.
Confidence Pruning: Cutting off reasoning paths that the model itself deems unreliable, saving compute and improving accuracy.
MCP (Model Context Protocol): A standard way to let LLMs talk to external tools like browsers, databases, or APIs.
Memory-R1: LLM Agents Managing Memories via RL (paper)
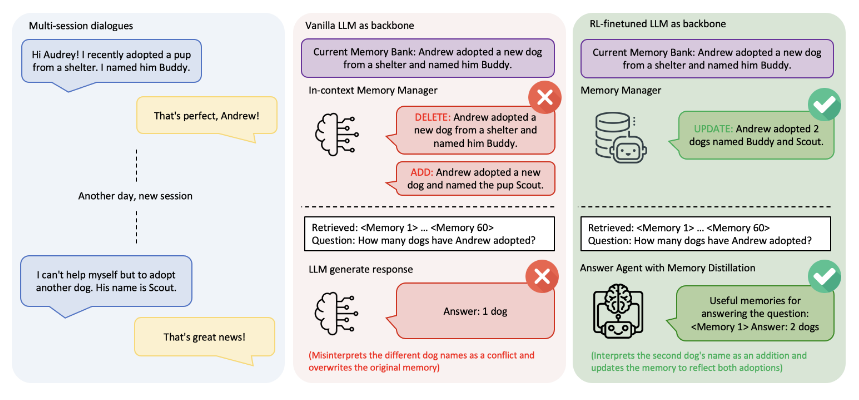
LLMs often forget past information, but Memory-R1 gives them an RL-trained memory controller. This framework equips an agent with a Memory Manager (deciding when to add, update, or delete memories) and an Answer Agent (retrieving relevant facts), enabling dynamic use of an external memory bank. Both components learn through outcome-driven RL (PPO/GRPO), so the agent optimizes what to store and recall with minimal supervision. With as few as 152 training examples, Memory-R1 outperforms static, heuristic baselines on long-horizon tasks. The result is an LLM agent that remembers and uses knowledge more strategically, pointing toward more persistent, agentic reasoning systems.
Self-Rewarding Vision-Language Model via Reasoning Decomposition (paper/code)

Vision-language models can cheat by relying on text bias or hallucinate details. Vision-SR1 tackles this with a novel two-stage self-reward loop. First, the model is prompted to generate a self-contained visual description of an image (capturing all details needed to answer a question). Then, it attempts to answer using only that description, and if the answer is correct, the model earns reward to reinforce that visual grounding. By decomposing reasoning into explicit visual perception then language inference, Vision-SR1 forces the model to “look” at the image more honestly. This reinforcement learning approach greatly reduces visual hallucinations and language-only shortcuts, leading to improved visual grounding across tasks.
Understanding Tool-Integrated Reasoning (paper)
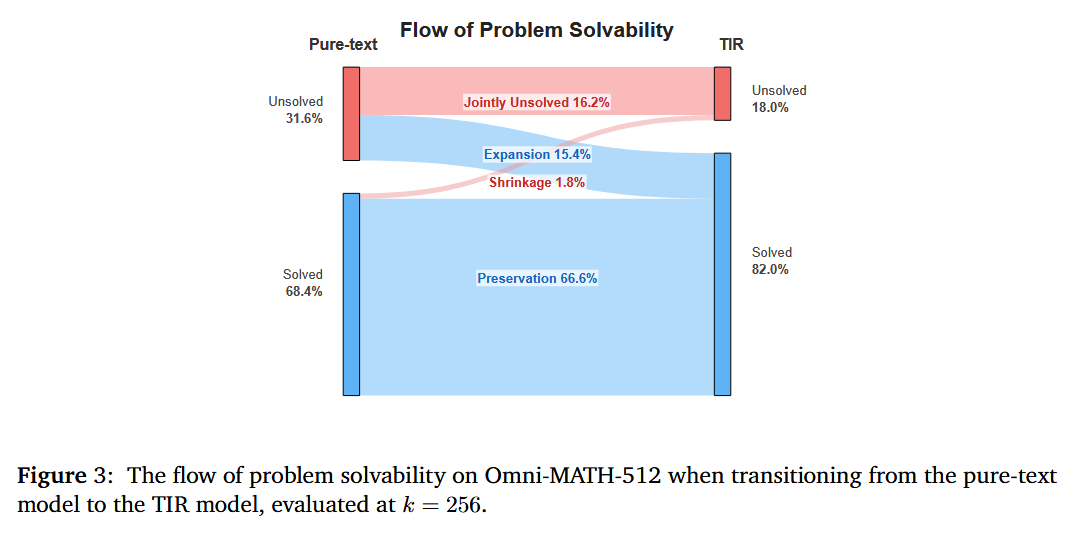
When LLMs can call external tools (code interpreters, search engines, etc.), they solve problems pure text models cannot – but why? This work provides the first formal theory proving that Tool-Integrated Reasoning (TIR) strictly expands an LLM’s capabilities by enlarging its feasible solution space. In other words, tools break the “invisible leash” of a fixed model, unlocking new problem-solving strategies beyond the model’s built-in knowledge. The authors also introduce Advantage Shaping Policy Optimization (ASPO), an RL algorithm that gently guides an agent to use tools earlier and more effectively without destabilizing training. Experiments on math benchmarks show a TIR-enhanced 8B model decisively outperforming its tool-free counterpart, even on abstract problems requiring insight, not just computation. The results offer a principled explanation for how and why tool-use makes LLMs more powerful.
Memento: Fine-tuning LLM Agents without Fine-tuning LLMs (paper/code)
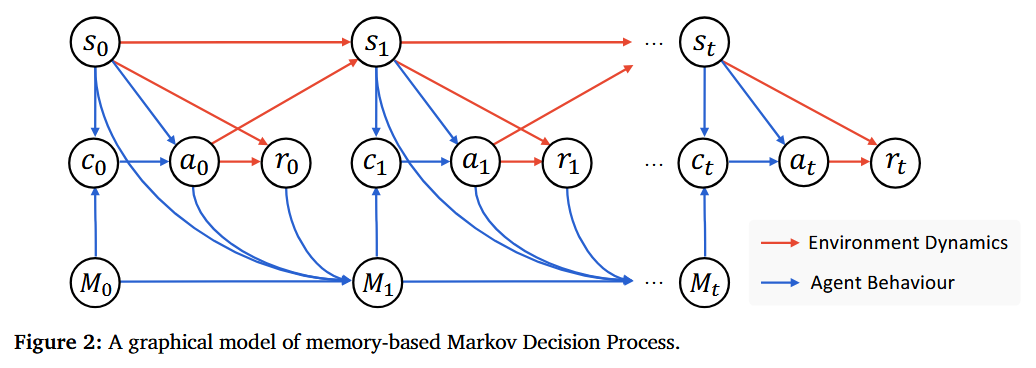
Can an AI agent learn from experience continually, without updating its underlying LLM weights? Memento proposes a memory-augmented, fine-tune-free approach to adapt LLM-based agents. The key idea is to formalize the agent’s decision process as a Memory-augmented MDP, where past interactions are stored in an episodic memory and a separate neural policy learns to retrieve and rewrite these memories over time. Instead of backpropagating into the LLM, the agent improves via online reinforcement learning on the memory (editing or recalling relevant cases when facing new problems). In a “deep research” evaluation setting, Memento’s case-based memory added +5–10% absolute performance on novel tasks and outperformed state-of-the-art fine-tuning methods. Notably, it achieved top rankings on the GAIA agent benchmark (87.9% Pass@3) and DeepResearcher science QA, all through low-cost memory updates rather than expensive model retraining. This work points toward LLM agents that learn continually on the fly, expanding skills in real-time without ever altering the base model parameters.
LLM-based Agentic Reasoning Frameworks: A Survey (paper)
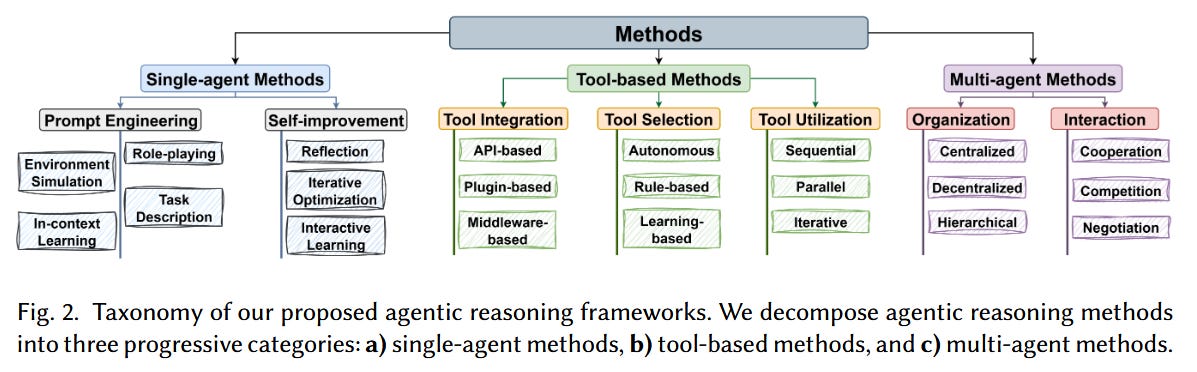
This extensive 51-page survey provides a panoramic review of how LLMs are being used as agents across different methodologies and applications. The authors propose a unified formal language to describe agentic reasoning and use it to categorize approaches into three groups: single-agent, tool-integrated, and multi-agent frameworks. They examine how each framework type “steers” the reasoning process (e.g. an agent working alone vs. with external tools vs. in collaboration/competition with other agents) and highlight their respective strengths and challenges. The survey also explores key application scenarios where LLM-driven agents are making waves – from scientific discovery and healthcare, to software engineering automation, social simulation, and economics. Along the way, it discusses common evaluation strategies and open issues (like ensuring reliability, interpretability, and efficiency in these systems). For anyone looking to understand the emerging LLM agent landscape, this survey is a valuable roadmap connecting methods to real-world use cases.
Jet-Nemotron: Efficient Language Model with Post Neural Architecture Search (paper)
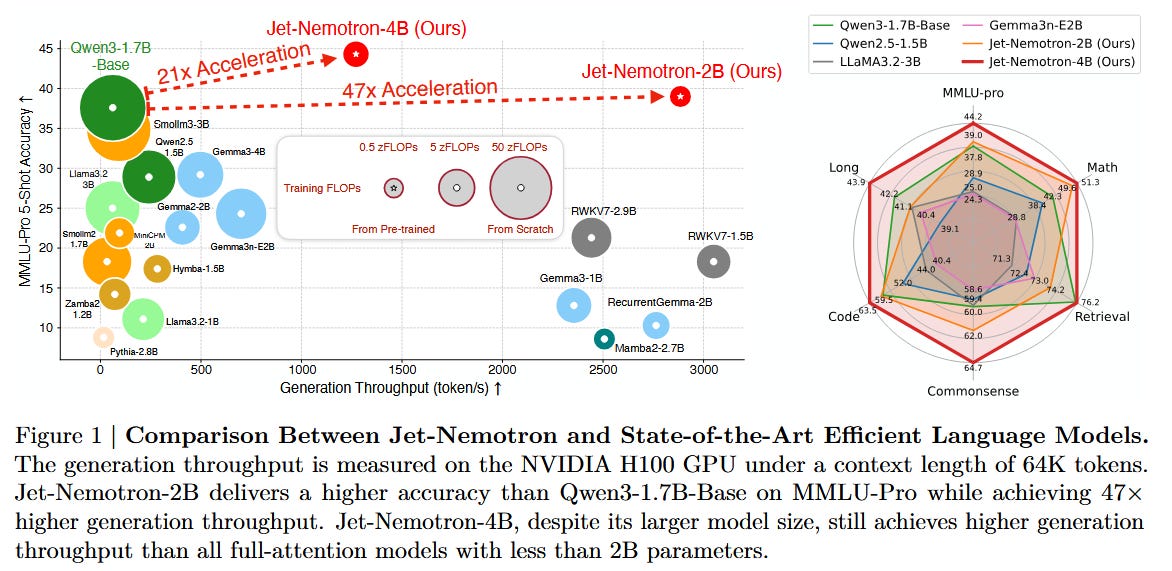
Figure: NVIDIA’s Jet-Nemotron achieves up to 53× generation throughput by replacing costly attention layers, while matching or surpassing the accuracy of comparable models. Jet-Nemotron is a new family of language models that reaches transformer-level accuracy with a fraction of the compute. Instead of designing a model from scratch, the authors start with a strong pretrained model and retrofit its architecture for efficiency using PostNAS (Post-training Neural Architecture Search). They freeze the original model’s MLP weights and search for a faster attention architecture: deciding which full-attention layers can be removed or replaced with a lighter mechanism (introducing a new linear attention module called JetBlock). The Jet-Nemotron-2B model, for example, runs over 50× faster in text generation on long inputs, yet performs on par or better than larger models like Qwen3 (1.7B) and Llama3.2 across a broad benchmark suite. It even outperforms recent Mixture-of-Experts transformers (DeepSeek-V3, Moonlight) on knowledge tests despite using far fewer active parameters. By demonstrating huge speedups without sacrificing accuracy, Jet-Nemotron points toward a new paradigm of optimizing LLMs after pretraining for deployment efficiency.
A Survey on Large Language Model Benchmarks (paper)

With the explosion of LLMs, we’ve also seen an explosion of benchmarks – this survey catalogs 283 benchmarks and provides a desperately needed map of the evaluation landscape. It organizes these benchmarks into three categories: general capability benchmarks (testing core language, knowledge, reasoning skills), domain-specific benchmarks (for areas like biomedical, legal, math, etc.), and target-specific benchmarks (focusing on qualities like truthfulness, bias, toxicity, robustness, and agent abilities). The survey highlights critical issues in current evaluations. For instance, many leaderboard gains are suspect due to data contamination (test answers leaking into training sets) and cultural or linguistic bias in tasks favoring certain models. There’s also a glaring lack of assessment for an LLM’s reasoning process (not just final answers) and how models perform in dynamic environments or interactive settings. To guide future benchmark design, the authors propose a framework emphasizing data cleanliness, fairness across languages/cultures, process-oriented evaluation (e.g. chain-of-thought correctness), and more realistic task setups. As LLMs rapidly advance, this survey will help researchers ensure evaluation methods keep pace and truly reflect real-world performance.
Deep Think with Confidence (DeepConf) (paper)
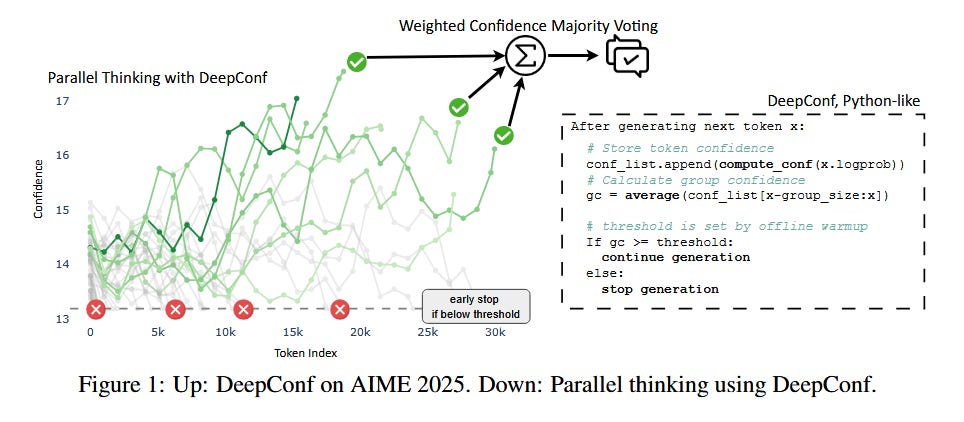
Current methods to boost LLM reasoning (like self-consistency ensembling) require generating many solutions, which is costly and hits diminishing returns. DeepConf takes a smarter approach: it lets the model generate solutions in parallel but uses the model’s own confidence signals to filter out bad reasoning paths early. Essentially, the model “thinks” broadly but prunes its thought branches as soon as it detects they’re likely wrong – much like a human solver discarding a dubious approach mid-way. This simple test-time framework dramatically improves both accuracy and efficiency. On the very challenging AIME 2025 math benchmark, DeepConf with 512 parallel solutions achieved a 99.9% accuracy, while cutting the total generated tokens by 84.7% compared to naive self-consistency. It requires no extra training or fine-tuning – it’s an inference-time technique that can wrap around any model and any prompt. By leveraging internal likelihood estimates (e.g. log-probabilities) to decide which partial solutions to abandon, DeepConf yields a “best of both worlds”: higher reasoning accuracy and less compute wasted on clearly wrong paths. This approach offers a promising route to make LLM reasoning both smarter and more computationally efficient.
aiXiv: A Next-Generation Open Access Ecosystem for AI-Generated Research (paper)
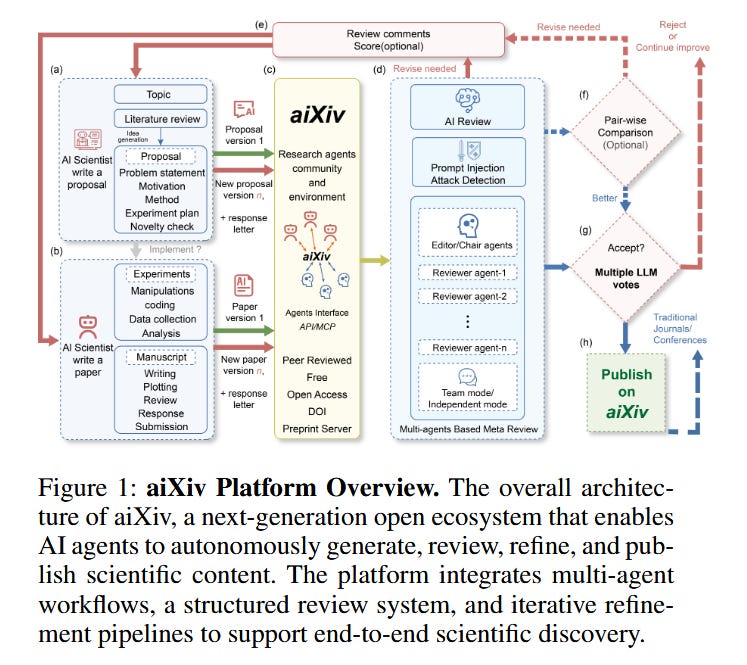
As AI systems begin to autonomously generate scientific papers and discoveries, where do we publish their work? aiXiv is proposed as a new platform – inspired by arXiv – tailored for research generated by AI scientists. It introduces a multi-agent peer review architecture where AI-authored submissions are reviewed and iteratively refined through collaboration between human scientists and AI reviewer agents. Unlike traditional journals and preprint servers, aiXiv is built to scale with a high volume of AI-generated content while maintaining quality control. It implements rigorous review criteria (using both automated checks and human/AI feedback) to filter out errors or low-quality material, addressing the concern that current venues are not equipped to vet AI-generated research. Early experiments show that iterative rounds of feedback on aiXiv significantly improved the quality of AI-written research proposals and papers. The platform also provides APIs and integration protocols (MCP interfaces) so that a heterogeneous mix of human and AI “scientists” can seamlessly participate in the research life cycle. By laying this groundwork, aiXiv aims to accelerate scientific discovery in an era where not just human researchers, but increasingly AI agents, are generating novel hypotheses, experiments, and results.
MCP-Universe: Benchmarking LLMs with Real-World Tool Use (paper)
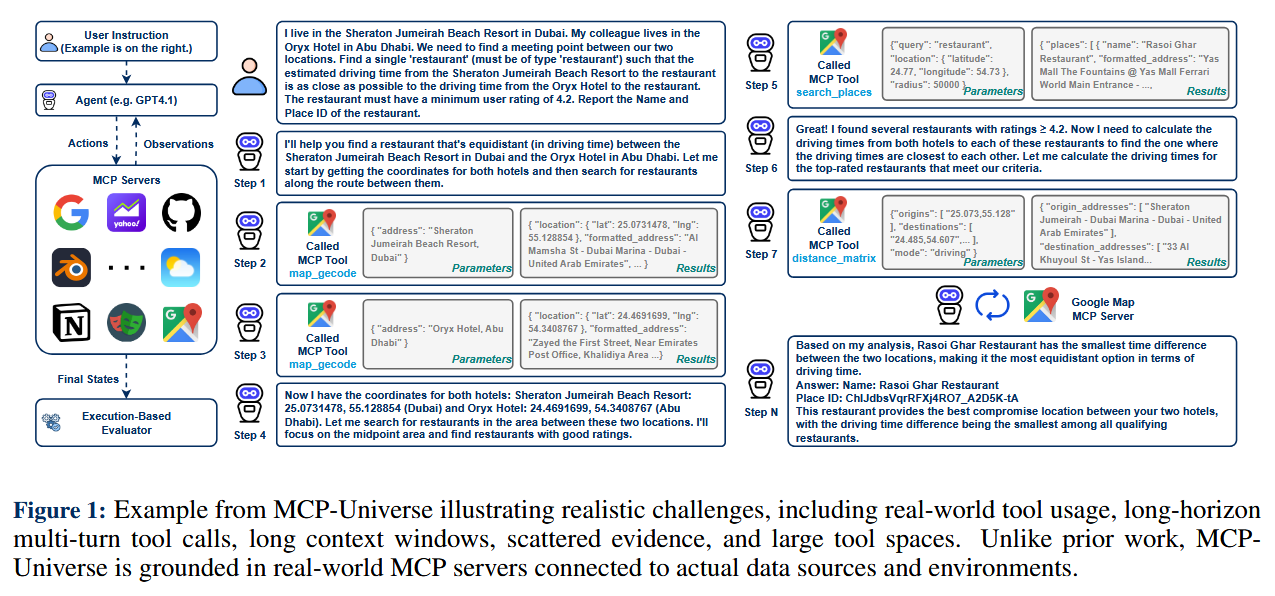
In MCP-Universe, LLM-based agents must interact with real apps and data (maps, code repos, web browsers, etc.) to accomplish tasks – revealing challenges in long-horizon planning and unfamiliar tool use. Developed by Salesforce researchers, MCP-Universe is the first comprehensive benchmark to evaluate large language model agents on realistic, end-to-end tasks that require using external tools via the Model Context Protocol (MCP). It spans 6 domains with 11 actual MCP servers – from Location Navigation (querying map APIs) and Repository Management (managing GitHub projects), to Financial Analysis (using spreadsheets), 3D Designing (CAD tools), Browser Automation, and Web Searching. The benchmark doesn’t simulate these tools; it connects to real services and data sources, requiring agents to handle authentic complexity and even temporal changes (e.g. retrieving current information). To score agents, MCP-Universe uses execution-based evaluators: it checks not only final answers but also format compliance, correctness of each operation (static eval), and even pulls live ground-truth data for time-sensitive queries (dynamic eval). The findings are humbling: even the best proprietary models struggle. GPT-5 (Vision model) topped the leaderboard at only 43.7% success, and other advanced models like Grok-4 and Claude-4.0 were near 30%. Long conversations quickly blow up context windows, and agents often falter with unknown tools – lacking precise knowledge of certain API calls or interfaces. Surprisingly, a sophisticated enterprise agent (Cursor) performed no better than a standard ReAct-based agent, indicating ample room for improvement in agent architectures. By open-sourcing the entire evaluation framework (with a slick UI and integration guides), MCP-Universe provides a challenging playground to drive the next generation of truly autonomous LLM agents grounded in real-world environments.
Great curation!