
10 Papers You Should Know About
Stay ahead of the curve with LLM Watch
Welcome, Watcher! This week in LLM Watch:
NVIDIA’s AI-Q blueprint shows how businesses can unlock their private troves of emails, documents, and databases with open-source AI agents.
ByteDance’s Seed-Prover AI achieved a milestone long thought decades away: solving 5 out of 6 problems on the 2025 International Mathematical Olympiad.
Self-Questioning Language Models (SQLM) – an innovative self-play training method where an LLM generates its own questions and attempts to answer them.
Don’t forget to subscribe to never miss an update again.
Quick Glossary (for the uninitiated)
- System prompt: The initial instructions that tell an AI model how to behave throughout a conversation - like giving a new employee their job description
- Context engineering: The art of structuring information and instructions to get better AI outputs (evolved from "prompt engineering")
- Planning tools: Functions that help AI break down complex tasks into steps - sometimes just forcing it to think before acting
- Sub-agents: Specialized AI instances spawned to handle specific subtasks, like hiring contractors for parts of a project
- No-op: A programming term for an operation that does nothing - like a "think about it" button that just makes you pause
1. AI-Q: Open-Source Blueprint to Chat with Enterprise Data
Watching: AI-Q (blog)
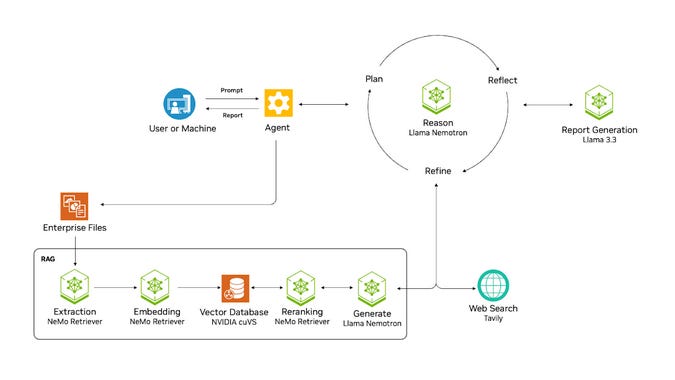
NVIDIA’s AI-Q blueprint integrates multimodal data ingestion, retrieval-augmented generation, and agentic reasoning to deliver enterprise-grade answers in a secure, high-speed pipeline. The architecture features components like NeMo Retriever for accelerated data extraction and embedding, a vector database (cuVS) for at-scale knowledge storage, and a Llama-based “Nemotron” reasoning module that iteratively plans, reflects, and refines outputs.
What problem does it solve? Modern enterprises drown in data – from emails and PDFs to chat logs and databases – much of which goes unused. Employees struggle to find answers buried in these silos, leading to lost productivity and untapped institutional knowledge. The challenge is to securely leverage internal data (often proprietary or sensitive) with AI, so workers can “chat” with their enterprise’s information and get accurate, fast answers without exposing data to third-party services.
How does it solve the problem? NVIDIA’s AI-Q provides a fully open-source blueprint for building an Artificial General Agent (AGA) that connects to private enterprise data. It defines a developer-friendly workflow with three building blocks: (1) NeMo Retriever microservices for multimodal data extraction and embedding (text, PDFs, tables, images, etc.) at up to 15× faster speeds via GPU acceleration; (2) a high-performance vector database (NVIDIA cuVS) to index and store embeddings for retrieval; and (3) the NeMo Agent toolkit, featuring a Llama-based reasoning model (“Llama Nemotron”) that can dynamically toggle between fast responses and an “extended thinking” mode. In extended mode, the agent can invoke tools like web search (via Tavily) or code execution, iteratively plan, reason, and refine its answers. The blueprint shows how an agent ingests up-to-date enterprise data, uses Retrieval-Augmented Generation (RAG) to ground responses in facts, and employs chain-of-thought reasoning to produce coherent, detailed answers – all integrated with enterprise authentication, security, and monitoring.
What are the key findings? AI-Q’s reference implementation – an AI Research Assistant that digests hours of research papers in minutes – demonstrates the blueprint’s effectiveness. Another example, a Biomedical Research Agent, was built to rapidly synthesize medical studies for pharma R&D. The system consistently delivers accurate, source-grounded answers across domains like IT, finance, and healthcare, thanks to its combination of up-to-date retrieval and agent reasoning. Notably, NVIDIA reports 5× faster inference from their optimized Llama models (dubbed “Nemotron”) which can selectively dial down reasoning for simple queries or ramp up for complex ones. By maintaining a local “memory file” of important facts, the agent avoids forgetting context over long sessions. Early adopters found that AI-Q drastically reduces the time employees spend searching for information, while keeping data on-premises. The open blueprint has also sparked community contributions, extending it to new data sources and custom tools.
Why does it matter? AI-Q moves enterprises from passive data hoards to interactive knowledge bases. Crucially, it’s fully open-source – lowering the barrier for companies to deploy their own ChatGPT-like assistant without handing data to a third party. This empowers organizations to harness LLMs for internal use cases (like answering employee IT questions, summarizing legal documents, or debugging code) with transparency and customization. By demonstrating that a thoughtfully designed pipeline (multimodal ingestion + RAG + agent reasoning) can achieve robust results with modest resources, NVIDIA’s blueprint could accelerate adoption of AI behind the firewall.
2. Seed-Prover: Deep and Broad Reasoning for Automated Theorem Proving
Watching: Seed-Prover (paper)
What problem does it solve? Solving advanced mathematics – especially writing full formal proofs for contest-level problems – has remained a “holy grail” for AI. While large language models can handle many textbook math questions, they struggle with Olympiad problems requiring creative, multi-step proofs and rigorous verification. The challenge is twofold: searching the enormous proof space (many possible lemmas and strategies) and ensuring the solution is correct (something traditional LLM outputs can’t guarantee). Prior systems could only prove a small fraction of contest problems, often via brute-force search or heavy hand-holding, highlighting the gap between superficial reasoning and the deep logic needed for theorem proving.
How does it solve the problem? Seed-Prover (from ByteDance’s Seed AI4Math team) marries Large Language Model intuition with formal proof verification in a closed-loop. During training, it uses the Lean theorem prover as a sandbox: the model proposes proof steps which are immediately checked for correctness, giving a clear success/failure signal (unlike vague “right or wrong” feedback in natural language). The model learns a lemma-focused strategy: instead of jumping straight to the final answer, it generates intermediate lemmas (sub-problems) and proves those, gradually building up to the full solution. At inference (problem-solving) time, Seed-Prover employs three complementary strategies to explore proofs both deep (following a long chain of reasoning) and broad (trying alternative approaches). One strategy, for instance, allows the model to refine or restart its proof based on Lean’s feedback (if a line of reasoning fails, it backtracks and tries a different approach), while another strategy leverages a specialized geometry solver (Seed-Geometry) for tackling challenging geometry problems. By iteratively generating, verifying, and adjusting proof steps, the system essentially performs a guided search through the space of possible proofs – harnessing the creativity of LLMs but anchored by the strict rules of formal math.
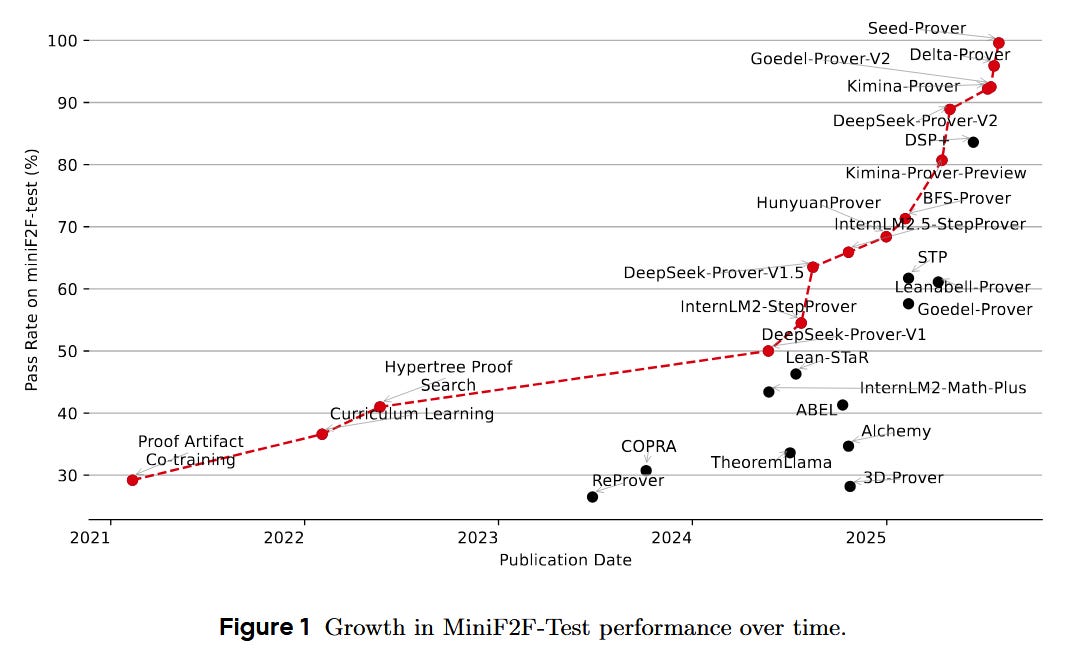
What are the key findings? Seed-Prover achieved a breakthrough result in automated math: it successfully found formal proofs for 5 out of 6 problems from the IMO 2025 competition – a feat unparalleled by previous AI systems. During the live contest, the system fully solved 4 problems within the allotted time (and solved the fifth shortly after). These included problems in geometry, number theory, combinatorics, and algebra – domains that demand diverse techniques. Overall, Seed-Prover can now prove 78% of past IMO problems when formalized, and it set new state-of-the-art scores on benchmarks like MiniF2F and PutnamBench, dramatically outperforming prior models. Qualitatively, the model’s proofs often mirrored human-like approaches, discovering key lemmas and insights (and in one case even finding a novel solution variant for a problem). The use of Lean verification meant that every step of the proof was checked – significantly reducing errors or “hallucinations” in the reasoning. This rigorous feedback loop was crucial: a version of the model trained without formal verification signals could generate plausible-looking proofs that were actually wrong. In contrast, Seed-Prover’s proofs are guaranteed correct by construction, instilling new confidence in AI-driven mathematics.
Why does it matter? Mathematics has long been a litmus test for intelligence, since it requires abstract thinking, creativity, and flawless logic – far beyond regurgitating patterns from data. By effectively bridging LLMs with formal methods, Seed-Prover shows a viable path to overcoming the reliability issues of “black-box” neural reasoning. The system’s lemma-by-lemma approach also makes its reasoning more interpretable (each proved lemma is a verifiable milestone), pointing toward AI that not only reaches correct answers but can explain and justify them step by step. Practically, these techniques could transform fields like software verification, engineering, and pure math research: AI assistants may soon help discover new proofs or check the correctness of others’ work. Moreover, the success on IMO problems – often seen as requiring true ingenuity – is an uplifting sign that AI might eventually tackle open mathematical conjectures. Seed-Prover underscores the power of hybrid systems that combine the strengths of neural networks (flexible reasoning) with symbolic systems (exact verification), and it pushes us one step closer to AI that can “think” through the toughest problems in a human-like yet superhuman way.
3. Self-Questioning Language Models
Watching: Self-Questioning LMs (paper)
What problem does it solve? Today’s LLMs typically learn from fixed datasets curated by humans, which limits their growth. Once trained, they passively rely on user prompts or additional fine-tuning – they don’t actively ask new questions on their own. In contrast, humans (and especially researchers) often learn by self-questioning: we pose ourselves problems, attempt solutions, identify gaps, and try again. The question here: Can an AI improve its reasoning abilities by generating and answering its own questions? If so, an LLM could continuously sharpen itself without needing constant human-provided training data. This would also help address the “data bottleneck” – high-quality instruction tuning data is expensive to obtain – and could mitigate issues like models drifting when fine-tuned only on user-facing style rather than underlying problem-solving skills.
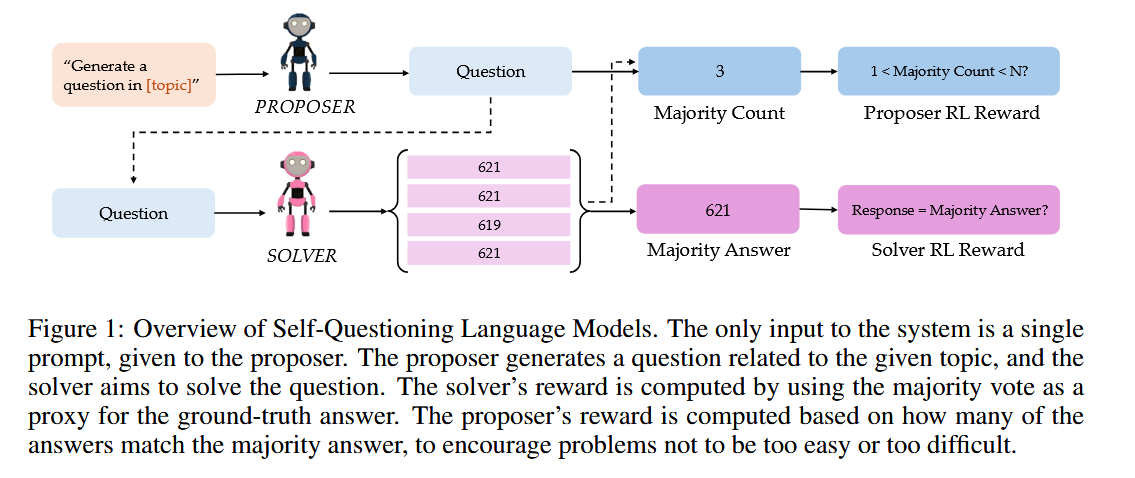
How does it solve the problem? The authors propose an asymmetric self-play framework called Self-Questioning LMs (SQLM). They create two roles from a single pre-trained model: a “Proposer” and a “Solver.” The Proposer takes a general topic or domain (for example, “three-digit multiplication” or “algebra word problems”) and generates a question that an expert in that domain should be able to solve. The Solver then tries to answer the Proposer’s question. Because these roles are played by the same underlying model, the system essentially tasks itself with challenges. The interaction is driven by reinforcement learning: if the Proposer’s question is too easy or too hard, it gets a low reward – it should pose questions that are solvable but non-trivial. The Solver, on the other hand, is rewarded for producing correct answers, but since there’s no external answer key, correctness is gauged via self-consistency (e.g. majority voting among multiple attempts). For coding tasks, the Proposer generates unit tests as “questions,” and the Solver writes code that must pass those tests. Over many rounds of this self-play, the model adapts: the Proposer learns to craft more and more interesting, challenging questions (because trivial ones yield no reward), and the Solver correspondingly improves by tackling them. The key is that no external data or human evaluation is needed – the model’s own ability to solve or not solve a question provides the learning signal.
What are the key findings? Using this method, a base language model was able to significantly improve its performance on multiple reasoning benchmarks without any new human-labeled data. For instance, starting from a model already good at math, the self-questioning training boosted its accuracy on 3-digit multiplication and algebra problems (from the OMEGA benchmark) beyond the original capabilities – solely through the model’s newly acquired habit of proposing tricky problems to itself and solving them. On Codeforces programming challenges, the model similarly became better at generating correct solutions after iteratively testing itself with unit-test questions. An interesting qualitative observation: as training progressed, the Proposer began generating questions that curriculum-like increased in difficulty, mirroring how a human teacher might start with simpler tasks and ramp up to harder ones as the student improves. This automatic curriculum happened without explicit scheduling – it emerged from the reward setup (easy questions quickly saturate the Solver’s performance, so to get higher reward the Proposer had to make the questions harder over time). The study also found that the model, through self-play, discovered gaps in its own knowledge and then filled them: for example, if it was weak on a certain pattern of word problem, it would eventually generate those cases and learn from them. Overall, the self-trained model matched or surpassed the performance of models fine-tuned on thousands of human-written prompts, highlighting that a sufficiently intelligent model can be its own best teacher under the right setup.
Why does it matter? Self-Questioning LMs hint at a future where AI systems can continuously improve themselves by creating their own training curriculum. This could drastically reduce the need for large-scale human annotation when refining models for complex reasoning tasks, making the improvement process more scalable and autonomous. It’s also a step towards addressing the alignment problem: a model that learns through self-posed queries could potentially identify flaws in its reasoning or harmful responses by “thinking out loud” and then correcting itself, all internally. In reinforcement learning terms, this is like having the model generate its own environment for skill acquisition – a concept that has led to huge breakthroughs in games (e.g. AlphaGo’s self-play). Applying it to general reasoning is novel and powerful. Moreover, this approach opens up a new paradigm for LLM training beyond next-token prediction: using the model’s internal consistency (can it solve what it asks?) as a training signal. It could inspire other asymmetric self-play setups (imagine a “critic” model that generates tricky corner cases for a “debater” model to tackle, etc.). Ultimately, Self-Questioning LMs represent a move toward autonomous research agents – AI that not only solves problems but figures out which problems to practice on to become smarter. And perhaps one day, such agents will pose and solve scientific questions that humans haven’t even thought to ask.
Papers of the Week:
CoT-Self-Instruct: A method to generate synthetic training data by having LLMs produce reasoning chains first (via chain-of-thought) and then new prompts of comparable difficulty, yielding data that outperforms human-written prompts for both reasoning (MATH, AIME) and instruction-following tasks.
Cognitive Kernel-Pro: An open-source, modular agent framework (“CK-Pro”) that enables training and evaluation of sophisticated AI agents without proprietary APIs. It curates high-quality trajectories & queries across web, file, code, and reasoning domains, and introduces test-time reflection and voting to improve agent robustness. A 8B foundation model trained with this outperforms prior open agents like WebDancer, setting a new state-of-art for “free” AI agents.
TURA: Baidu’s production-ready framework that combines retrieval-augmented generation with tool use for next-gen search engines. TURA can parse complex queries into sub-tasks, use dynamic tools/APIs (for real-time info like flight tickets or database lookups), and execute a directed acyclic graph (DAG) of actions to return answers. Serving tens of millions of users in production, it bridges static web search with live data by integrating an agent executor into the search pipeline.
Agent Lightning: A general framework for applying RL fine-tuning to arbitrary LLM-based agents. Agent Lightning cleanly decouples agent decision-making from training: it treats an agent’s action trajectory as a Markov Decision Process and introduces a unified data interface plus a hierarchical RL algorithm (LightningRL) for credit assignment. This allows one to plug in agents built with LangChain, AutoGen, etc., and improve them via RL without custom hacks. Experiments on text-to-SQL, retrieval, and tool-use tasks show continuous performance gains, demonstrating practical RLHF-for-agents across diverse environments.
CoAct-1: A new agent that can not only click GUIs but also write and run code to accomplish tasks. CoAct-1 uses a two-agent team: a GUI operator and a Programmer, orchestrated by a controller that delegates sub-tasks to one or the other. By generating Python/Bash scripts for suitable tasks (e.g. file management, data processing) instead of purely GUI macro actions, CoAct-1 achieved a new state-of-the-art 60.8% success on the challenging OSWorld benchmark (vs ~50% for prior GUI-only agents) and completed tasks ~33% faster by avoiding repetitive UI navigation. This showcases the power of combining tool-use (coding) with traditional UI manipulation in interactive agents.
Seed Diffusion: Introduces a 1.3B-param diffusion-based language model that generates text via discrete diffusion steps instead of left-to-right decoding. Seed Diffusion Preview achieves an astonishing 2,146 tokens/second generation speed on GPU clusters by producing multiple tokens in parallel. Aimed at code generation, it maintains competitive code output quality while far surpassing transformer models (and even prior diffusion LMs like Mercury and Gemini) in throughput. This work puts diffusion models on the map as a promising alternative for ultra-fast LLM inference.
Beyond the Trade-off: Proposes a clever technique to improve an LLM’s adherence to instructions without external feedback. The authors identify a trade-off: models tuned heavily for chain-of-thought reasoning can become less followable. They leverage the model’s own internal signals (e.g. likeliness of following instructions in its reasoning trace) as a self-supervised reward. By applying RL on these signals, the model significantly improved its instruction-following ability while retaining its reasoning prowess. In short, it aligned itself better to user prompts without sacrificing problem-solving, all through self-generated rewards – an approach that sidesteps the need for human or higher-model evaluators.